- CS 410 Text Information Systems
- CS 425 Distributed Systems
- CS 427 Software Engineering
CS 410 Text Information Systems
Goals and Objectives
- Explain why it is necessary and useful to perform joint analysis and mining for text and non-text data.
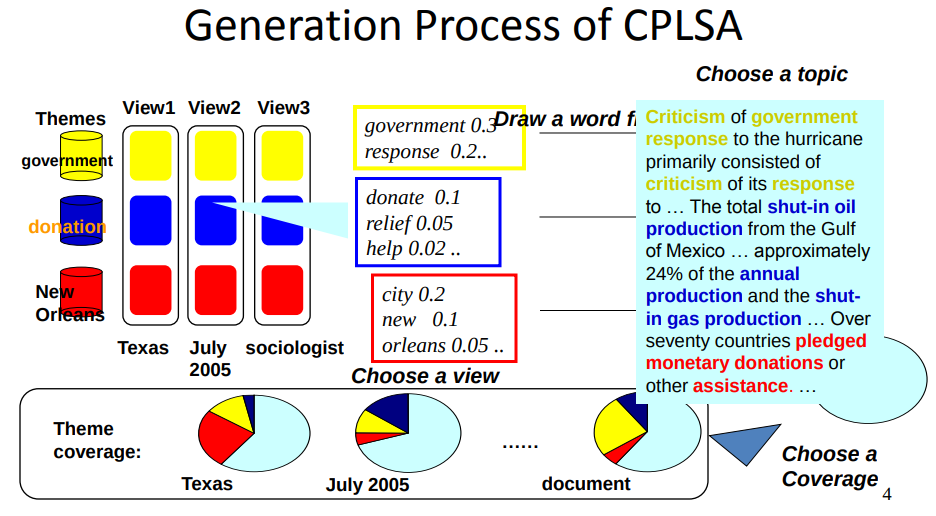
- Explain the general idea of Contextual Probabilistic Latent Semantic Analysis (CPLSA) and the main difference between CPLSA and PLSA.
- Give multiple application examples of CPLSA for contextual text mining.
- Explain the general idea of using the social network of authors as context to analyze topics in text data and its potential benefit from an application perspective.
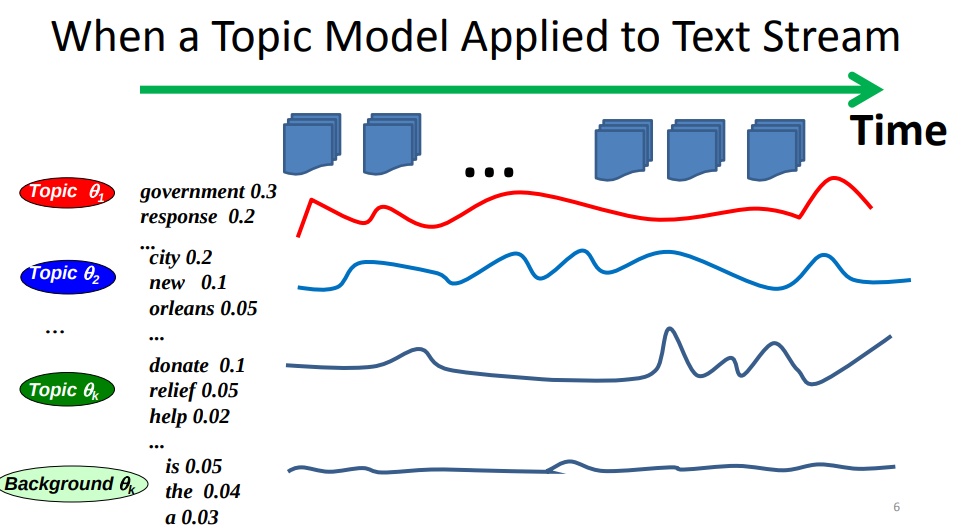
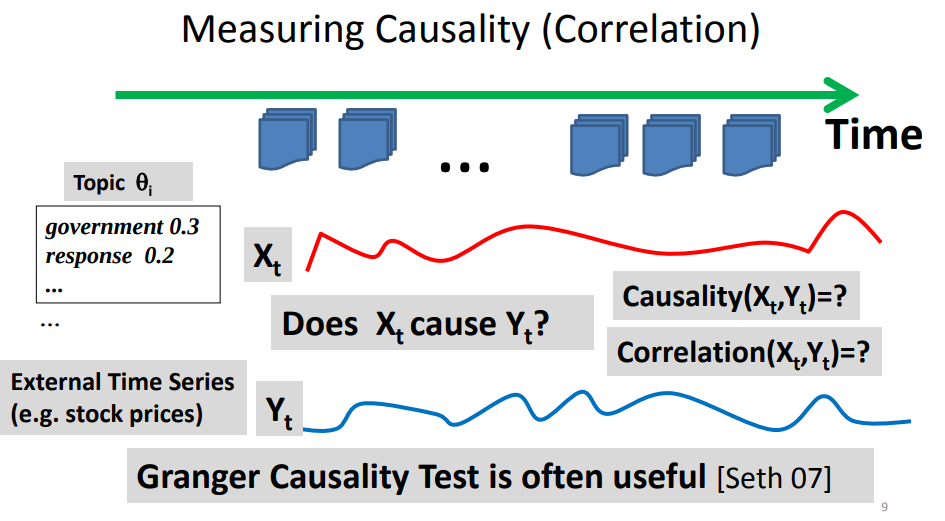
- Explain how a time series (such as stock prices) can be used as context to analyze topics in text data that have time stamps using topic models
Guiding Questions
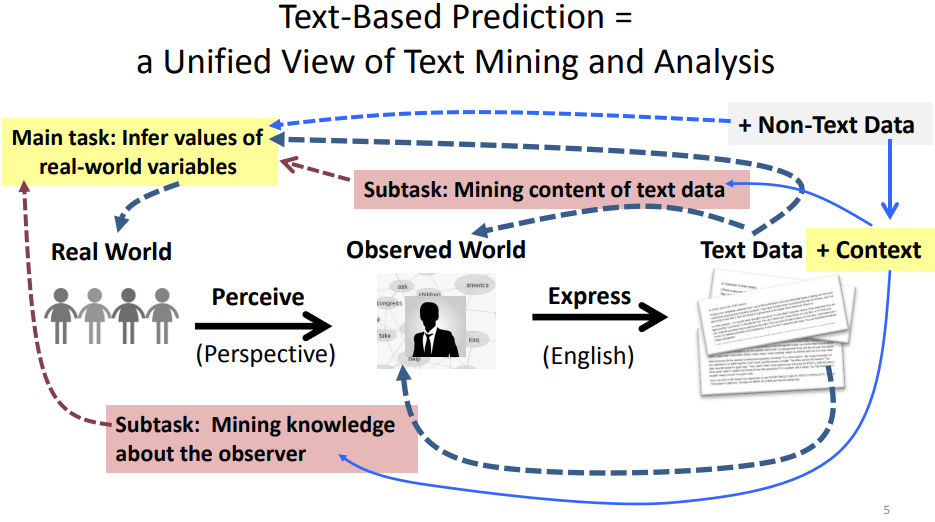
- Why is text-based prediction interesting from an application perspective? Why are humans playing an important role in text-based prediction? What is the “data mining loop”?
- Why is it necessary and useful to jointly mine and analyze text and non-text data? How can non-text data potentially help in analyzing text data? How can text data potentially help in mining non-text data?
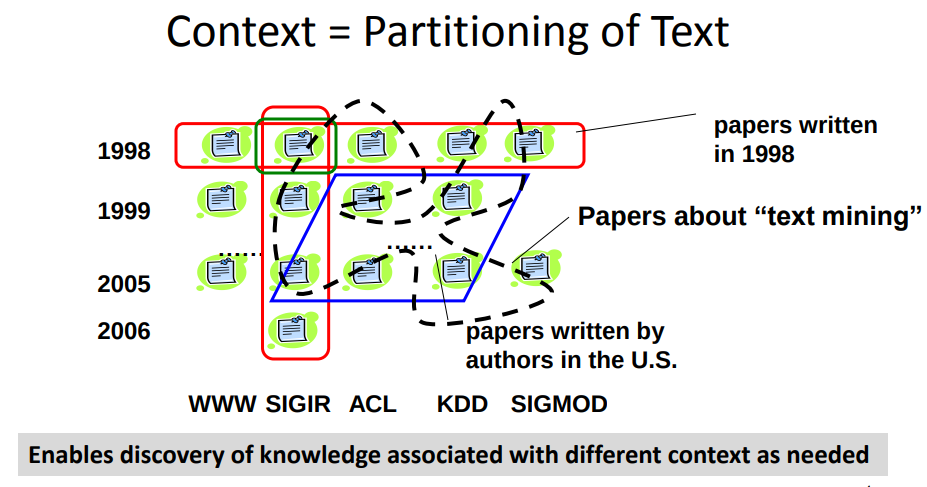
- Can you give some examples of context of a text article? How can we partition text data using context information? Can you give some examples where we can leverage context information to perform interesting comparative analysis of topics in text data?
- What’s the general idea of Contextual Probabilistic Latent Semantic Analysis (CPLSA)? How is it different from PLSA?
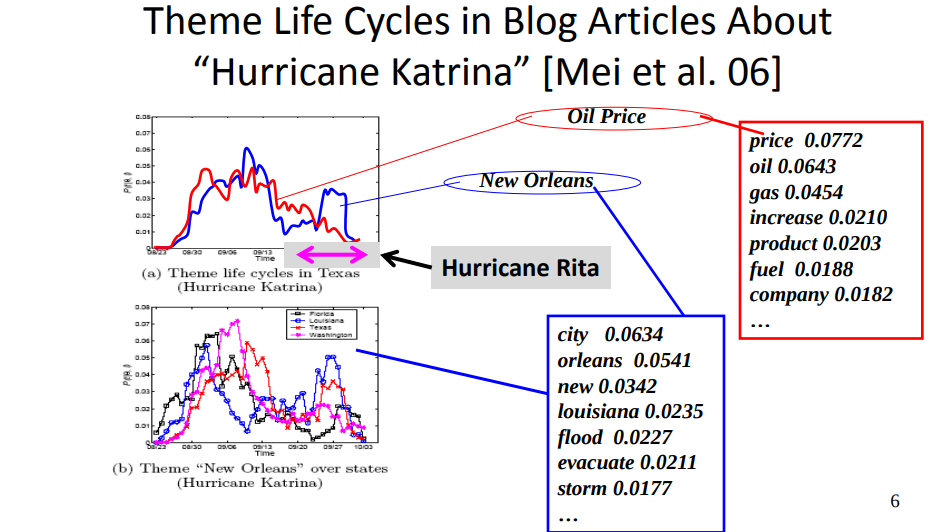
- Can you give some examples of interesting topic patterns that can be found by CPLSA? What’s the general idea of using CPLSA for analyzing the impact of an event? Can you think of an interesting application of this kind?
- What’s the general idea of using the social network of authors of text data as a complex context to improve topic analysis for text data? Can you give an example of an interesting application of this kind?
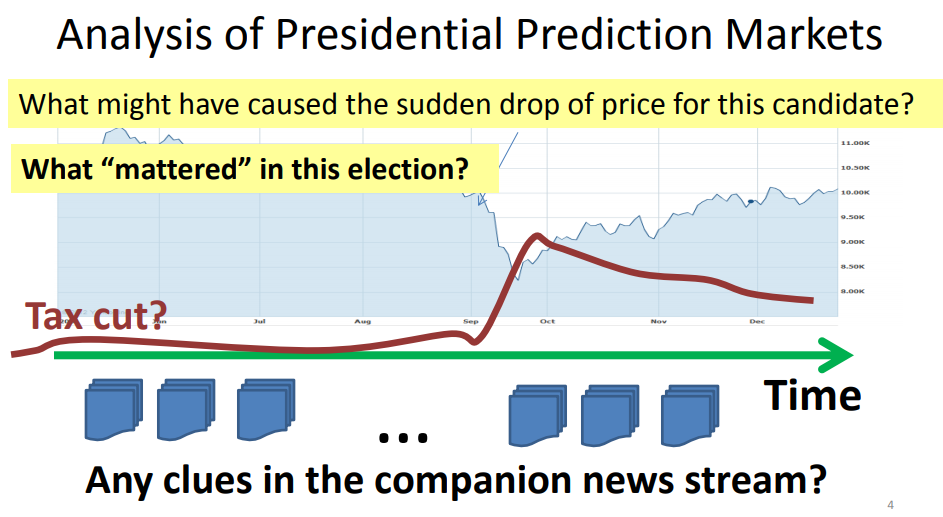
- What’s the general idea of using a time series like stock prices over time to supervise the discovery of topics from text data? Can you give an example of an interesting application of this kind?
Additional Readings and Resources
- C. Zhai and S. Massung, Text Data Management and Analysis: A Practical Introduction to Information Retrieval and Text Mining. ACM and Morgan & Claypool Publishers, 2016. Chapters 18 & 19.
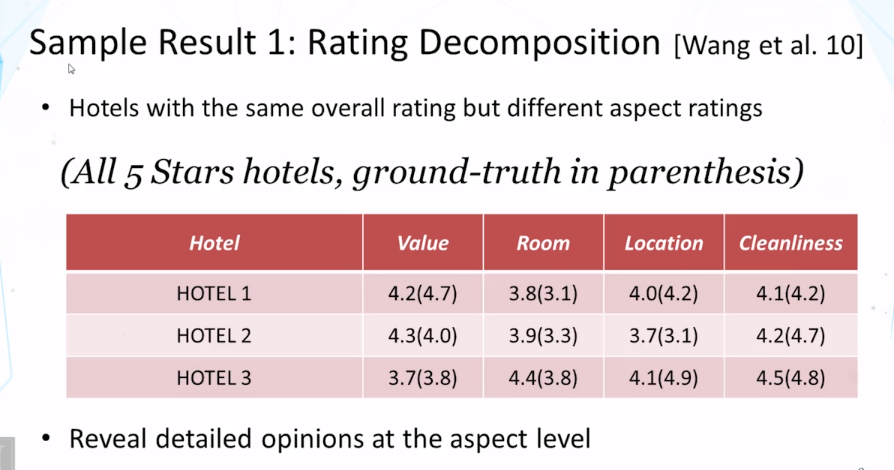
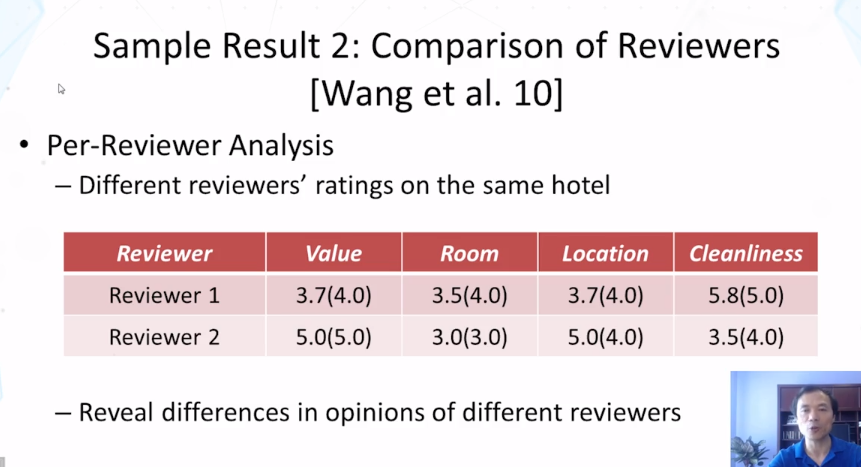
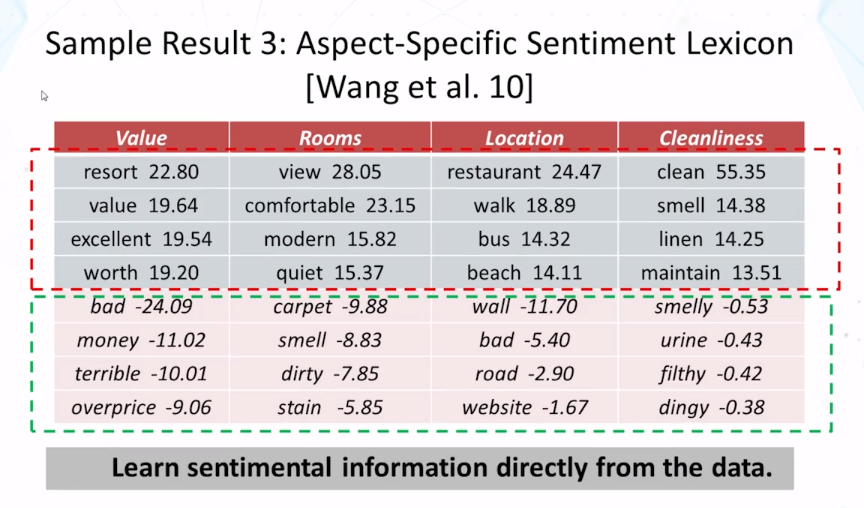
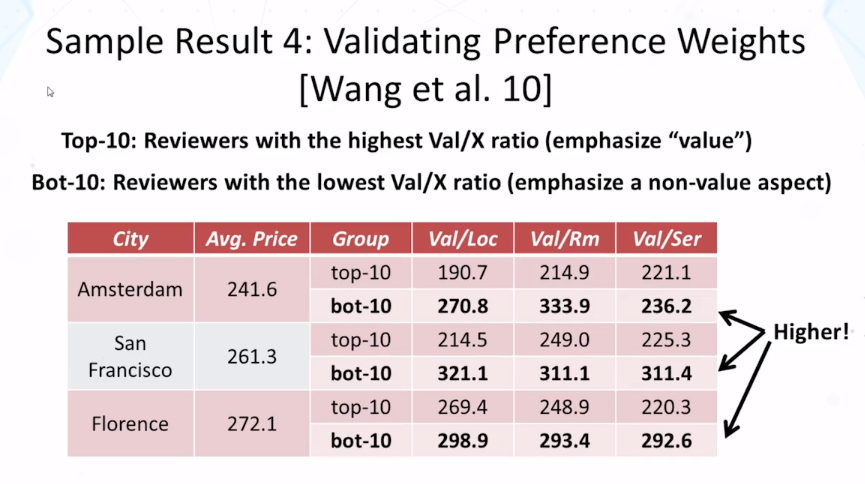
- Hongning Wang, Yue Lu, and ChengXiang Zhai, Latent aspect rating analysis on review text data: a rating regression approach. In Proceedings of ACM KDD 2010, pp. 783-792, 2010. doi: 10.1145/1835804.1835903
- Hongning Wang, Yue Lu, and ChengXiang Zhai. 2011. Latent aspect rating analysis without aspect keyword supervision. In Proceedings of ACM KDD 2011, pp. 618-626. doi: 10.1145/2020408.2020505
- ChengXiang Zhai, Atulya Velivelli, and Bei Yu. A cross-collection mixture model for comparative text mining. In Proceedings of the 10th ACM SIGKDD international conference on knowledge discovery and data mining (KDD 2004). ACM, New York, NY, USA, 743-748. doi: 10.1145/1014052.1014150
- Qiaozhu Mei, Contextual Text Mining, Ph.D. Thesis, University of Illinois at Urbana-Champaign, 2009.
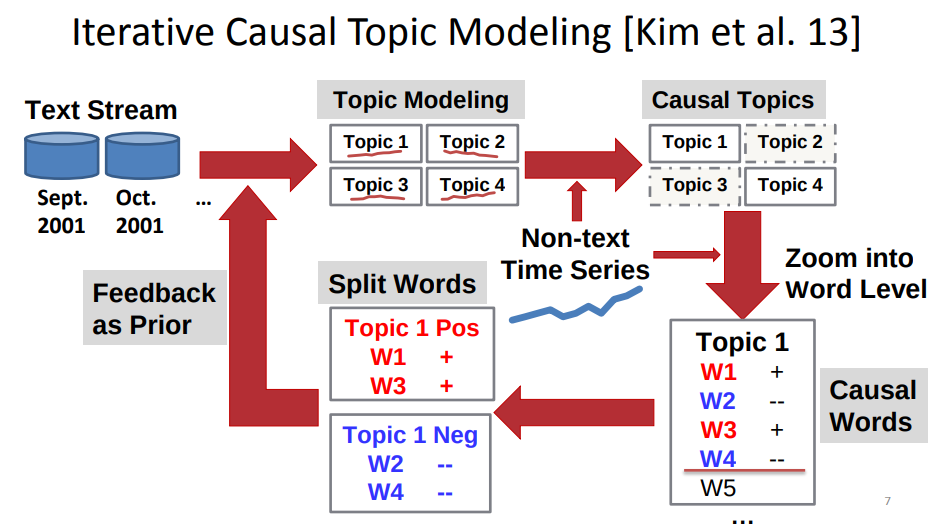
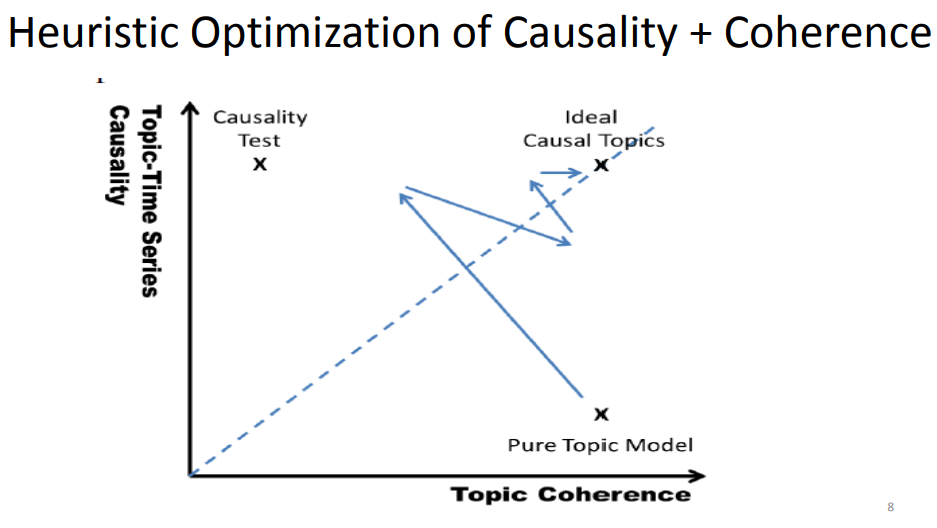
- Hyun Duk Kim, Malu Castellanos, Meichun Hsu, ChengXiang Zhai, Thomas Rietz, and Daniel Diermeier. Mining causal topics in text data: Iterative topic modeling with time series feedback. In Proceedings of the 22nd ACM international conference on information & knowledge management (CIKM 2013). ACM, New York, NY, USA, 885-890. doi: 10.1145/2505515.2505612
- Noah Smith, Text-Driven Forecasting. Retrieved on May 31, 2015 from http://www.cs.cmu.edu/~nasmith/papers/smith.whitepaper10.pdf
Key Phrases and Concepts
- Text-based prediction
- The “data mining loop”
- Context (of text data) and contextual text mining
- Contextual probabilistic latent semantic analysis (CPLSA): views of a topic and coverage of topics
- Spatiotemporal trends of topics
- Event impact analysis
- Network-regularized topic modeling
- NetPLSA
- Causal topics
- Iterative topic modeling with time series supervision
Video Lecture Notes
12-1 Opinion Mining and Sentiment Analysis
12-1-1 Latent Aspect Rating Analysis Part 1



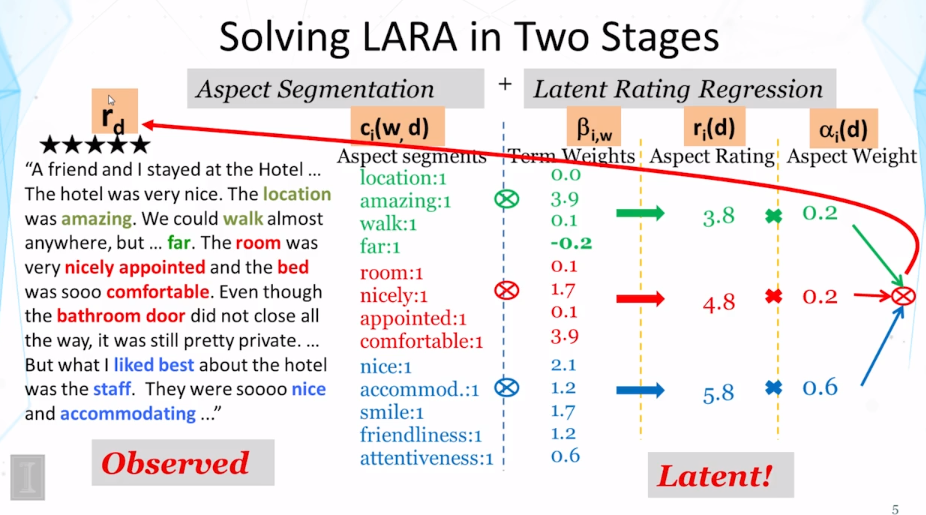


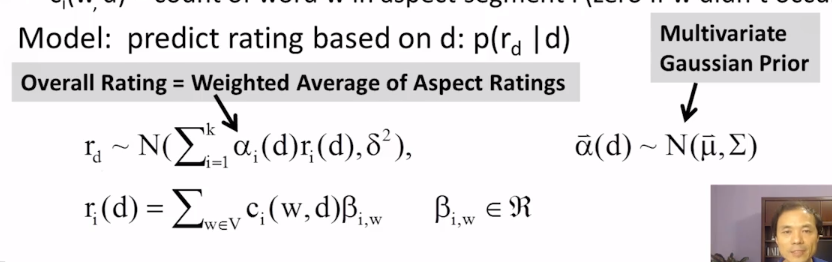

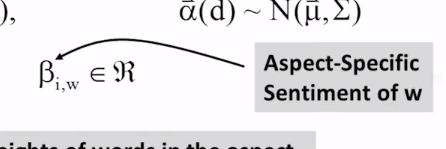

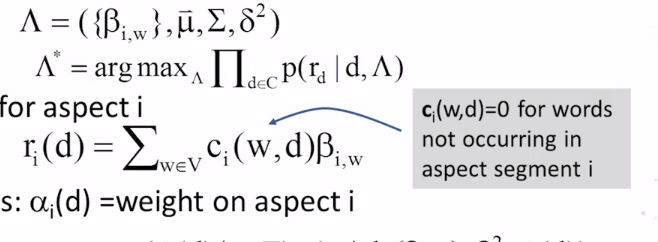

12-1-2 Latent Aspect Rating Analysis Part 2
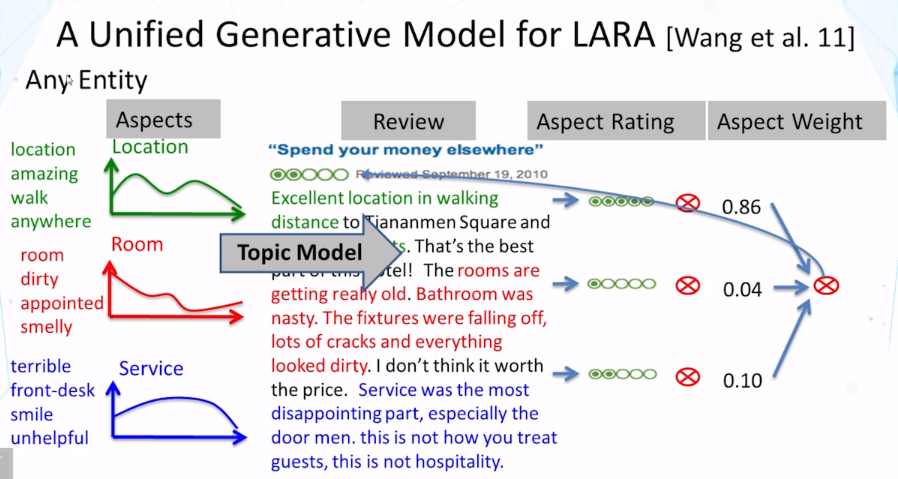


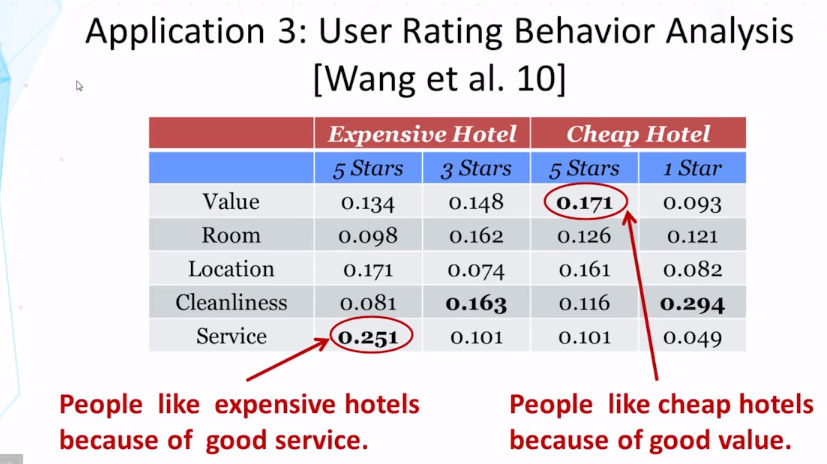
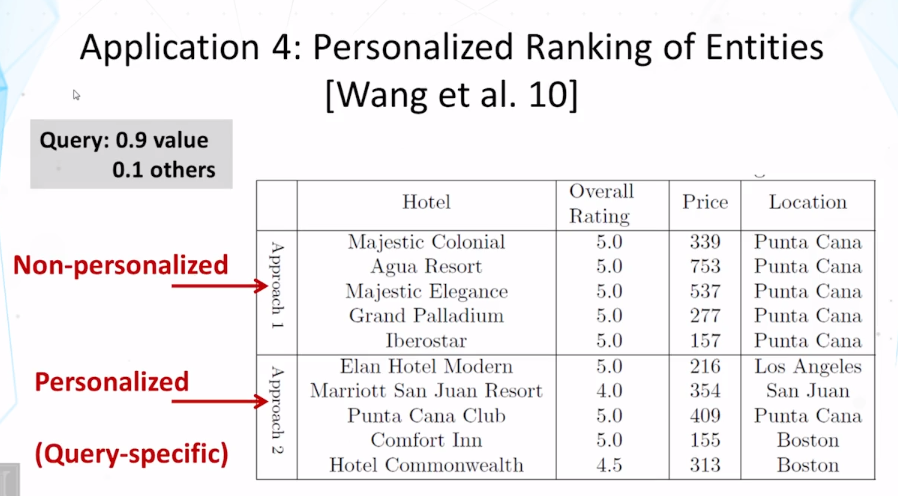

12-2 Text-Based Prediction
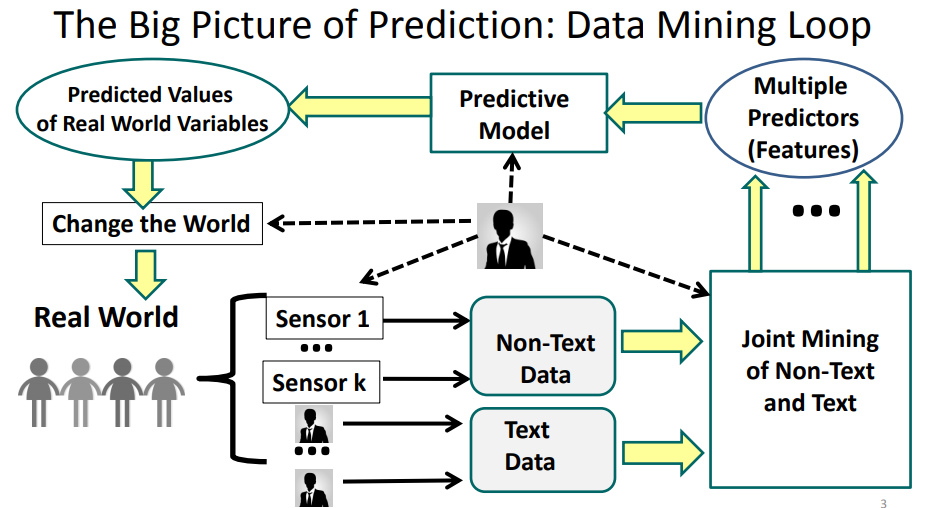
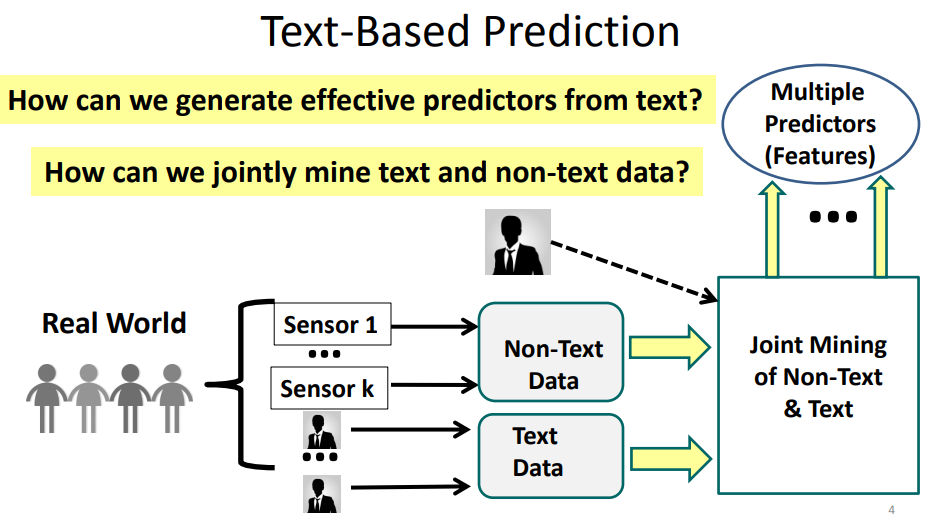

12-3 Contextual Text Mining
12-3-1 Motivation


12-3-2 Contextual Probabilistic Latent Semantic Analysis


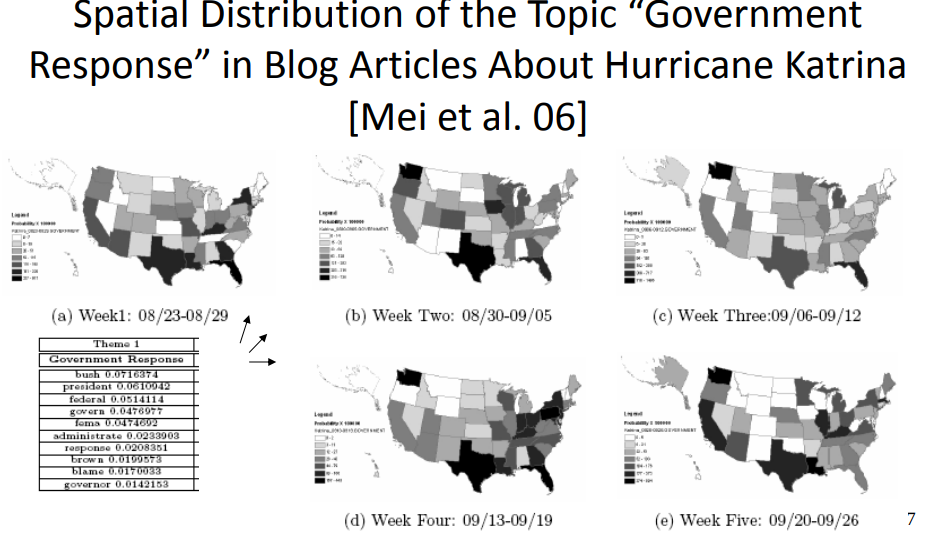

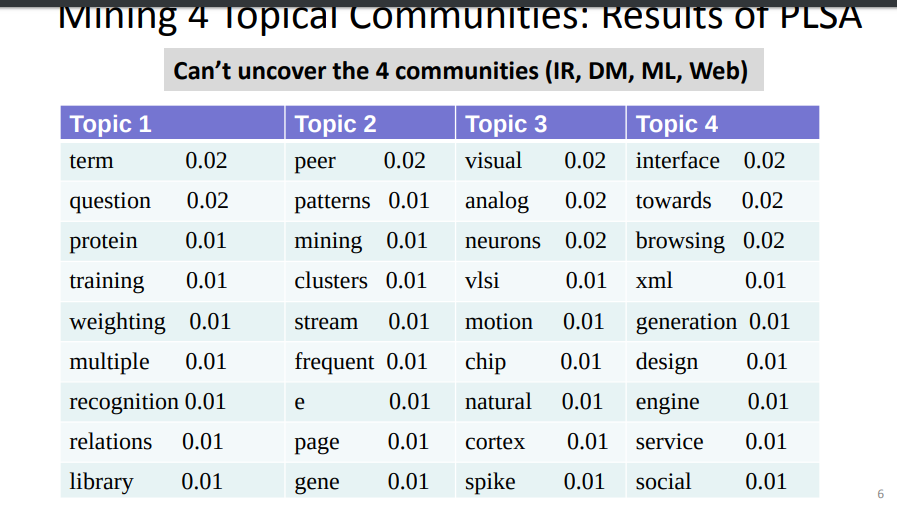
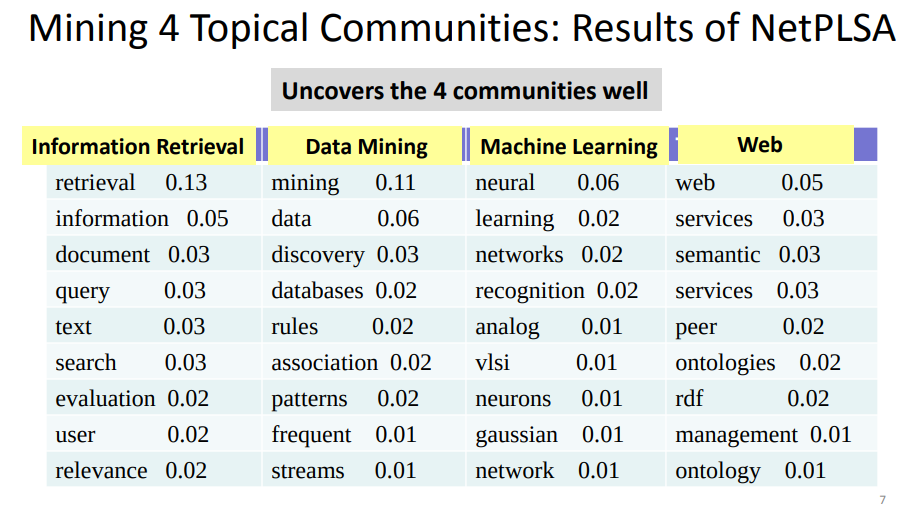
12-3-3 Mining topics with social network context




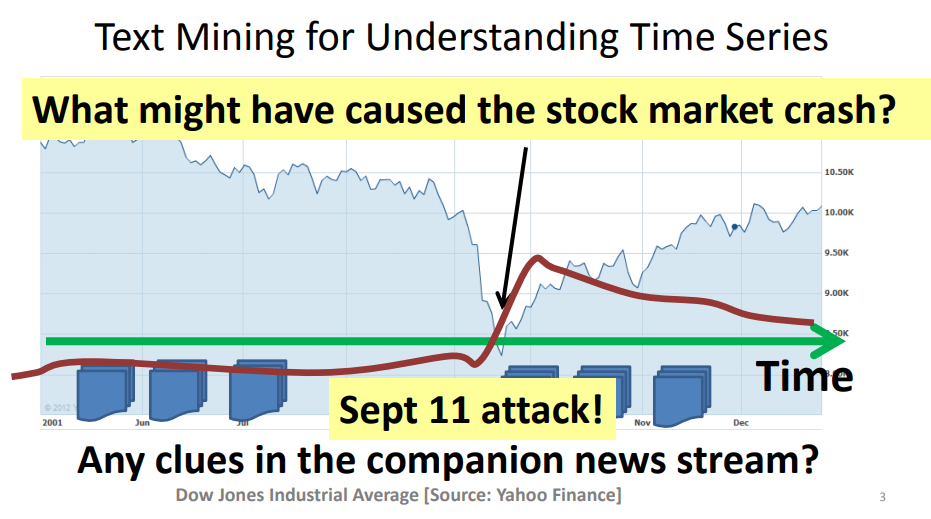
12-3-4 Mining Causal Topics with Time Series Supervision




12-4 Summary for Exam 2

CS 425 Distributed Systems
Goals
- Know the internals of Distributed File Systems like NFS and AFS.
- Know the internals of Distributed Shared Memory systems.
- Know what’s inside a sensor mote and why networks of them are needed.
Key Concepts
- Distributed File Systems: Why they’re different from single-node file systems
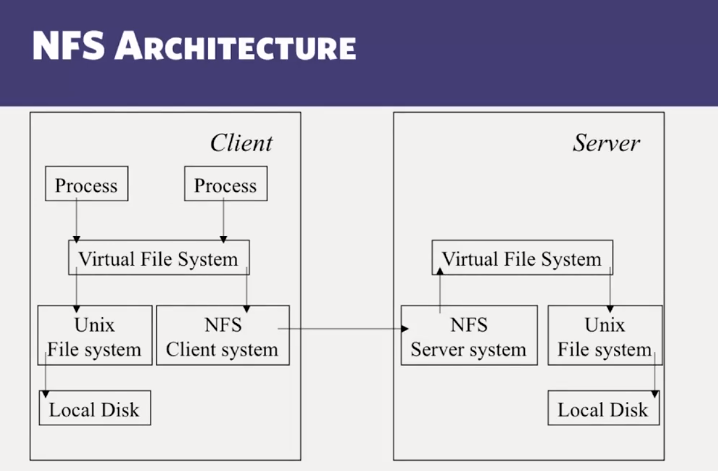
- Internals of NFS
- Internals of AFS
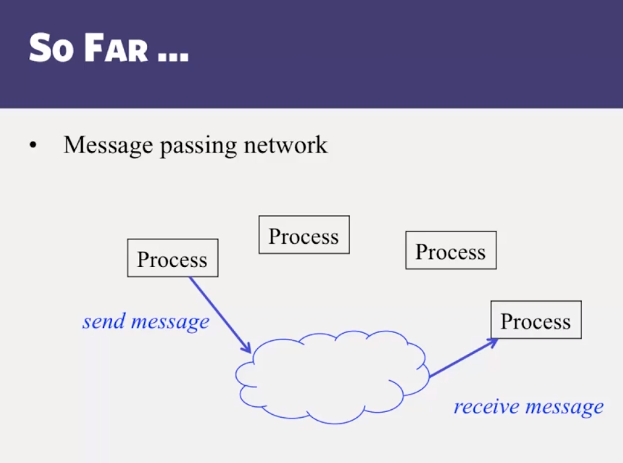
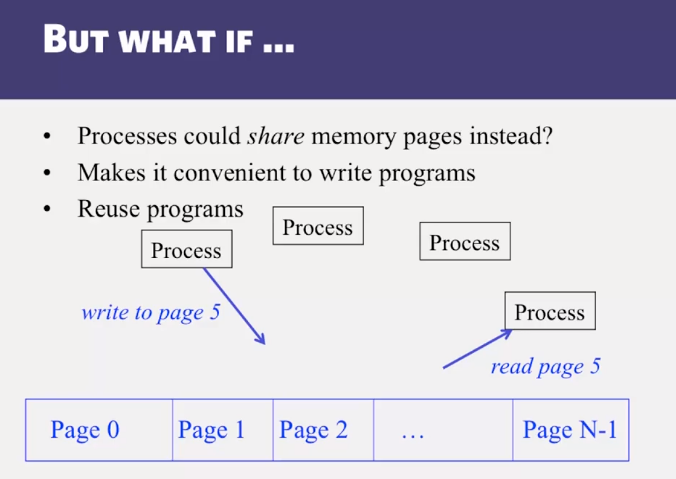
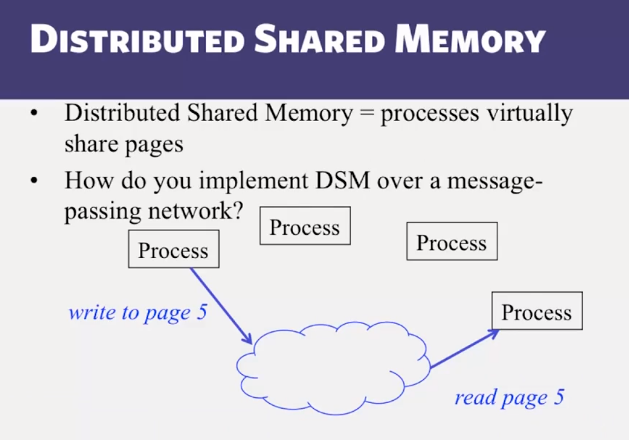
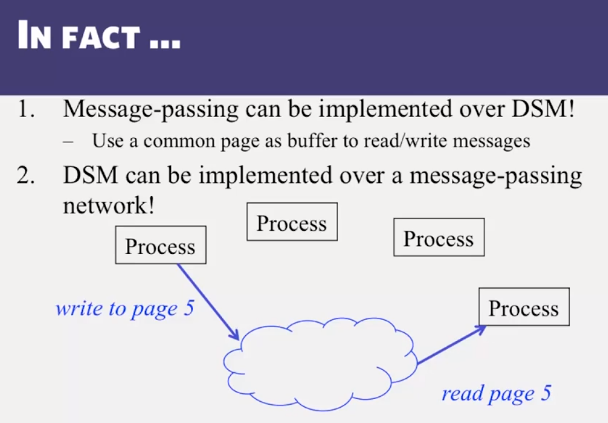
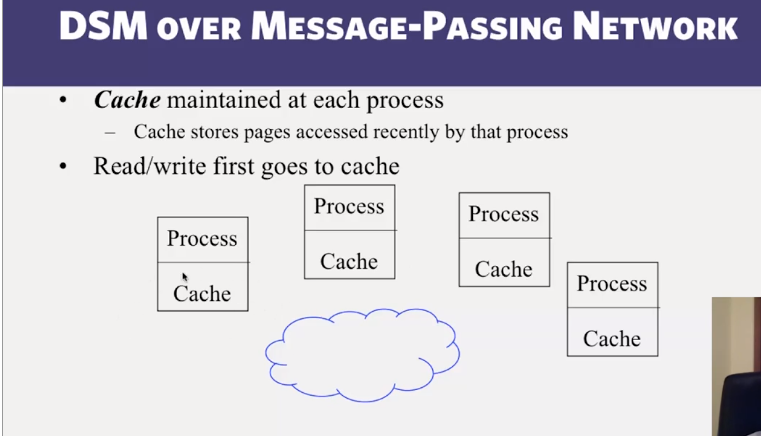
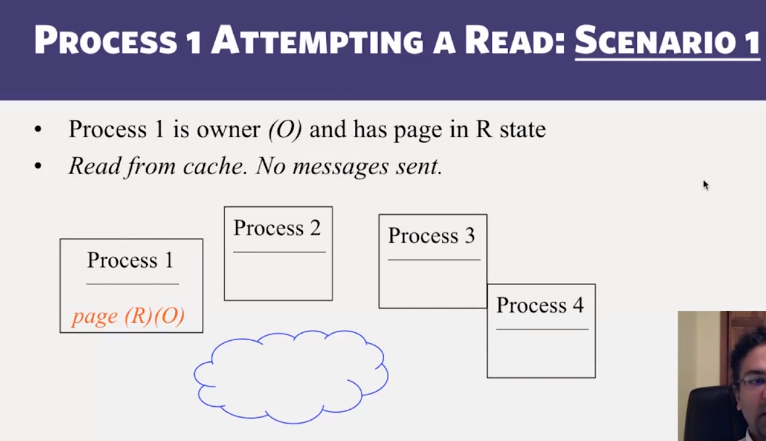
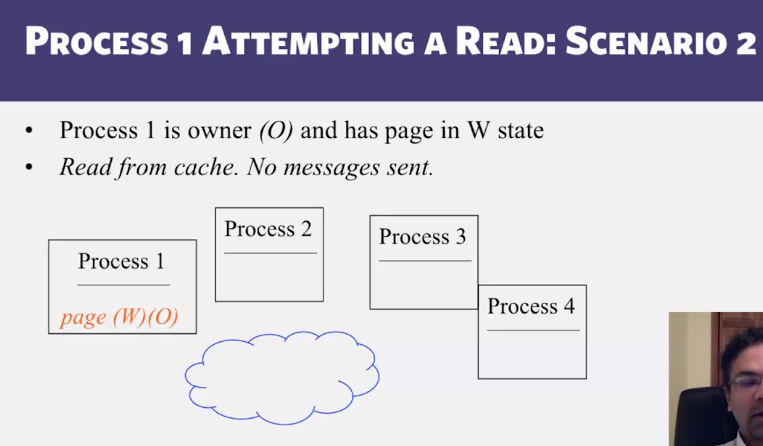
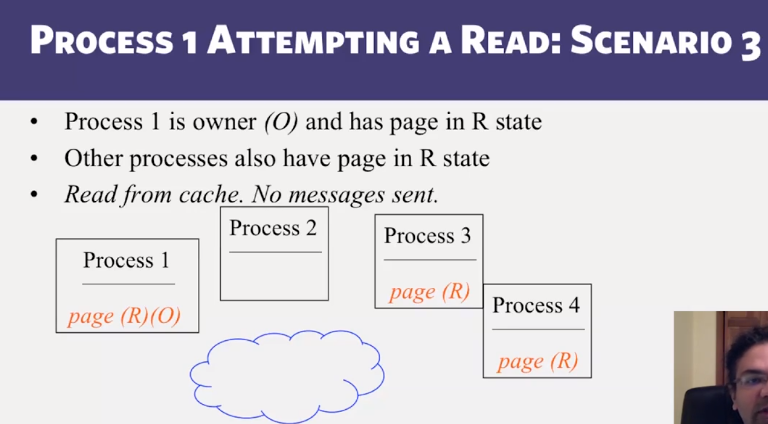
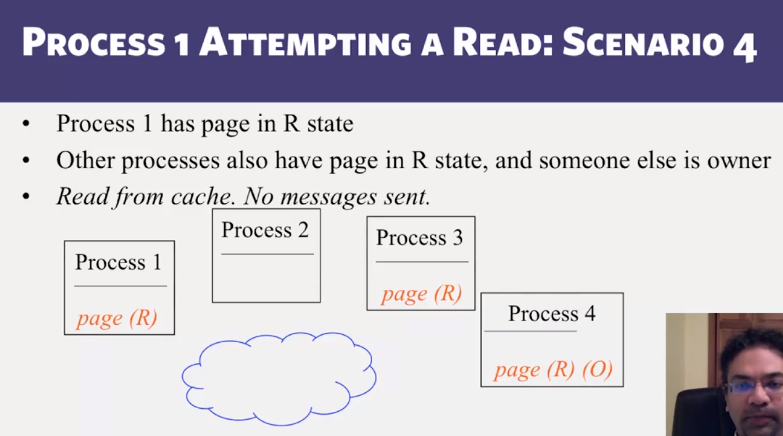
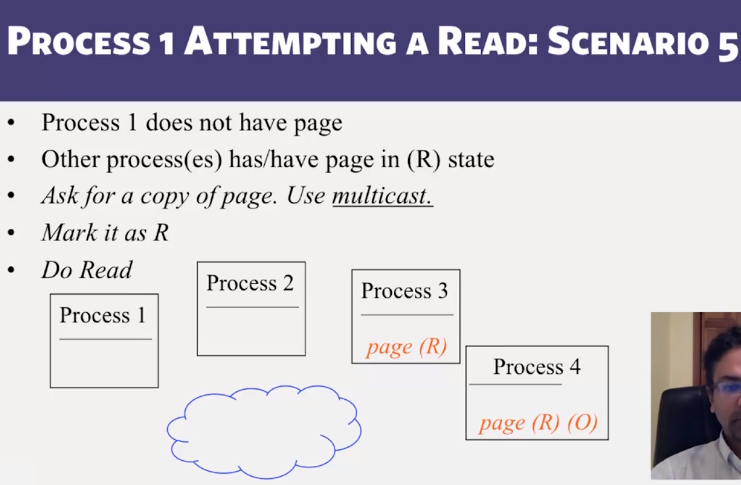
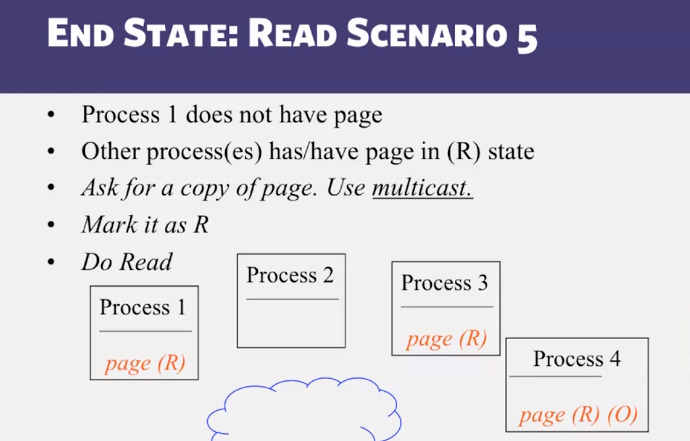
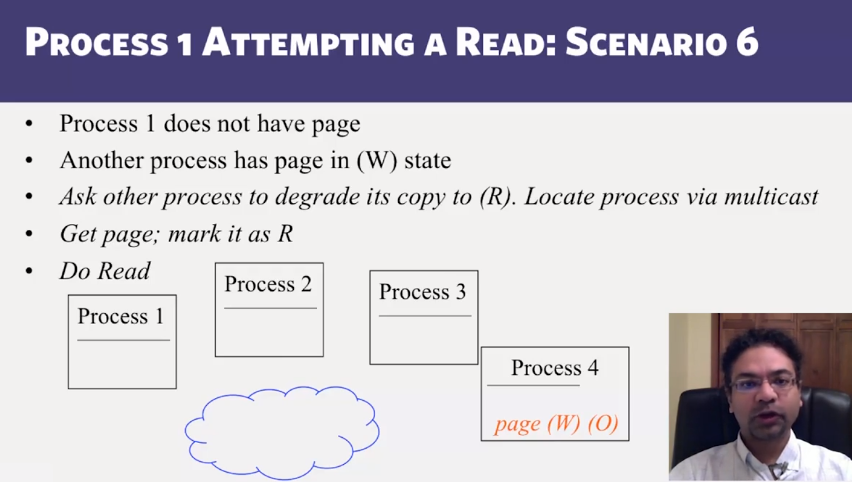
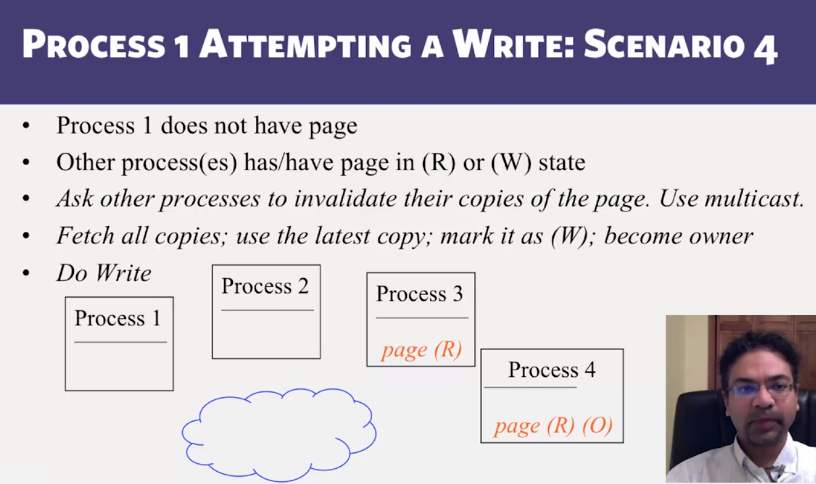
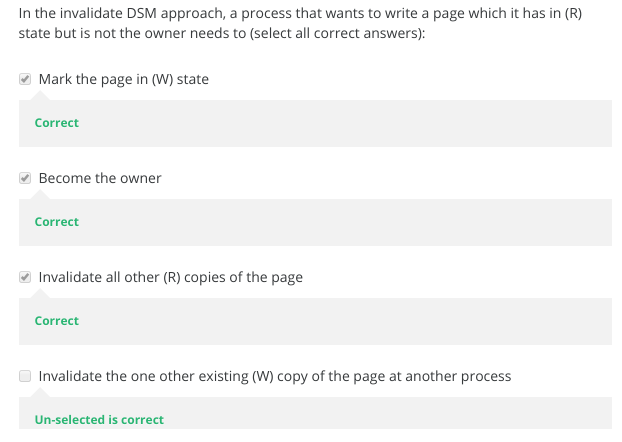
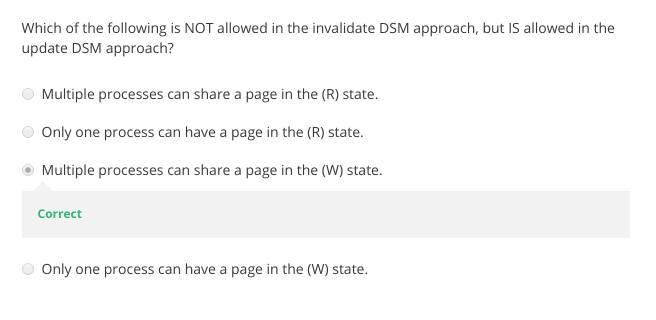
- Distributed Shared Memory: How processes can share memory pages while communicating via messages
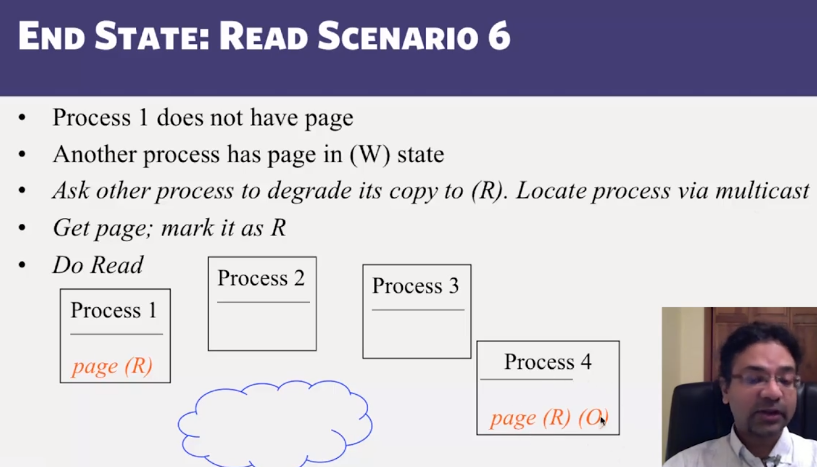
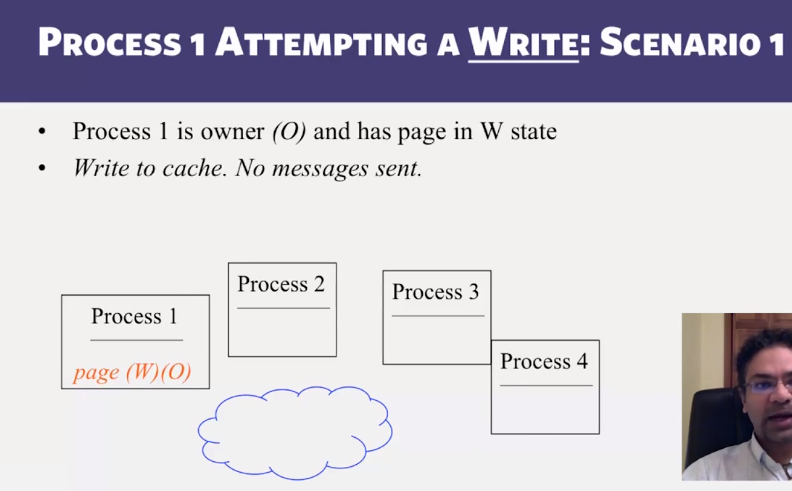
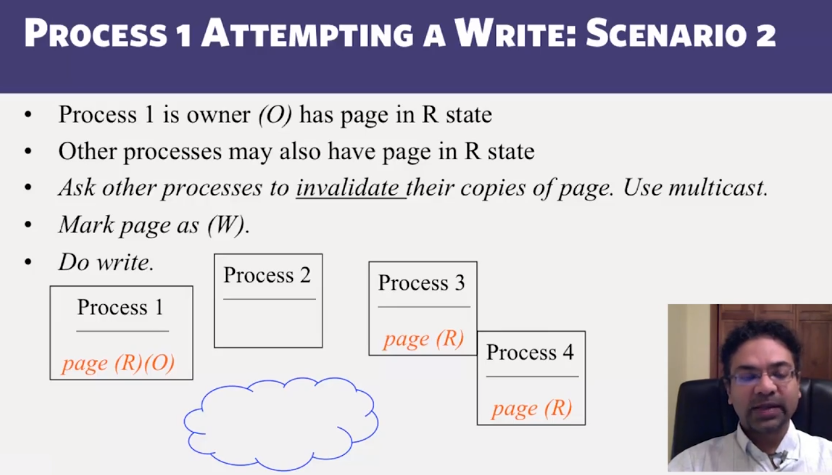
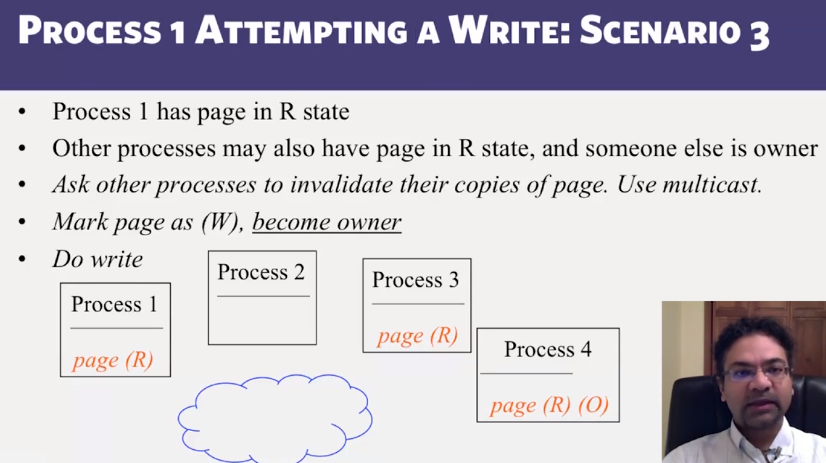
- Invalidate protocols in Distributed Shared Memory systems
- Sensor networks: Why they’ve emerged, what’s inside them, where they’re used, and what are the challenges
Guiding Questions
- Why are Distributed File Systems stateless?
- How does NFS provide transparency?
- Why is whole file caching a reasonable approach in AFS?
- When is invalidate preferable over update in Distributed Shared memory systems?
- Why can’t embedded operating systems be used in sensor motes?
- What is the disadvantage of using a spanning tree in sensor network, for aggregation?
Readings and Resources
- TinyOS
Video Lecture Notes
Distributed File Systems
File System Abstraction














NFS and AFS









Distributed Shared Memory