- CS 410 Text Information Systems
- CS 425 Distributed Systems
- CS 427 Software Engineering
CS 410 Text Information Systems
Goals and Objectives
- Explain the basic ideas of Logistic Regression, K-Nearest Neighbors (k-NN), and how K-NN works.
- Explain how to evaluate categorization results.
- Explain the tasks of opinion mining and sentiment analysis and why they are important tasks from an application perspective.
- Explain how sentiment analysis can be done using text categorization techniques and why a straightforward application of regular text categorization techniques may not be adequate.
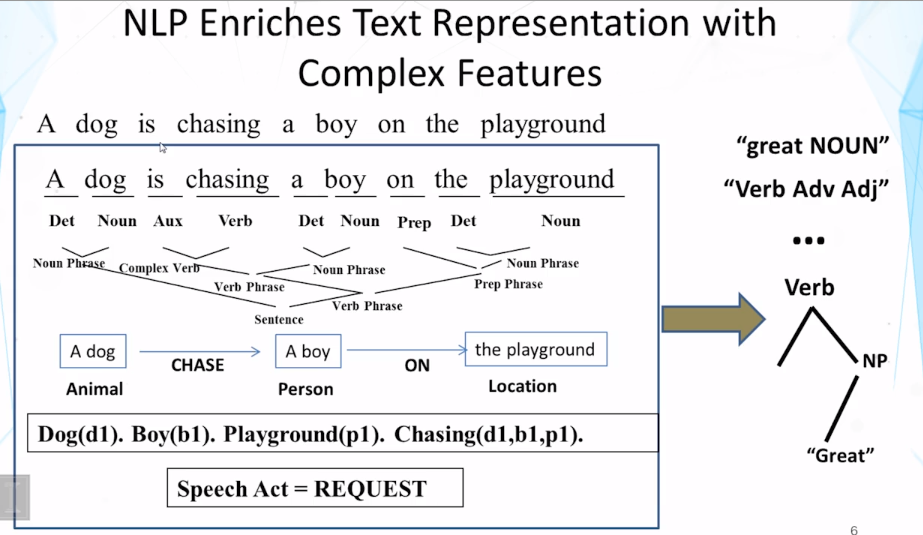
- Give examples of both simple and complex features that are used for characterizing text data and explain how NLP can enable complex features to be generated from text.
Guiding Questions
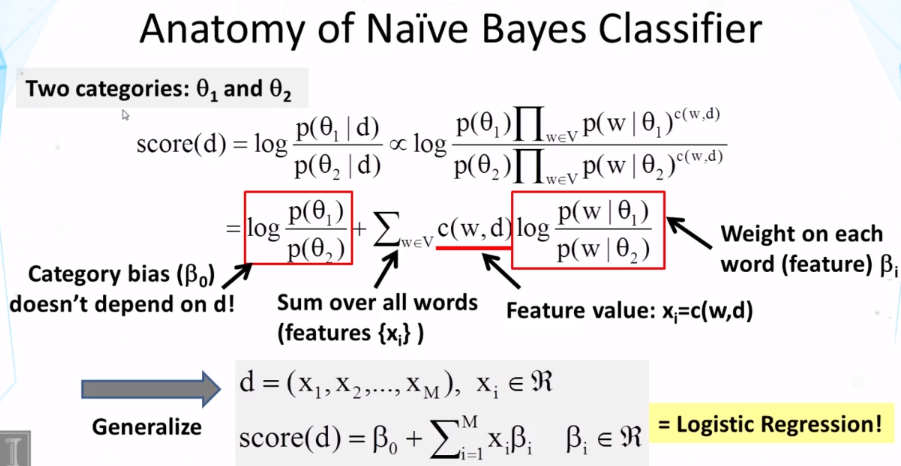
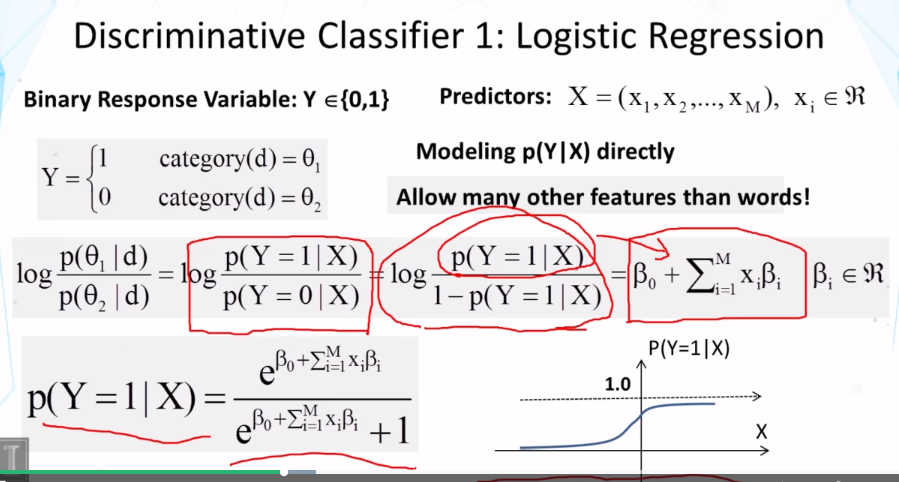
- What’s the general idea of the logistic regression classifier? How is it related to Naïve Bayes? Under what conditions would logistic regression cover Naïve Bayes as a special case for two-category categorization?
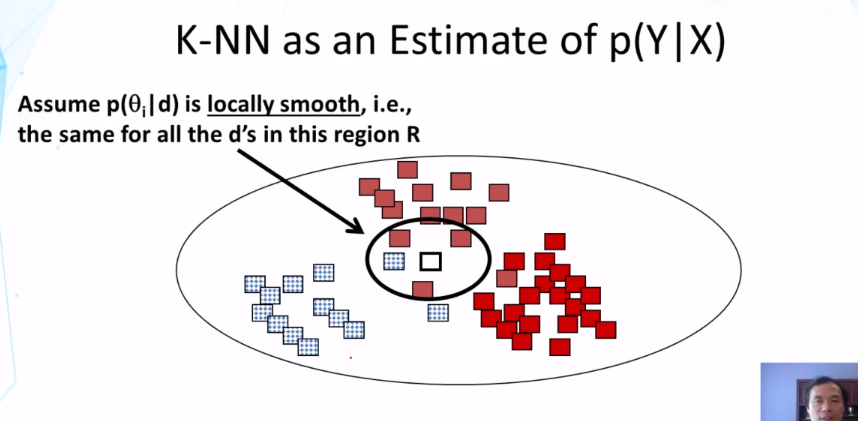
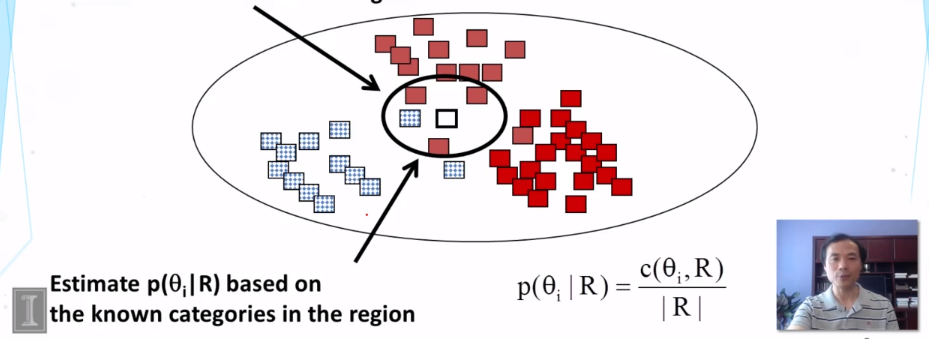
- What’s the general idea of the k-Nearest Neighbor classifier? How does it work?
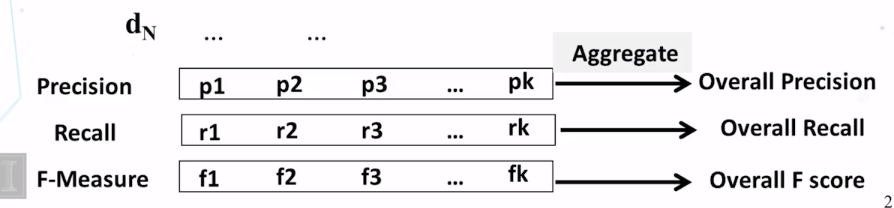
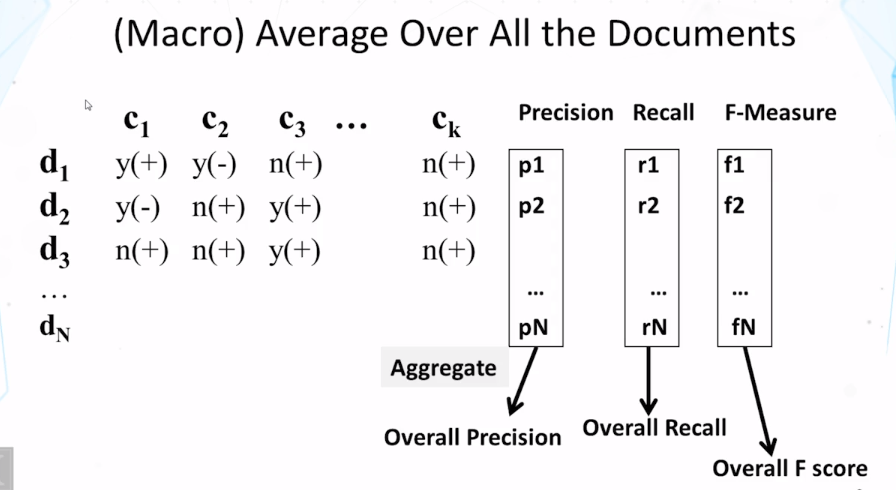
- How do we evaluate categorization results?
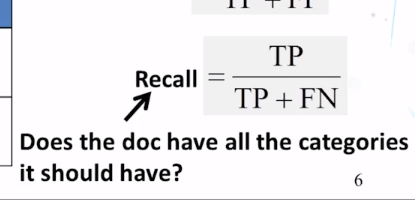
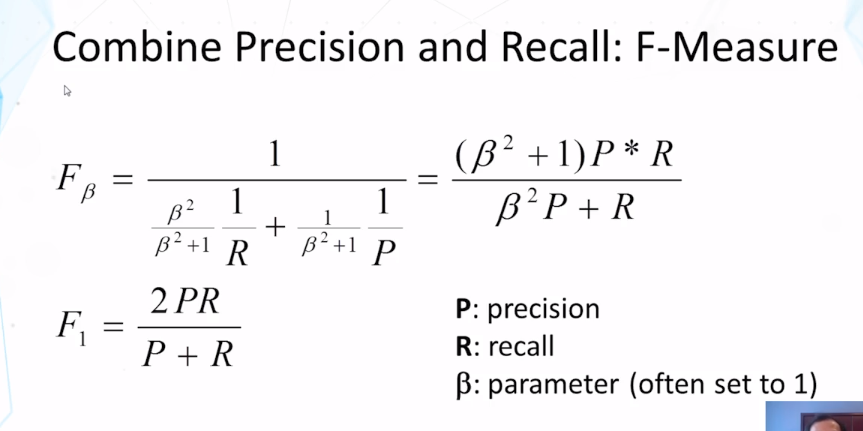
- How do we compute classification accuracy, precision, recall, and F score?
- Why is harmonic mean as used in F better than the arithmetic mean of precision and recall?
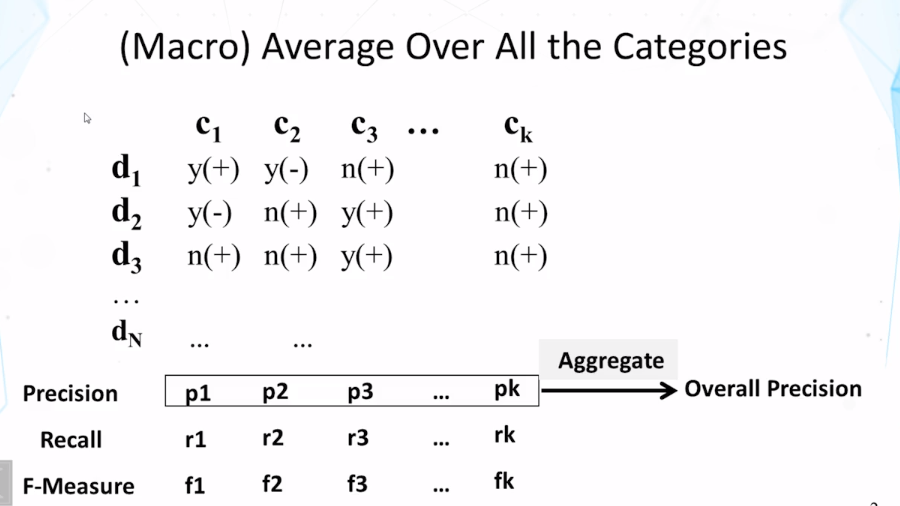
- What’s the difference between macro and micro averaging?
- Why is it sometimes interesting to frame a categorization problem as a ranking problem?
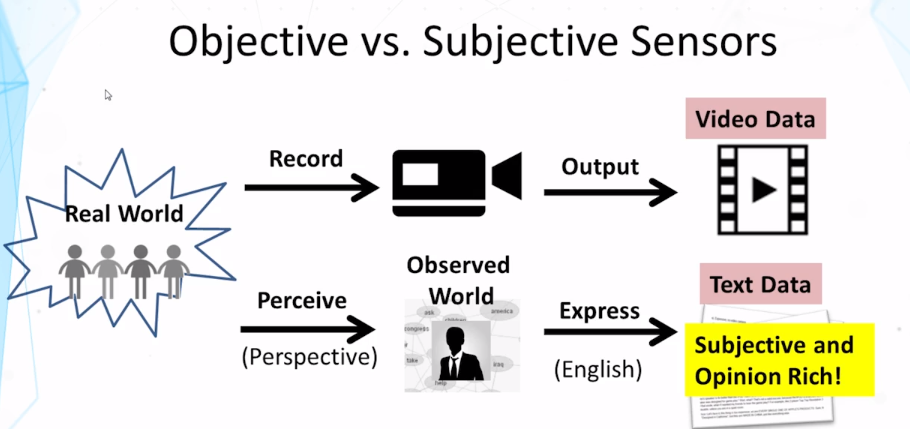
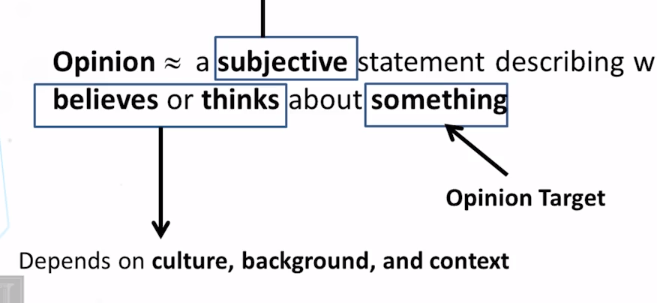
- What is an opinion? How is it different from a factual statement?
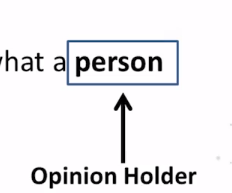
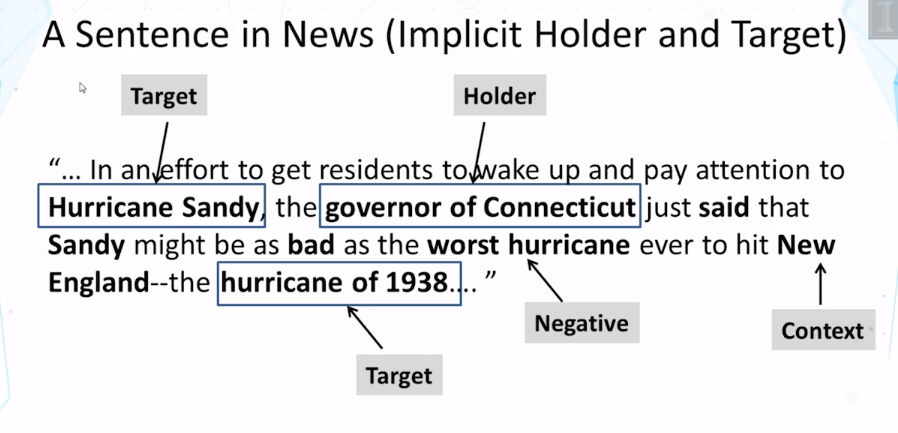
- What’s an opinion holder? What’s an opinion target?
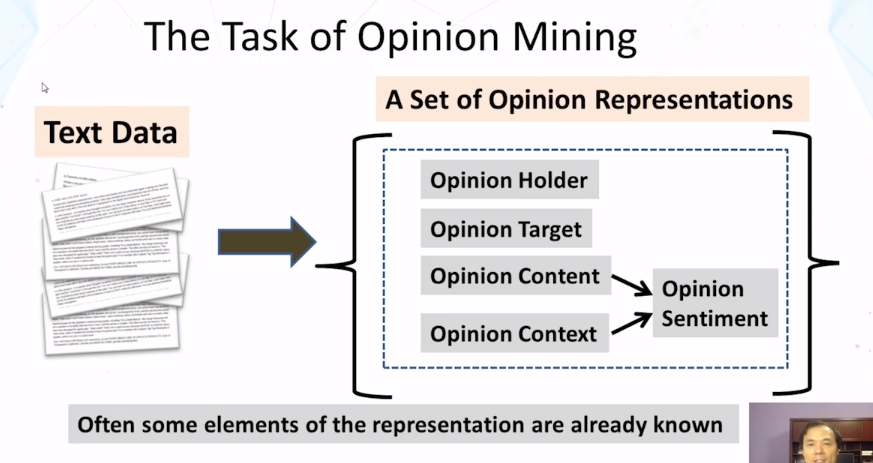
- What’s the goal of opinion mining?
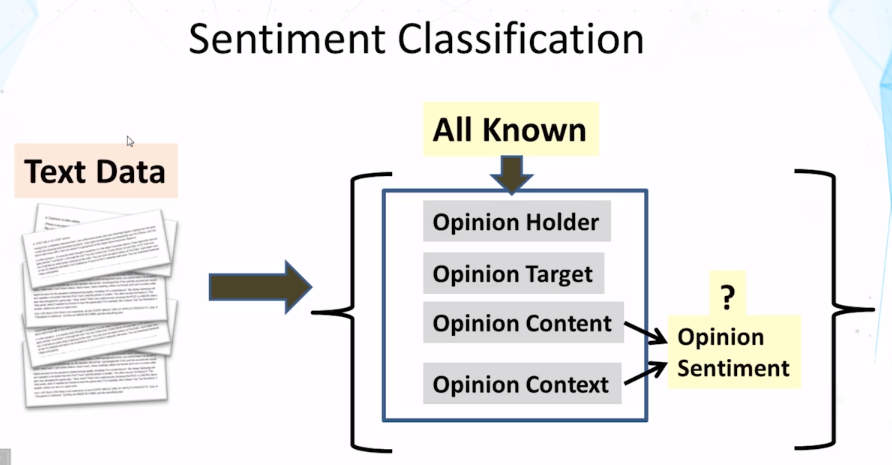
- What is sentiment analysis? How is it similar to and different from a text categorization task such as topic categorization?
- Why are unigram features generally insufficient for accurate sentiment classification?
- What’s the concern of using too many complex features such as frequent substructures of parse trees?
- What are some commonly used features to represent text data?
Additional Readings and Resources
- C. Zhai and S. Massung, Text Data Management and Analysis: A Practical Introduction to Information Retrieval and Text Mining. ACM and Morgan & Claypool Publishers, 2016. Chapters 15 & 18.
- Yang, Yiming. An Evaluation of Statistical Approaches to Text Categorization. Inf. Retr. 1, 1-2 (May 1999), 69-90. doi: 10.1023/A:1009982220290
- Bing Liu, Sentiment analysis and opinion mining. Morgan & Claypool Publishers, 2012.
- Bo Pang and Lillian Lee, Opinion mining and sentiment analysis, Foundations and Trends in Information Retrieval 2(1-2), pp. 1–135, 2008.
Key Phrases and Concepts
- Generative classifier vs. discriminative classifier
- Training data
- Logistic regression
- K-Nearest Neighbor classifier
- Classification accuracy, precision, recall, F measure, macro-averaging, and micro-averaging
- Opinion holder, opinion target, sentiment, and opinion representation
- Sentiment classification
- Features, n-grams, frequent patterns, and overfitting
Video Lecture Notes
11-1 Text Categorization
11-1-1 Discriminative Classifier Part 1



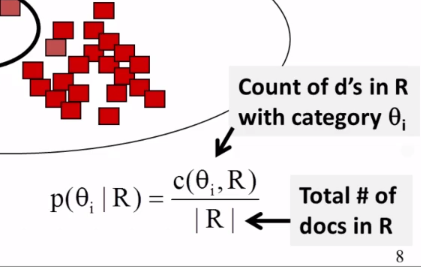
11-1-2 Discriminative Classifier Part 2
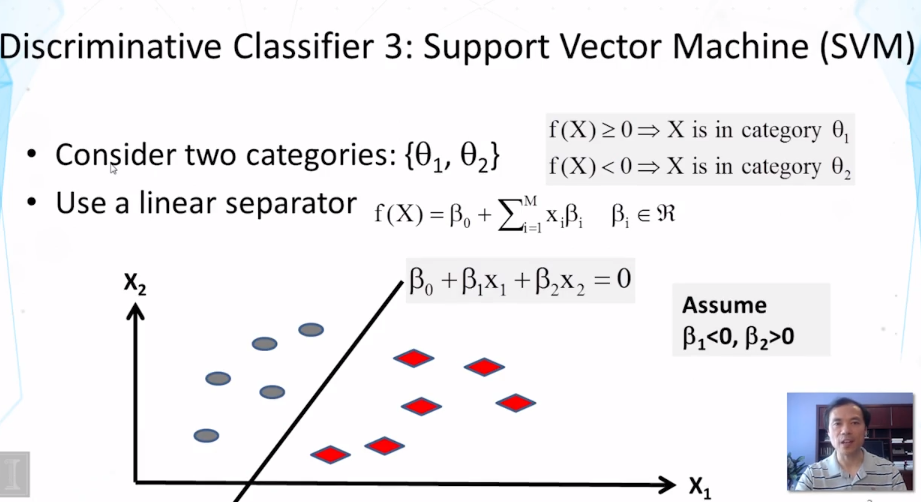
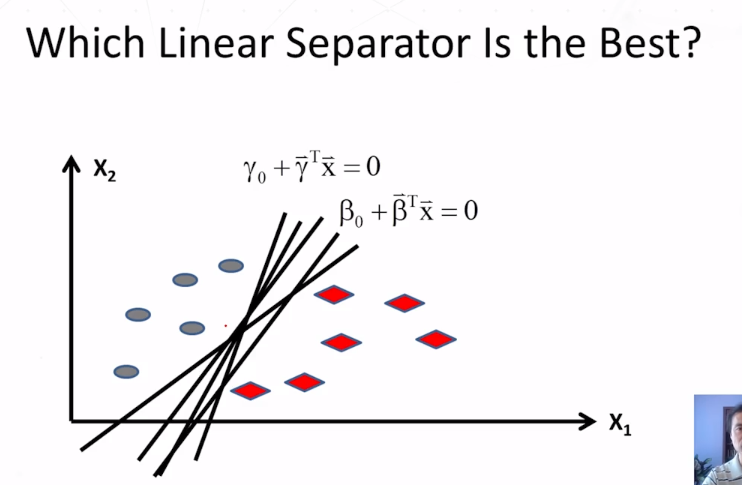
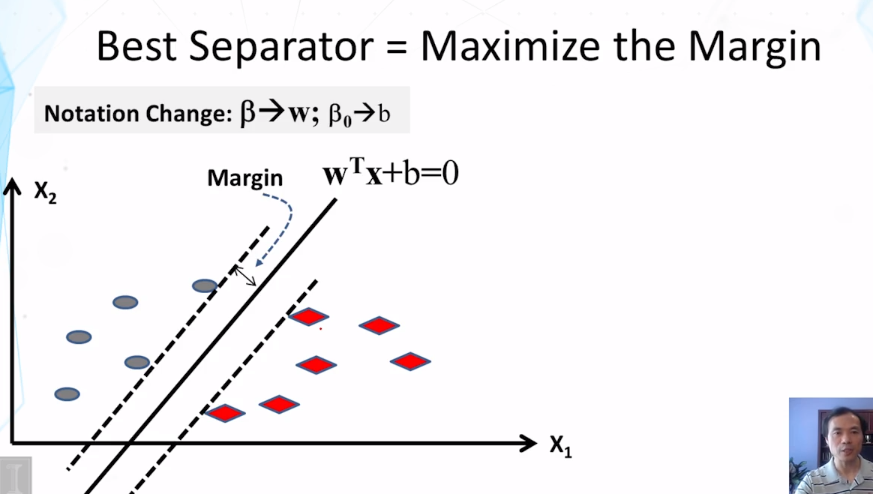
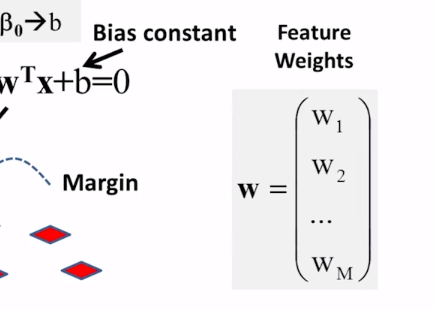
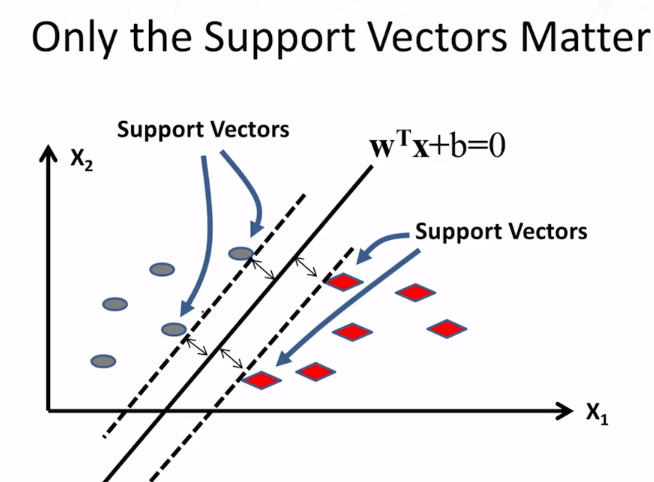
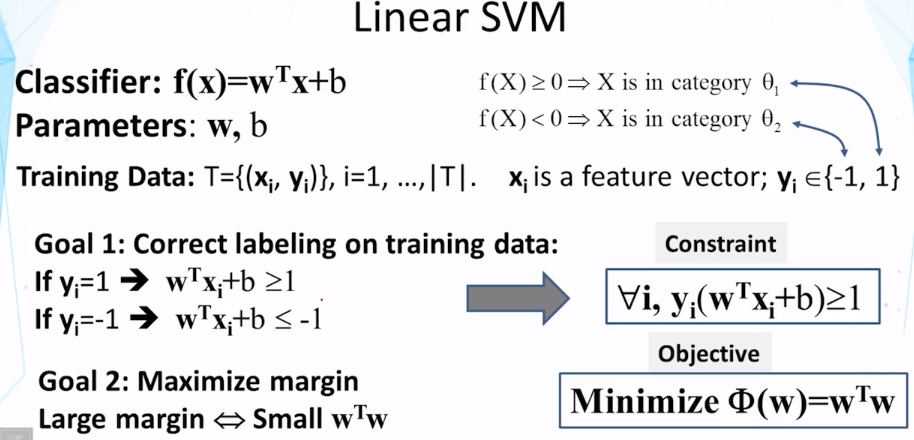







11-1-3 Evaluation Part 1




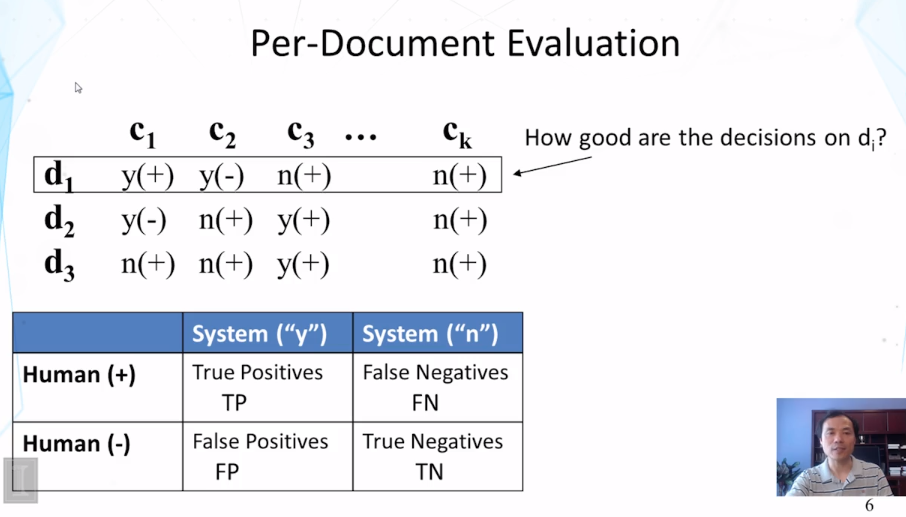


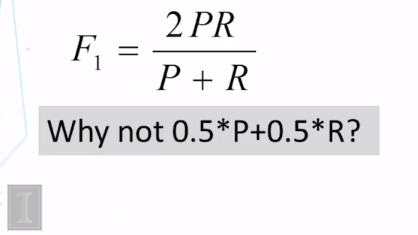

11-1-4 Evaluation Part 2



11-2 Opinion Mining and Sentiment Analysis
11-2-1 Motivation








11-2-2 Sentiment Classification






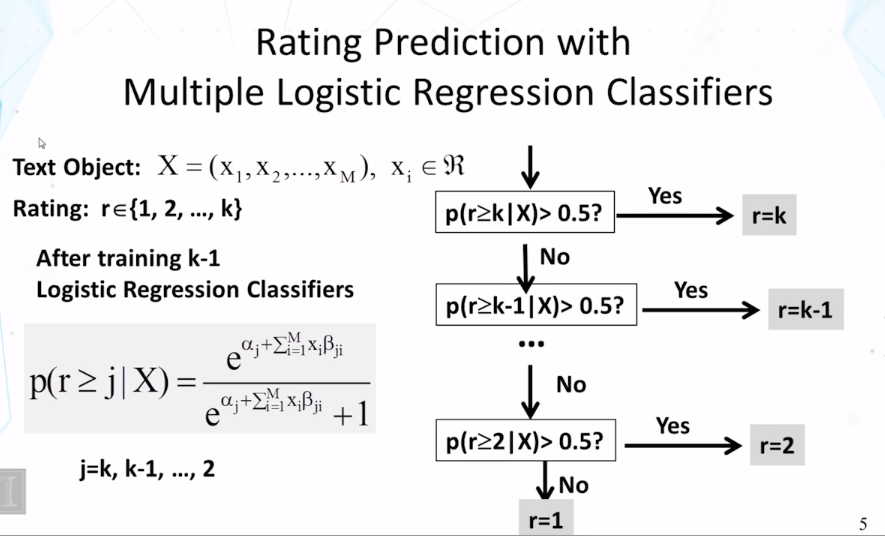
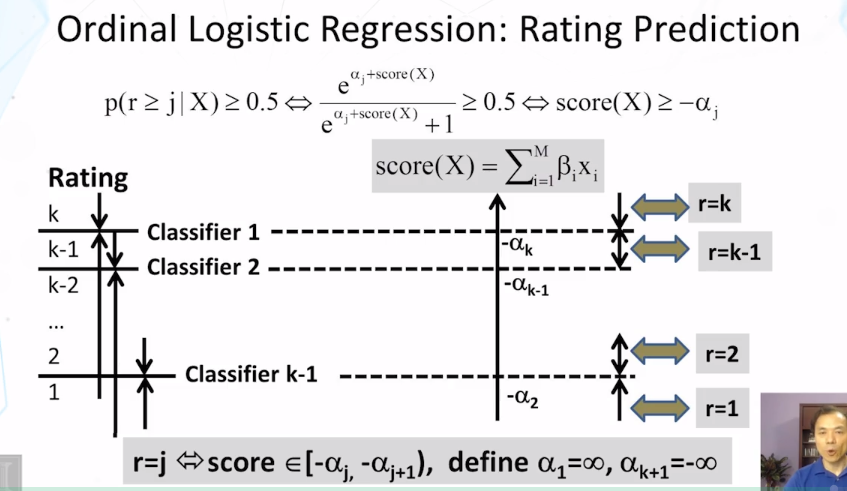
11-2-3 Ordinal Logistic Regression





CS 425 Distributed Systems
Goals
- Apply classical scheduling algorithms.
- Apply popular Hadoop scheduling algorithms.
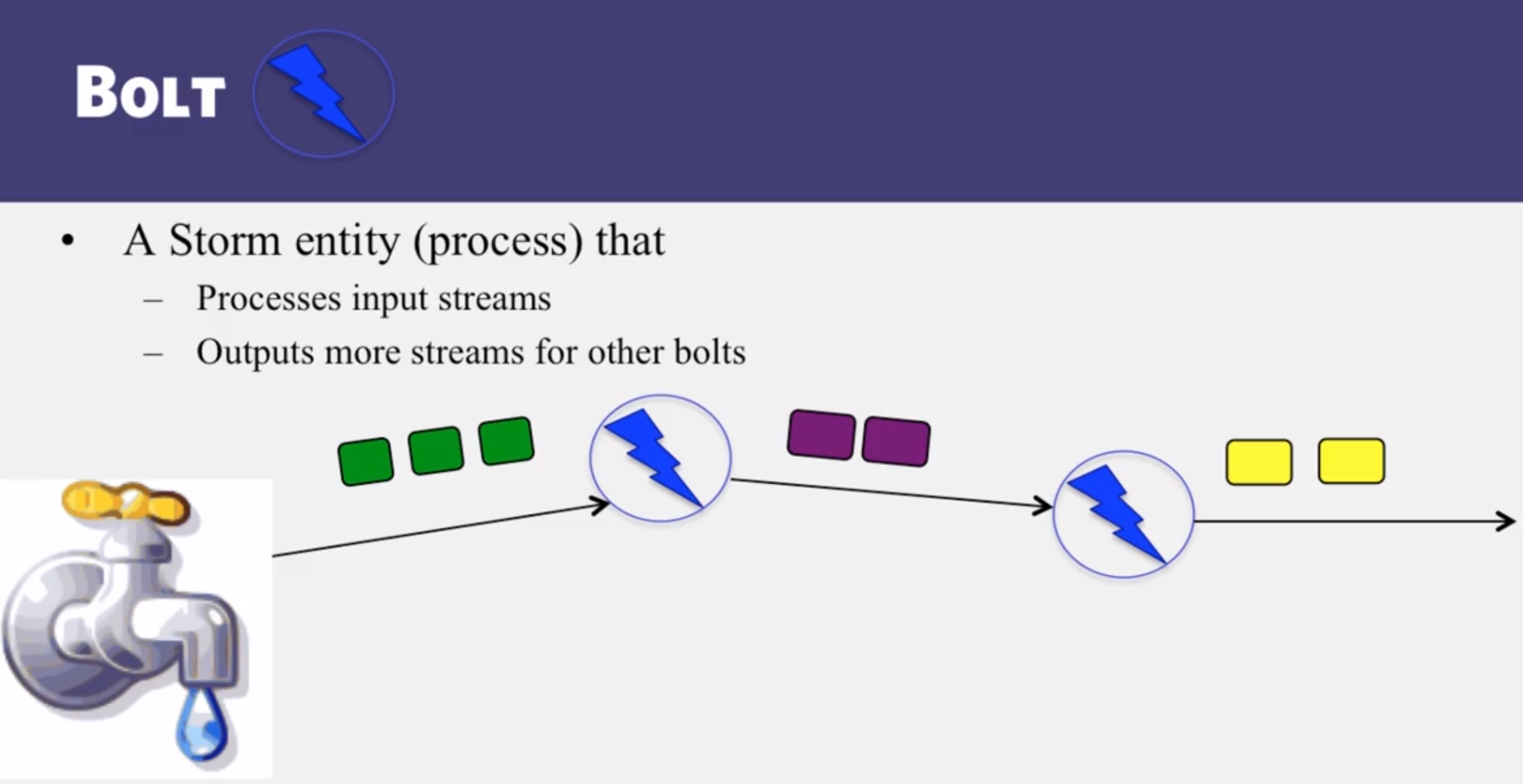
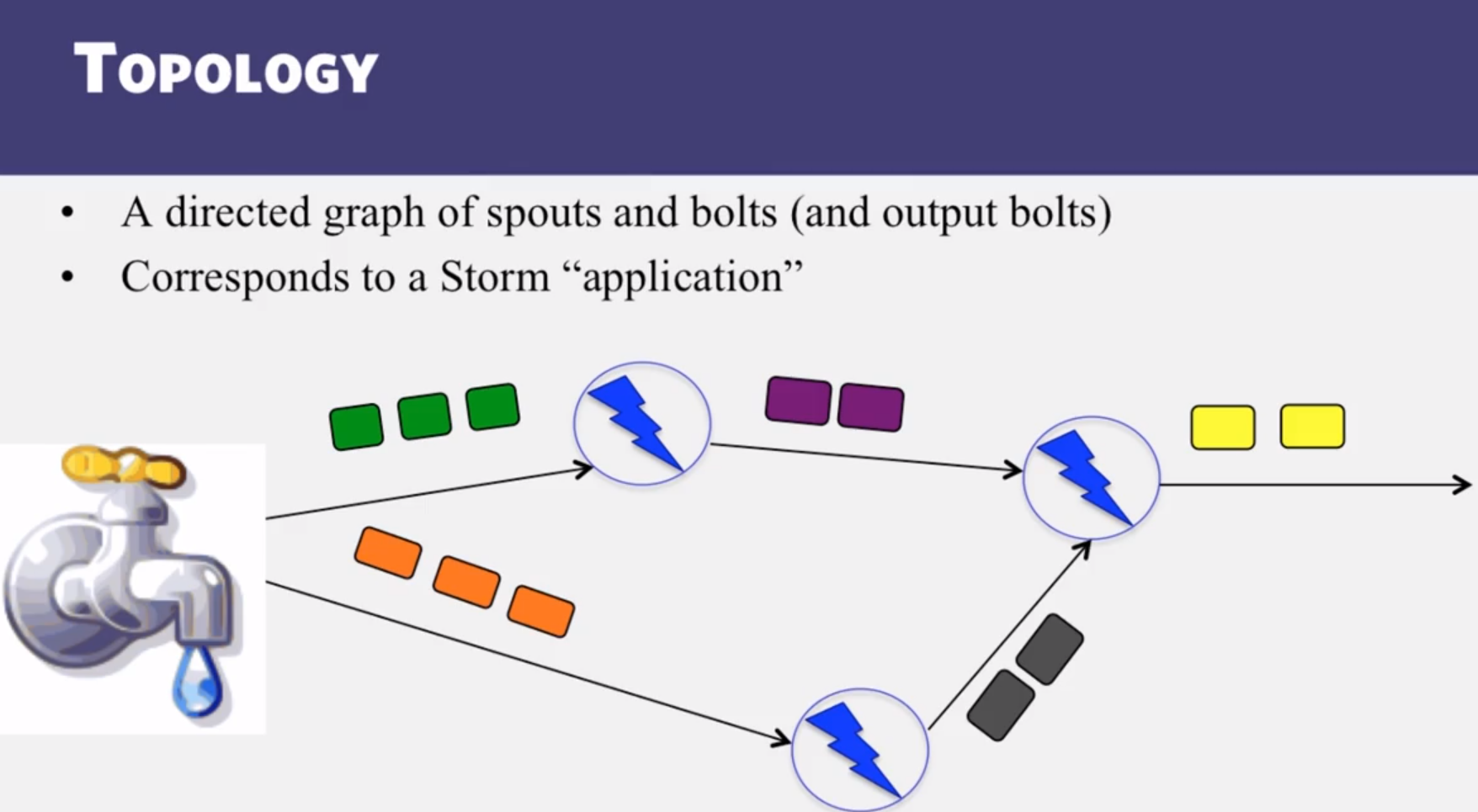
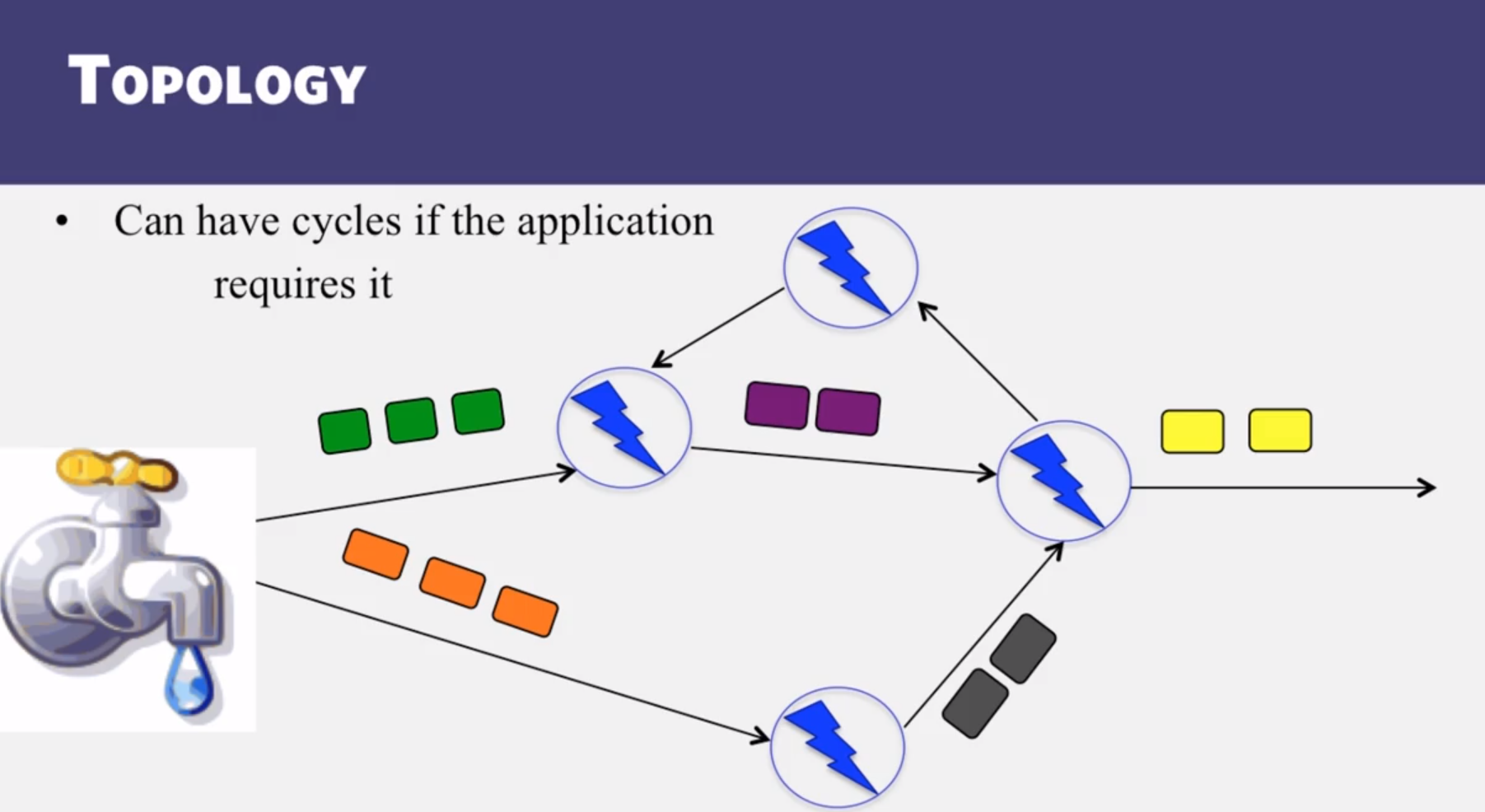
- Know the internals of Apache Storm, a stream processing engine.
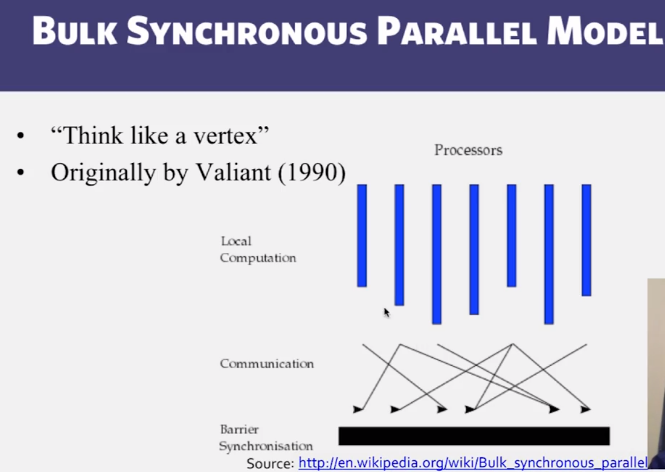
- Know how enormous graphs can be processed in clouds.
Key Concepts
- Classical Scheduling algorithms, including FIFO, Shortest Task First, and Round Robin
- Popular Hadoop schedulers including Capacity Scheduler and Fair Scheduler
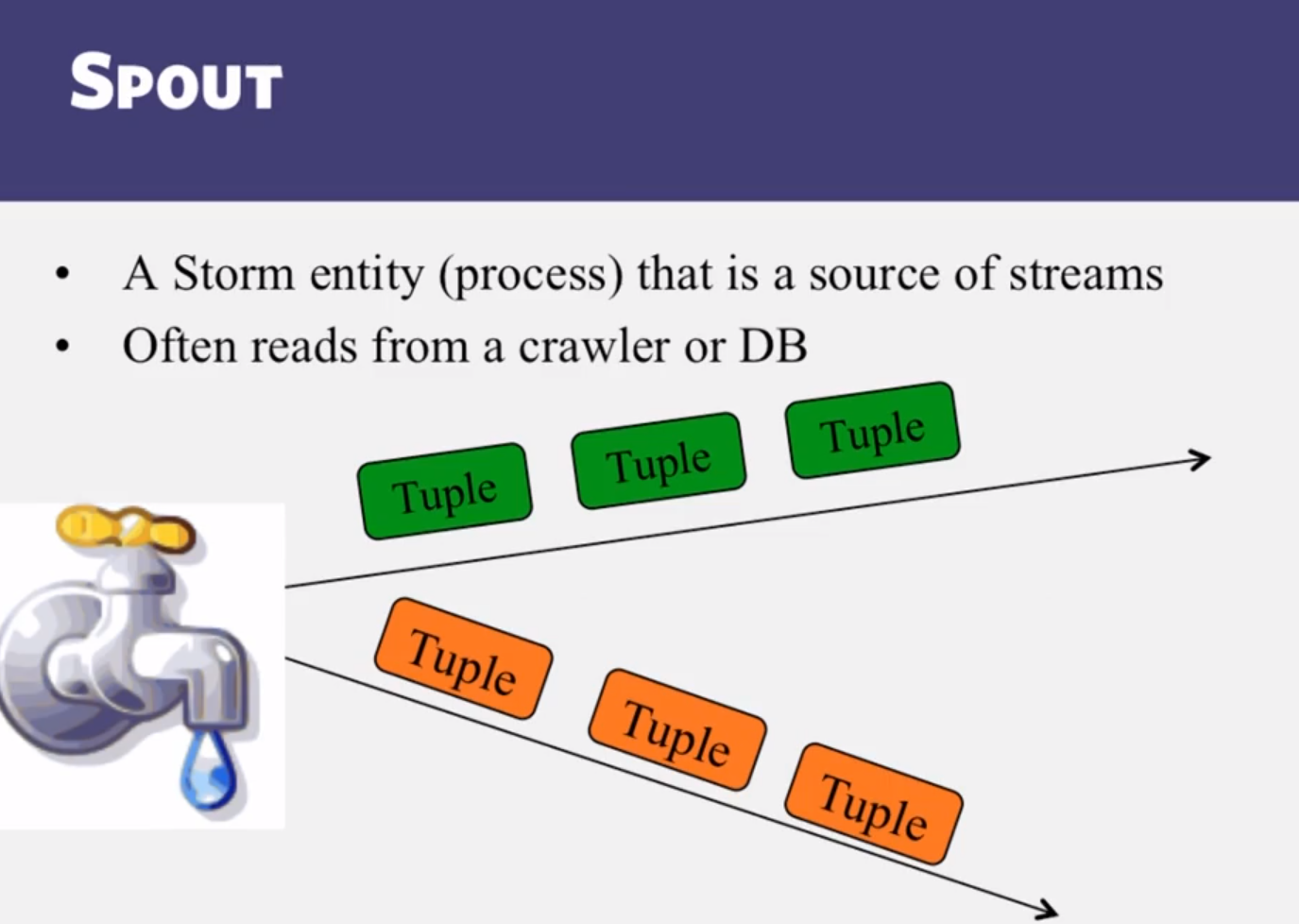
- Internals of Apache Storm, a stream processing engine
- Internals of distributed graph processing engines, e.g., Google’s Pregel
Guiding Questions
- Why is shortest-task-first optimal?
- What is the difference between the Capacity and Fair schedulers in Hadoop?
- What is a Storm topology?
- What is Gather-Apply-Scatter paradigm in distributed graph processing?
Readings and Resources
Apache Storm
Optional: Spark Streaming
Pregel
Video Lecture Notes
Stream Processing













Distributed Graph Processing














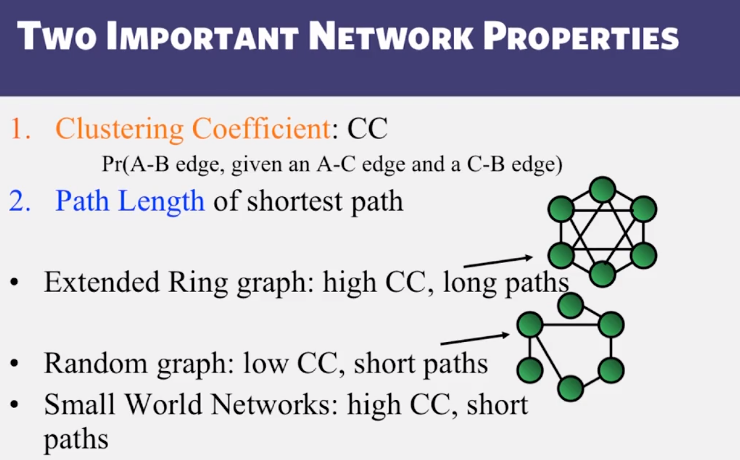
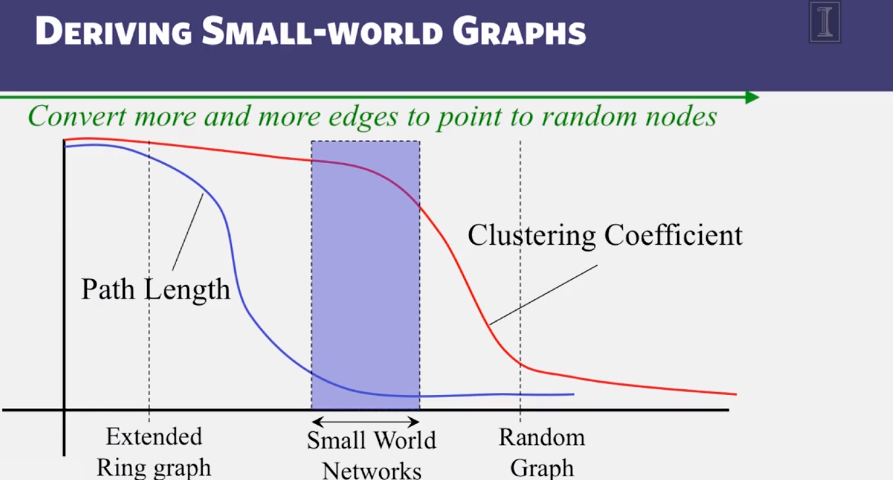
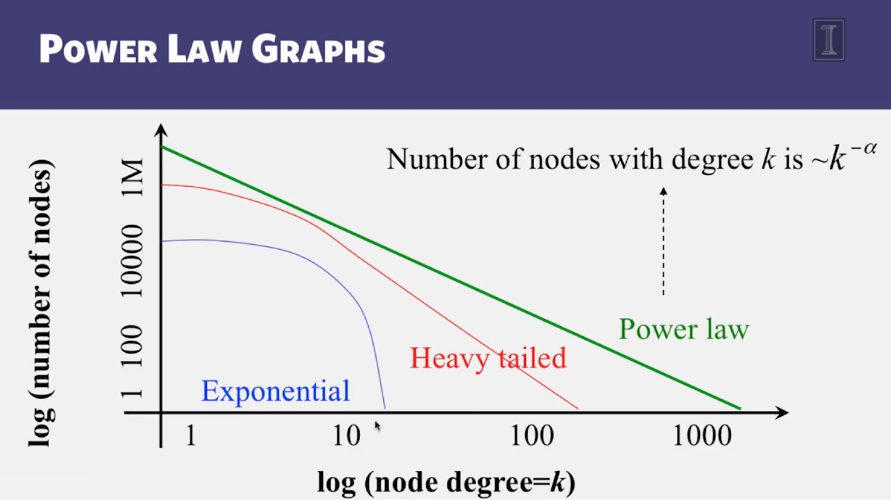
Structure of Networks











Scheduling
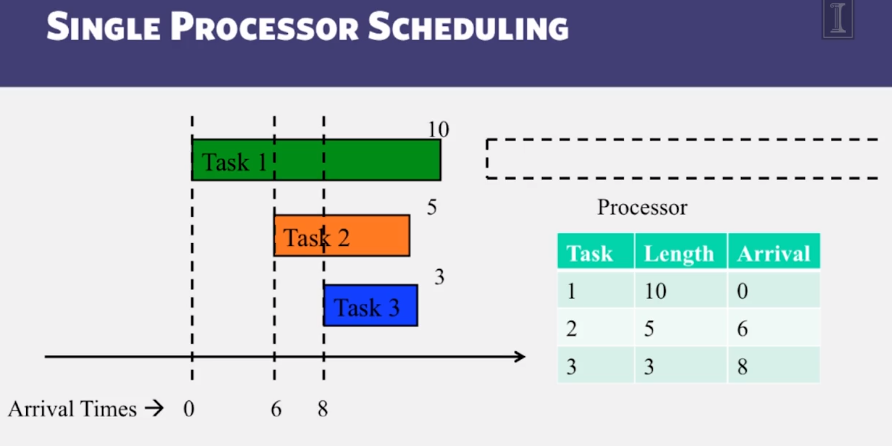
Single-processor Scheduling

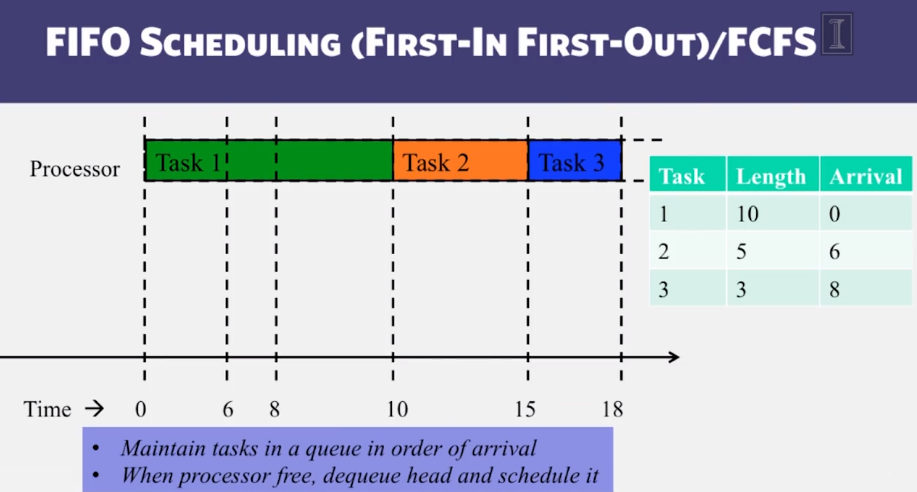

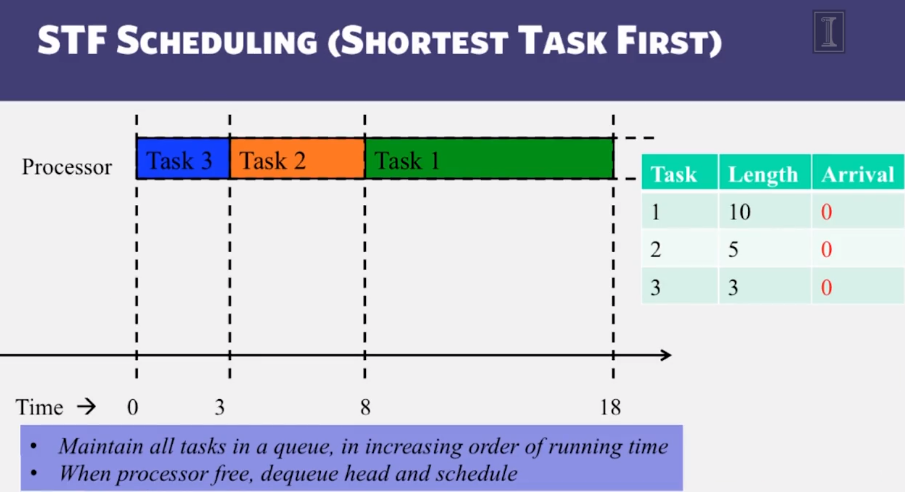

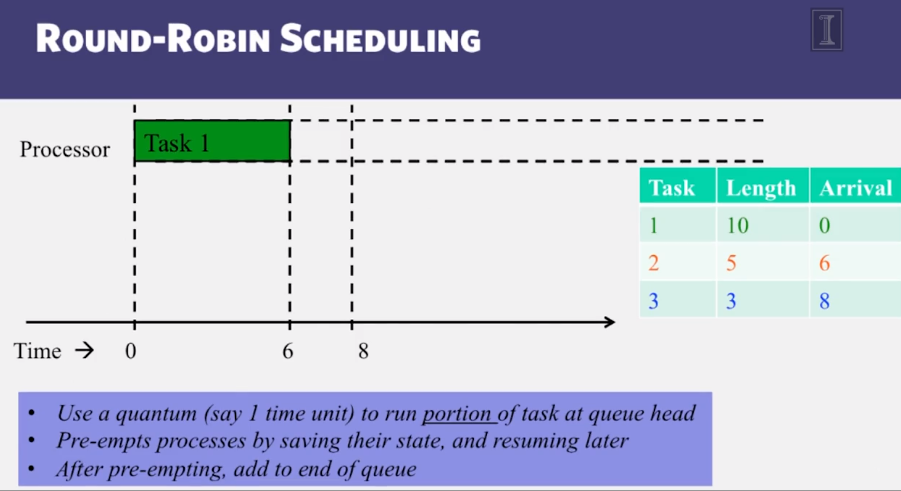
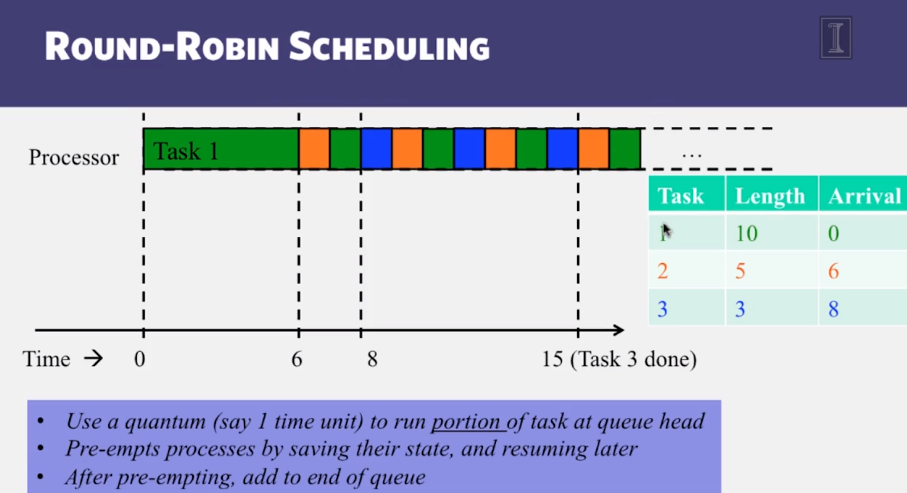


Hadoop Scheduling











Dominant-resource Fair Scheduling









