- CS 410 Text Information Systems
- CS 425 Distributed Systems
- CS 427 Software Engineering
CS 410 Text Information Systems
Goals and Objectives
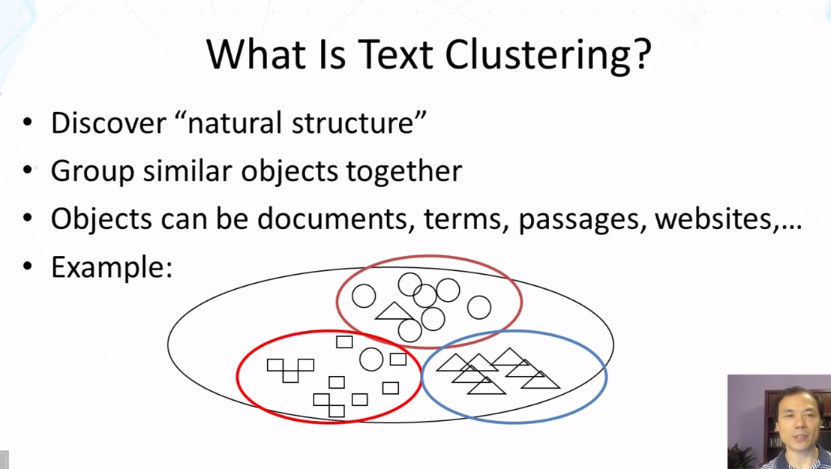
- Explain the concept of text clustering and why it is useful.
- Explain how Hierarchical Agglomerative Clustering and k-Means clustering work.
- Explain how to evaluate text clustering.
- Explain the concept of text categorization and why it is useful.
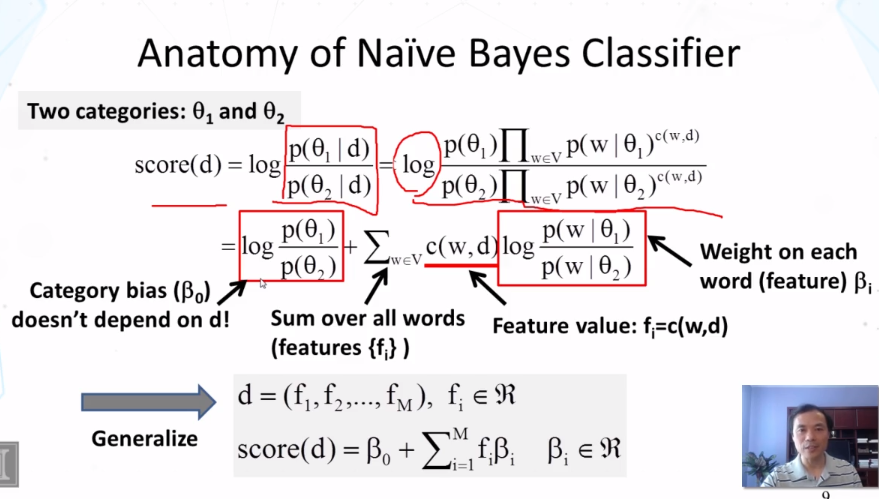
- Explain how Naïve Bayes classifier works.
Guiding Questions
- What is clustering? What are some applications of clustering in text mining and analysis?
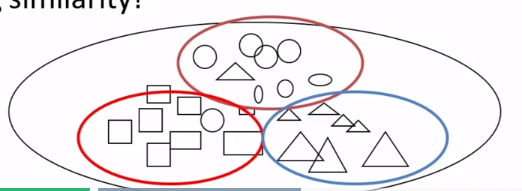
- How does hierarchical agglomerative clustering work? How do single-link, complete-link, and average-link work for computing group similarity? Which of these three ways of computing group similarity is least sensitive to outliers in the data?
- How do we evaluate clustering results?
- What is text categorization? What are some applications of text categorization?
- What does the training data for categorization look like?
- How does the Naïve Bayes classifier work?
- Why do we often use logarithm in the scoring function for Naïve Bayes?
Additional Readings and Resources
- C. Zhai and S. Massung, Text Data Management and Analysis: A Practical Introduction to Information Retrieval and Text Mining. ACM and Morgan & Claypool Publishers, 2016. Chapters 14 & 15.
- Manning, Chris D., Prabhakar Raghavan, and Hinrich Schütze. Introduction to Information Retrieval. Cambridge: Cambridge University Press, 2007. Chapters 13-16.
- Yang, Yiming. An Evaluation of Statistical Approaches to Text Categorization. Inf. Retr. 1, 1-2 (May 1999), 69-90. doi: 10.1023/A:1009982220290
Key Phrases and Concepts
- Clustering, document clustering, and term clustering
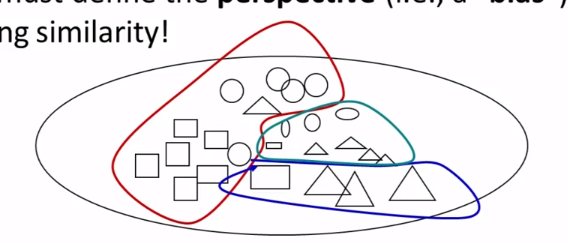
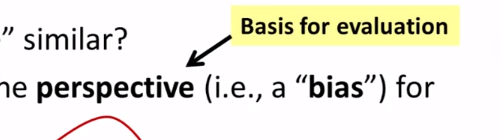
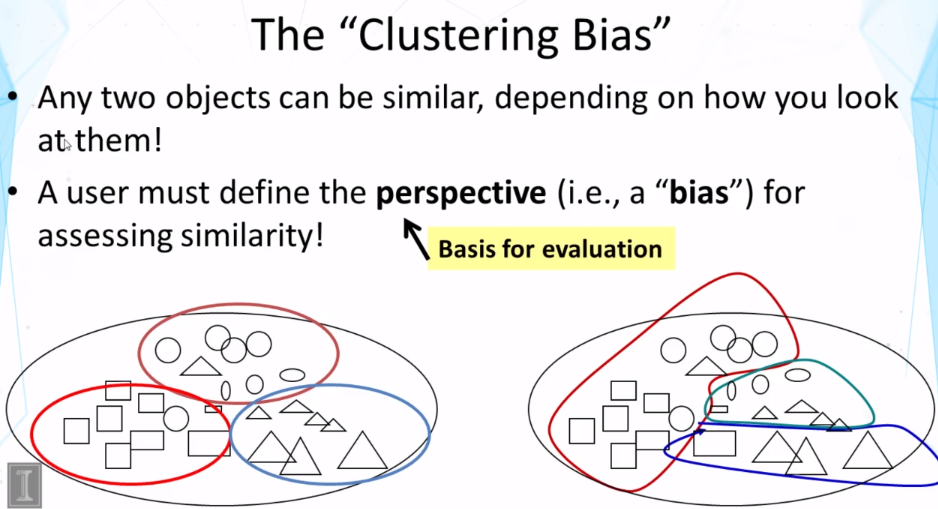
- Clustering bias
- Perspective of similarity
- Hierarchical Agglomerative Clustering, and k-Means
- Direction evaluation (of clustering), indirect evaluation (of clustering)
- Text categorization, topic categorization, sentiment categorization, email routing
- Spam filtering
- Naïve Bayes classifier
- Smoothing
Video Lecture Notes
10-1 Text Clustering
10-1-1 Motivation




10-1-2 Generative Probabilistic Models Part 1
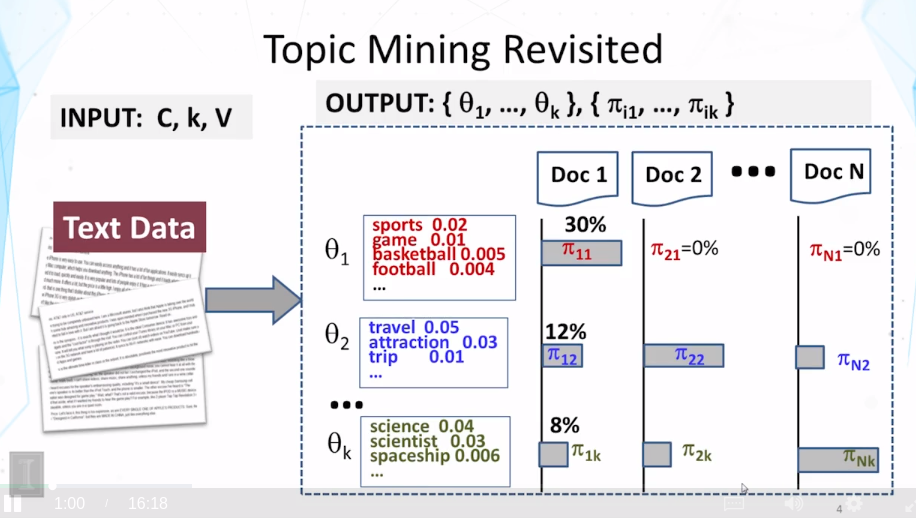
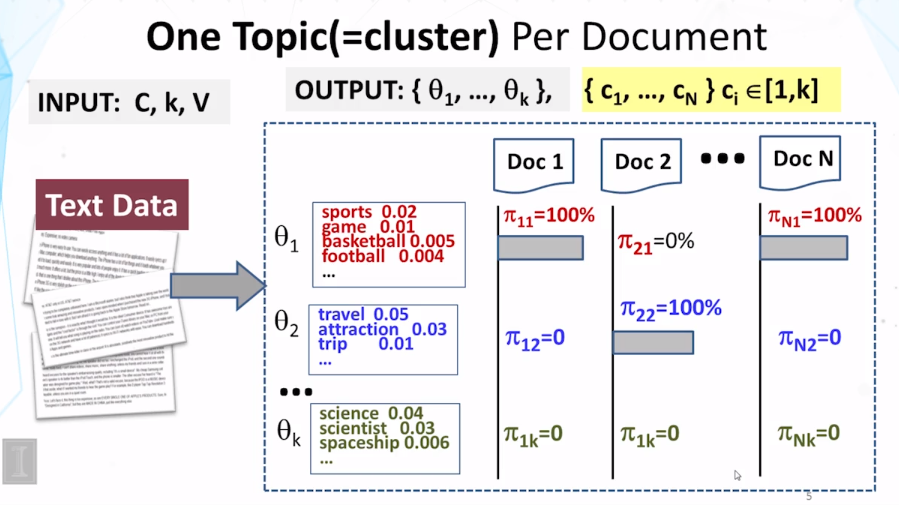
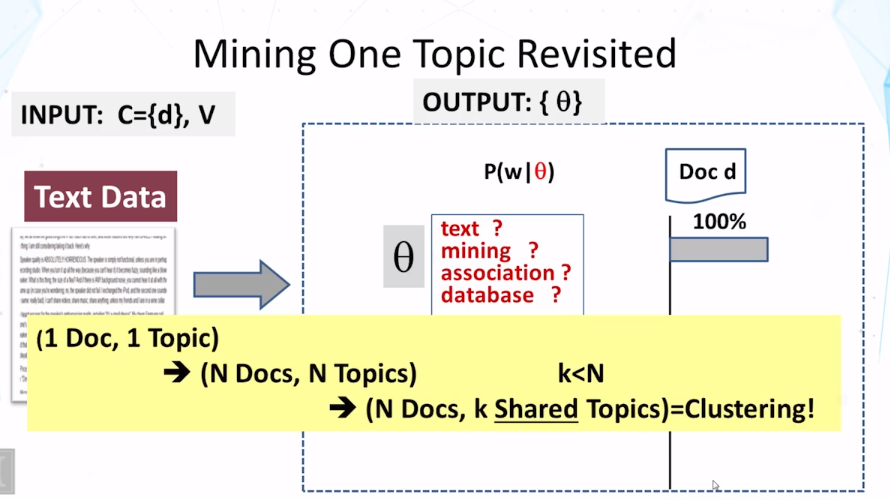
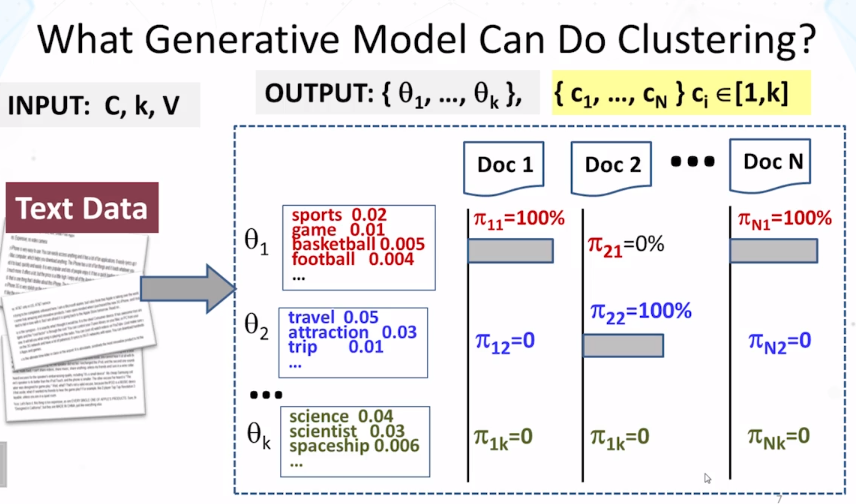
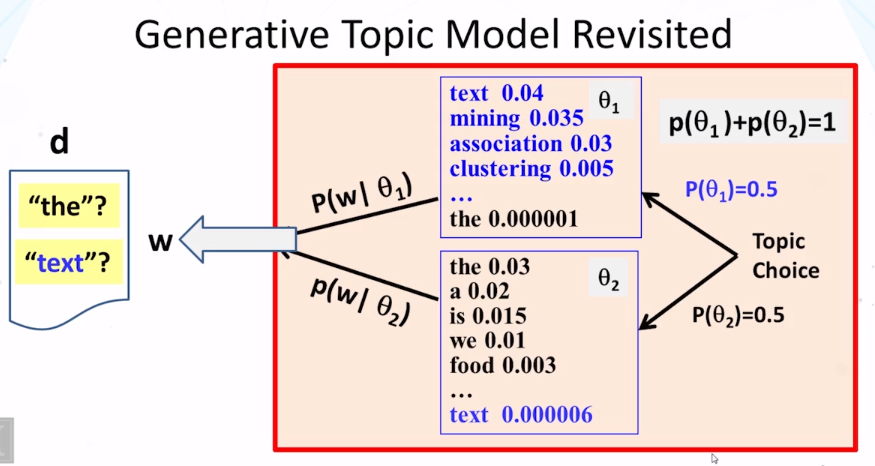
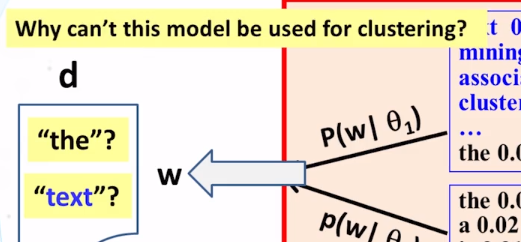
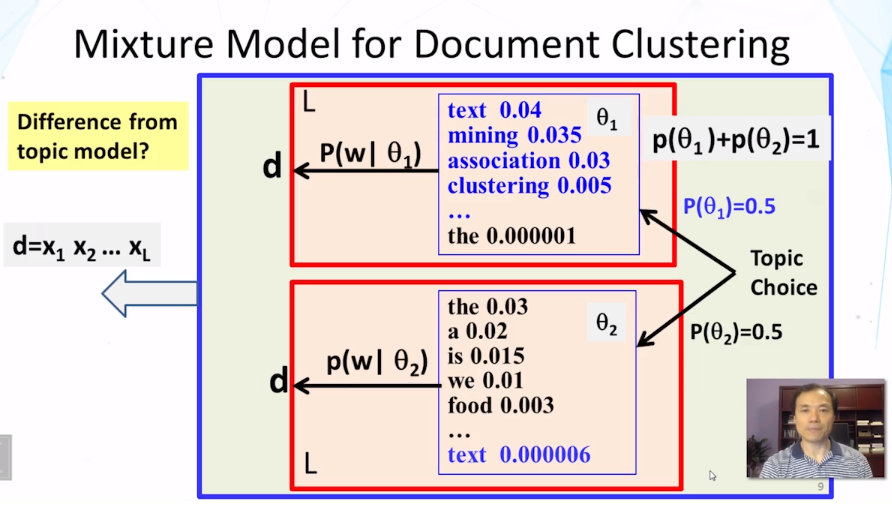
- differences between mixture and topic model:
- choice of using a distribution is made once in mixture model , but made multiple times in topic model
- document clustering has word distribution used to regenerate all the words for a document, But, in the case of one distribution doesn’t have to generate all the words in the document. Multiple distribution could have been used to generate the words in the document.


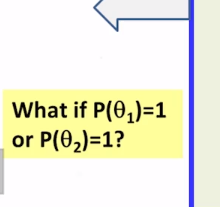


10-1-3 Generative Probabilistic Models Part 2



10-1-4 Generative Probabilistic Models Part 3




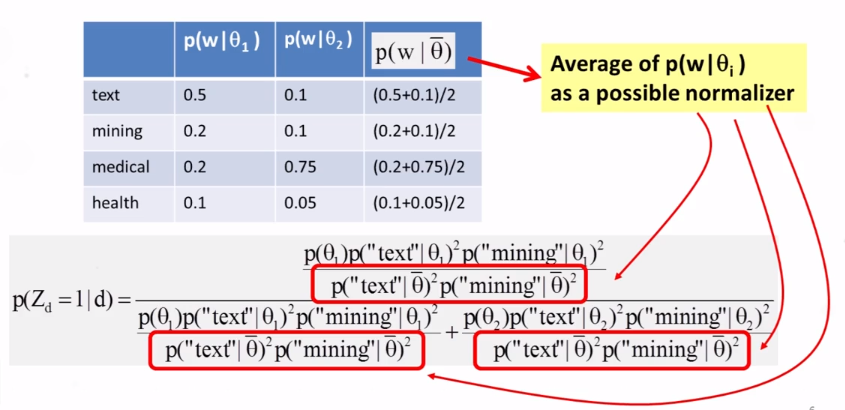



10-1-5 Similiarity Based Approaches




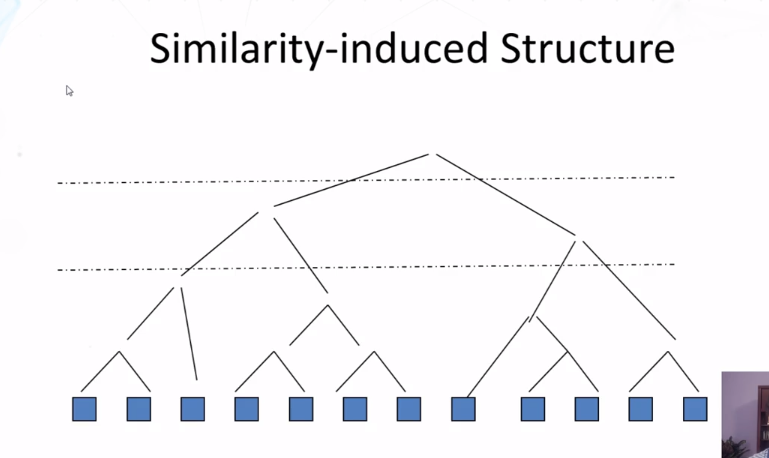

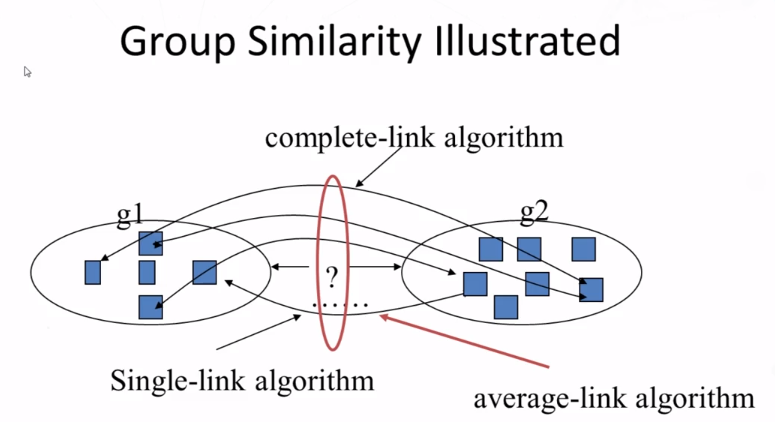



10-1-6 Evaluation





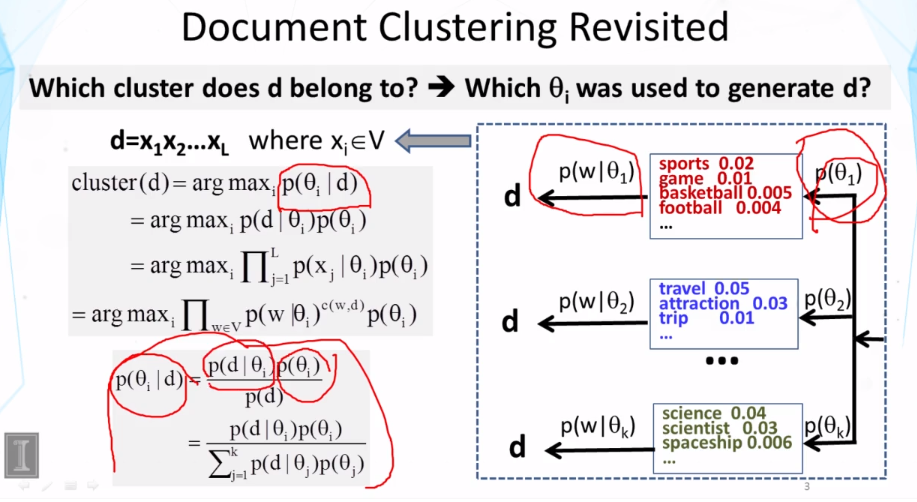
10-2 Text Categorization
10-2-1 Motivation




10-2-2 Methods








10-2-3 Generative Probabilistic Models
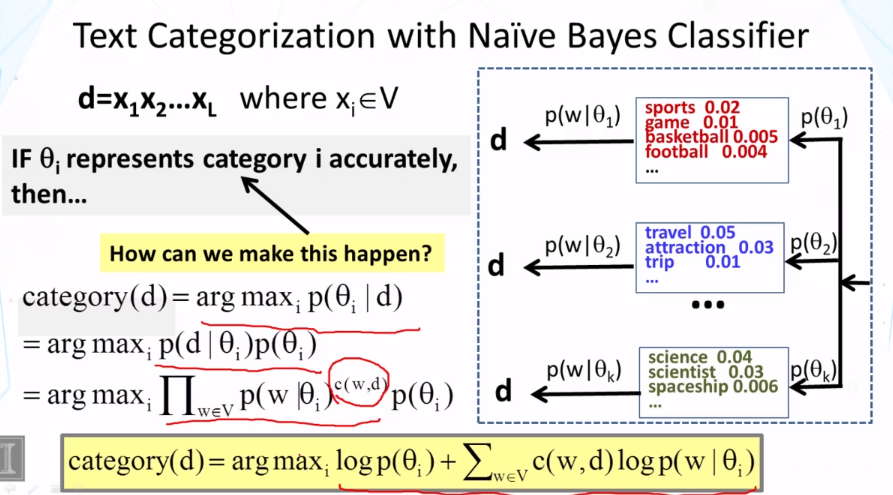
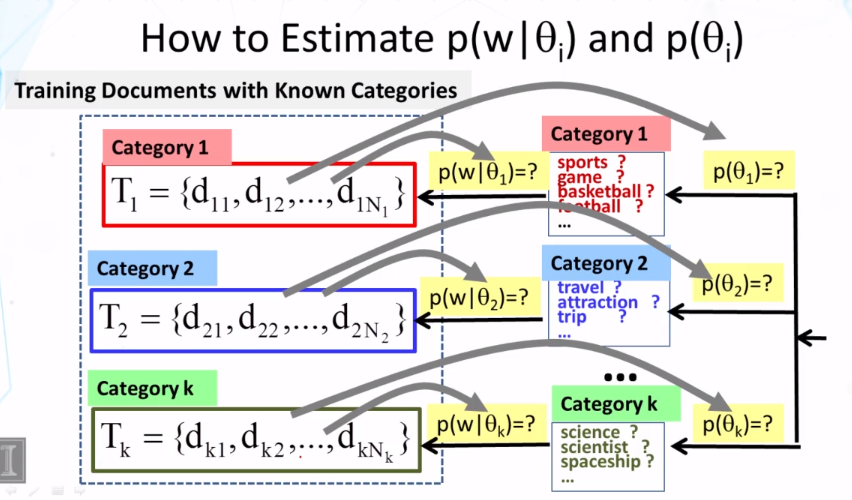


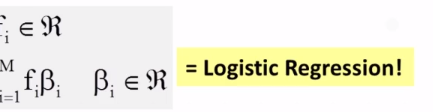
CS 425 Distributed Systems
Goals
- Know how Remote Procedure Calls (RPCs) work.
- Check a run of transactions for correctness (serial equivalence).
- Design systems that use optimistic or pessimistic approaches to ensure correctness in spite of many concurrent clients.
- Detect and avoid deadlocks.
- Calculate nines availability for a replicated system.
- Know how to ensure correctness (consistency) in spite of multiple servers.
Key Concepts
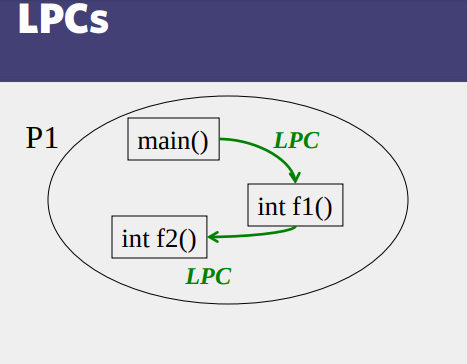
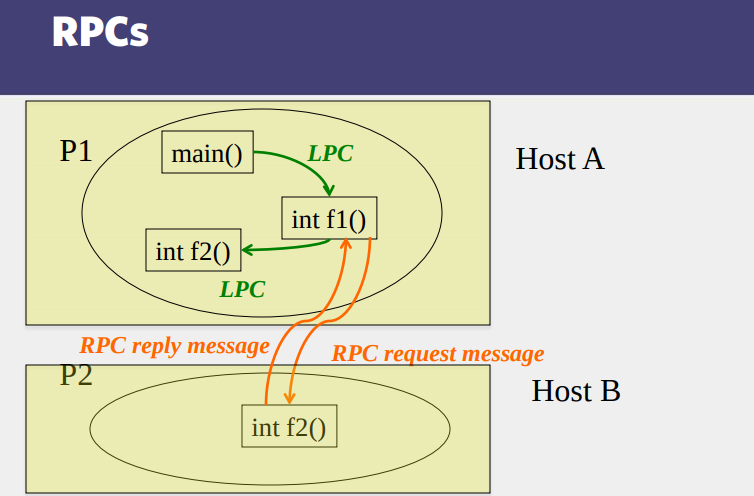
- LPCs vs RPCs
- Marshaling
- Serial Equivalence
- Pessimistic Concurrency Control
- Optimistic Concurrency Control
- Deadlocks and their detection/avoidance/prevention
- ACID Properties
- Nines Availability
- Active and Passive Replication
- Two-phase commit
Guiding Questions
- Does an RPC always cross machine boundaries?
- Why is marshaling needed at all?
- What are conflicting operations and how can you use them to detect serial equivalence among transactions?
- Is locking a form of pessimistic or optimistic concurrency control?
- Does Google docs use pessimistic or optimistic concurrency control?
- What is one way to prevent deadlocks among transactions?
- What does “three nines availability” really mean?
- Why is Two-phase commit preferable over One-phase commit?
Readings and Resources
- There are no readings required for this week.
Video Lecture Notes
Concurrency Control
RPCs






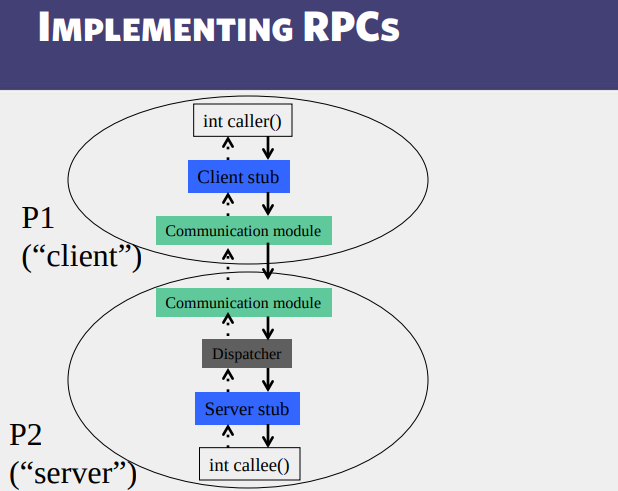
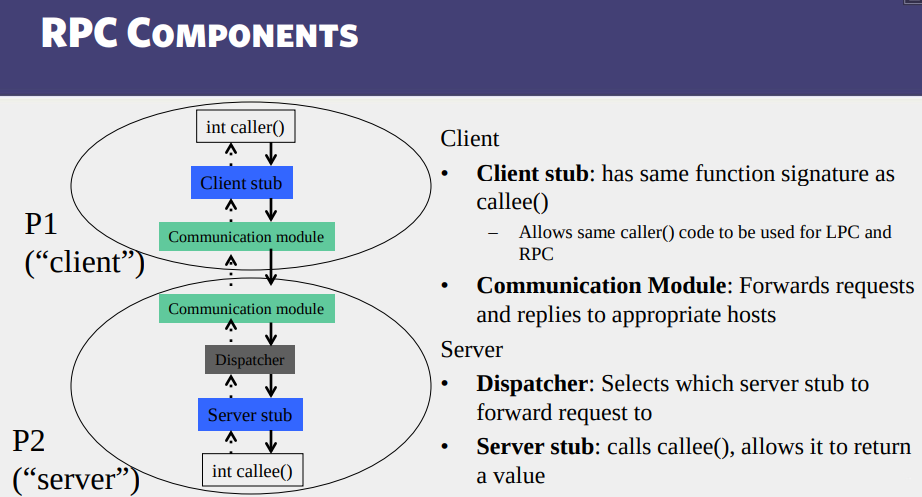





Transactions








Serial Equivalence








Pessimistic Concurrency














Optimistic Concurrency Control








Replication Control
Replication



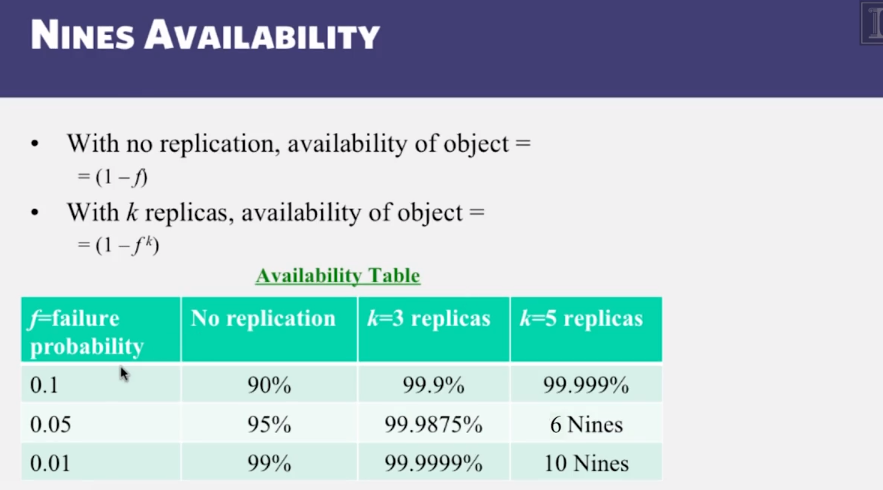

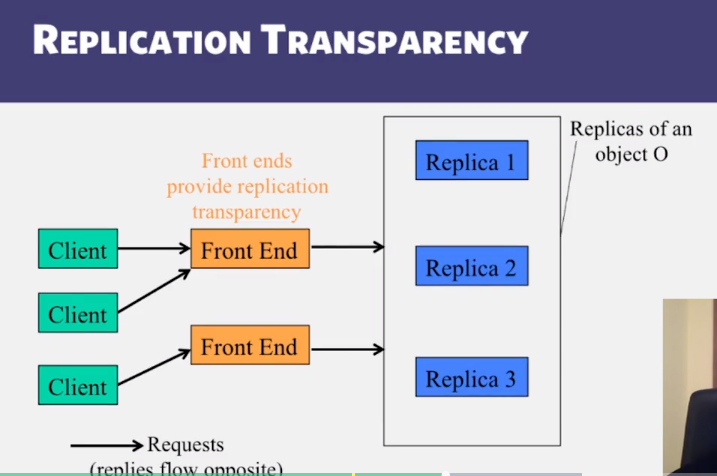

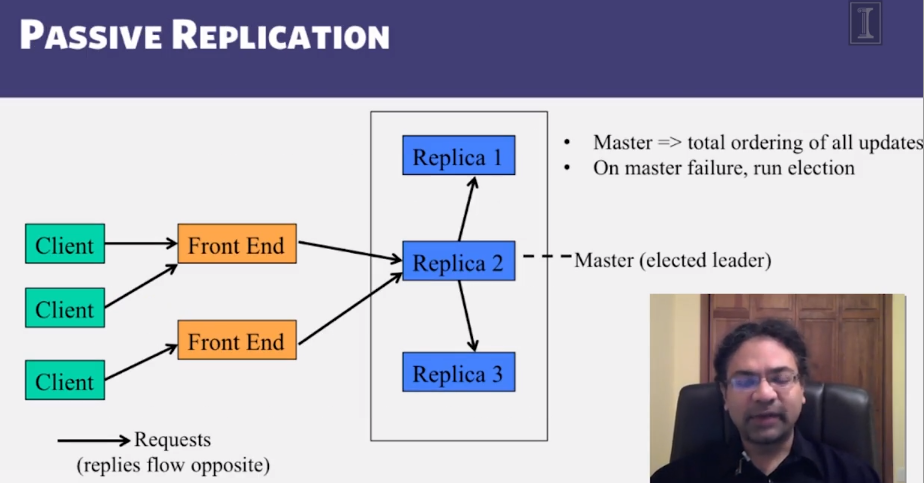
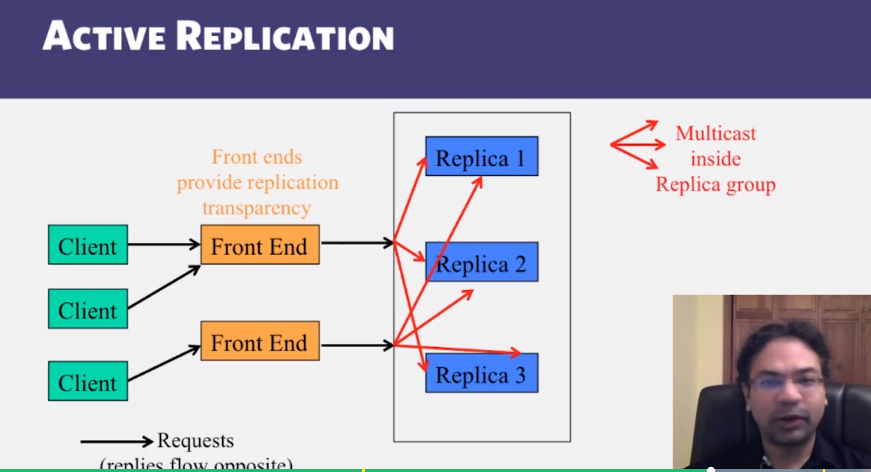


Two-Phase Commit
CS 427 Software Engineering
Goals and Objectives
Video Lecture Notes
JUnit
Unit Testing







Junit Overview





JUnit Assertions


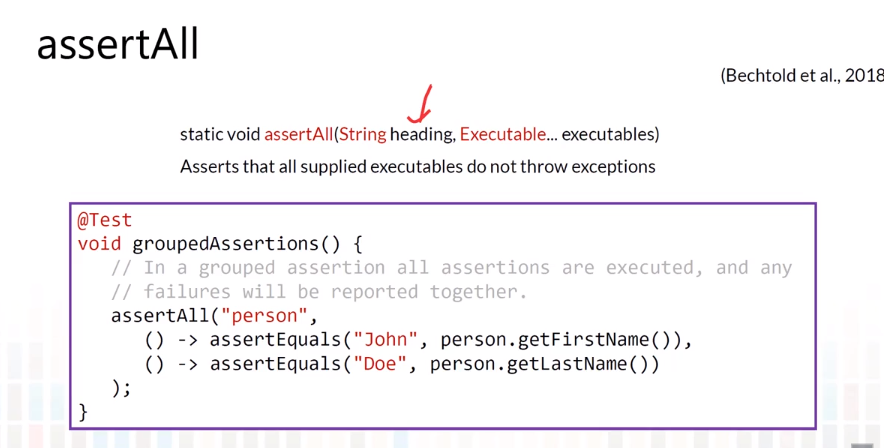


JUnit Assumptions





Parameterized Tests
Basics







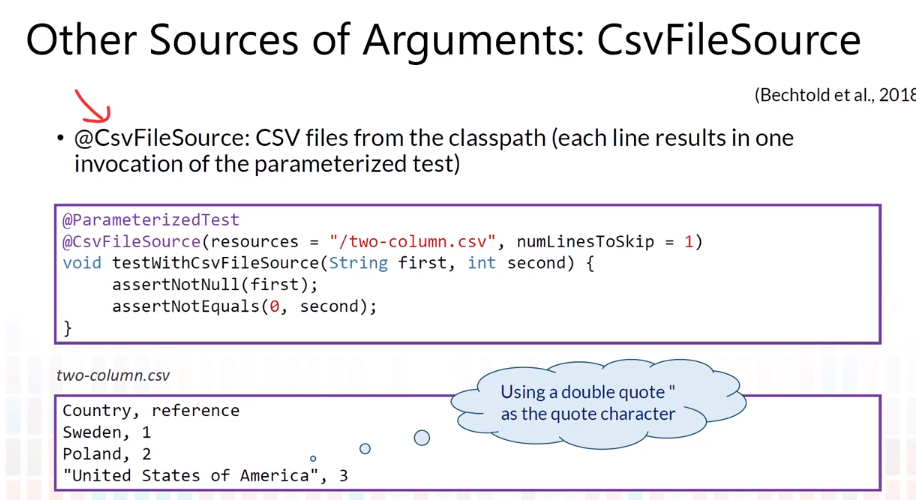


Complex Parameters







Writing Parameterized Tests












Test Generalization








