- CS 410 Text Information Systems
- Goals and Objectives
- Guiding Questions
- Additional Readings and Resources
- Key Phrases and Concepts
- Video Lecture Notes
- CS 425 Distributed Systems
- CS 427 Software Engineering
CS 410 Text Information Systems
Goals and Objectives
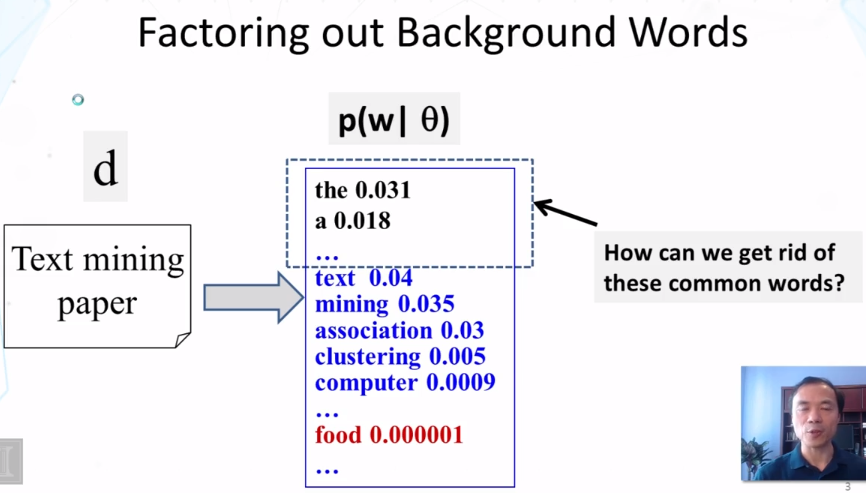
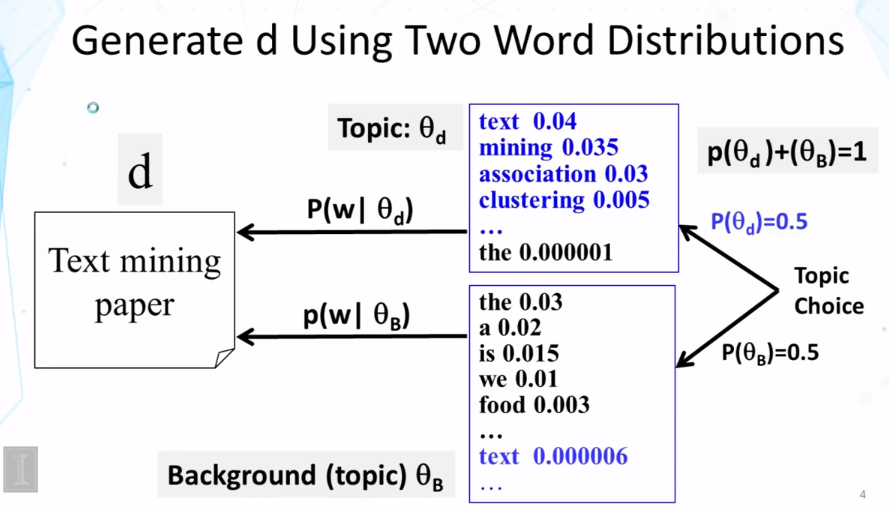
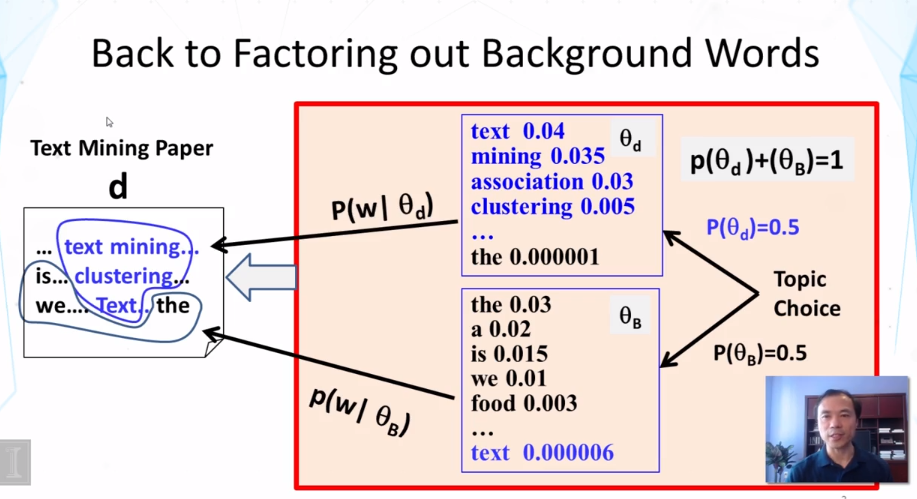
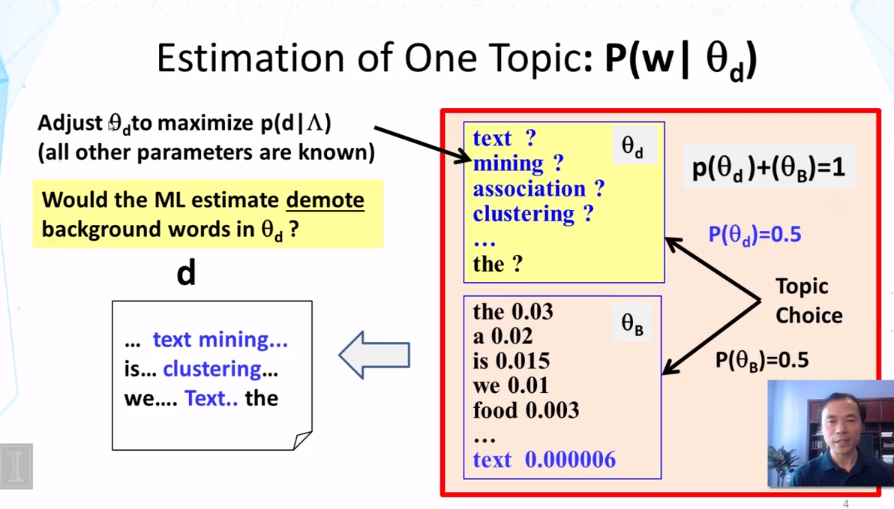
Explain what a mixture of unigram language model is and why using a background language in a mixture can help “absorb” common words in English.
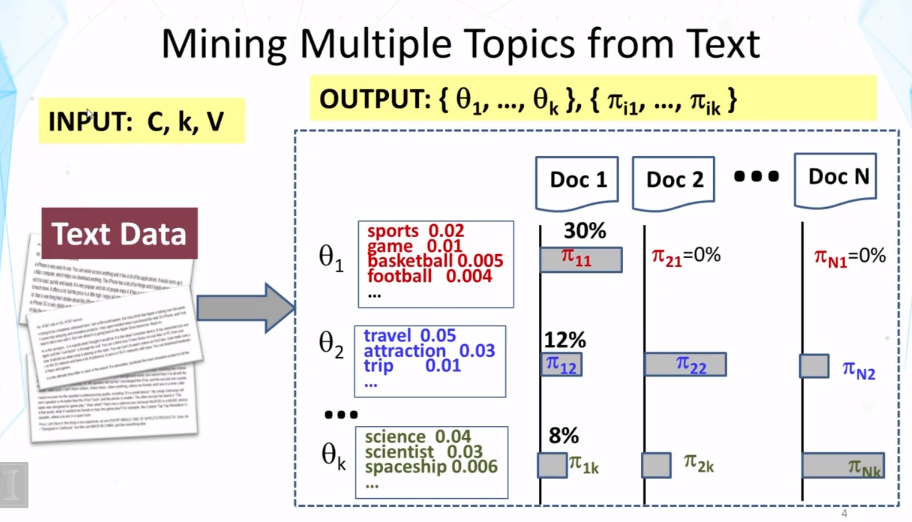
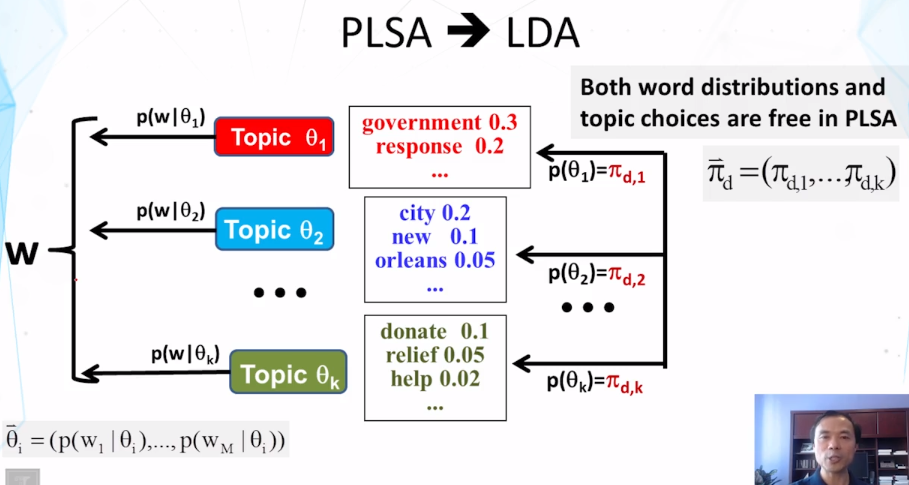
Explain what PLSA is and how it can be used to mine and analyze topics in text.
Explain the general idea of using a generative model for text mining.
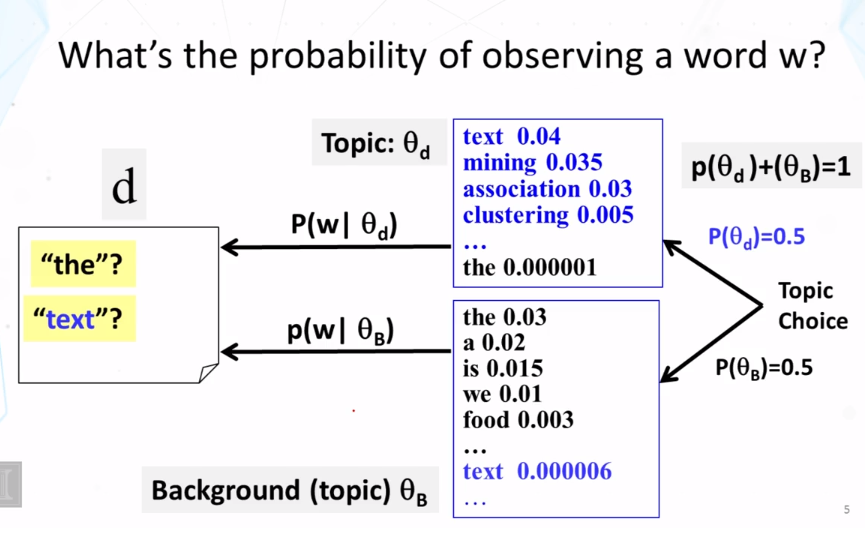
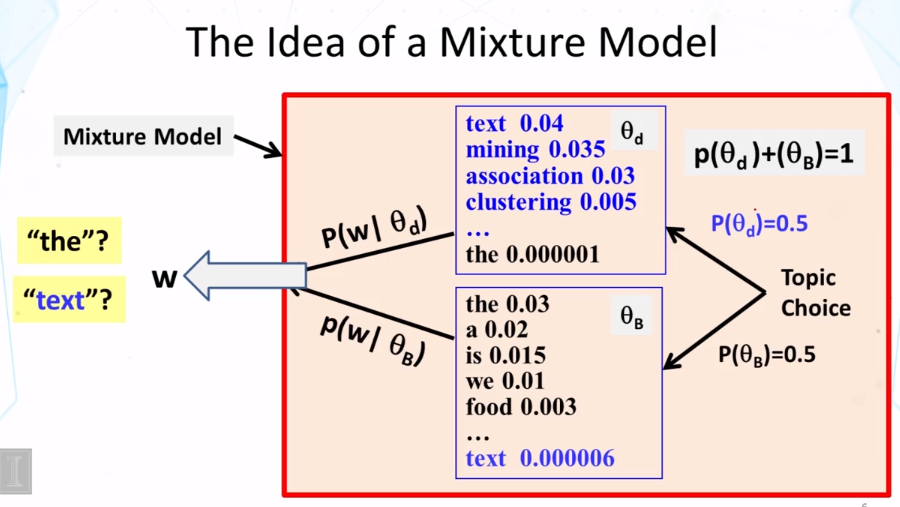
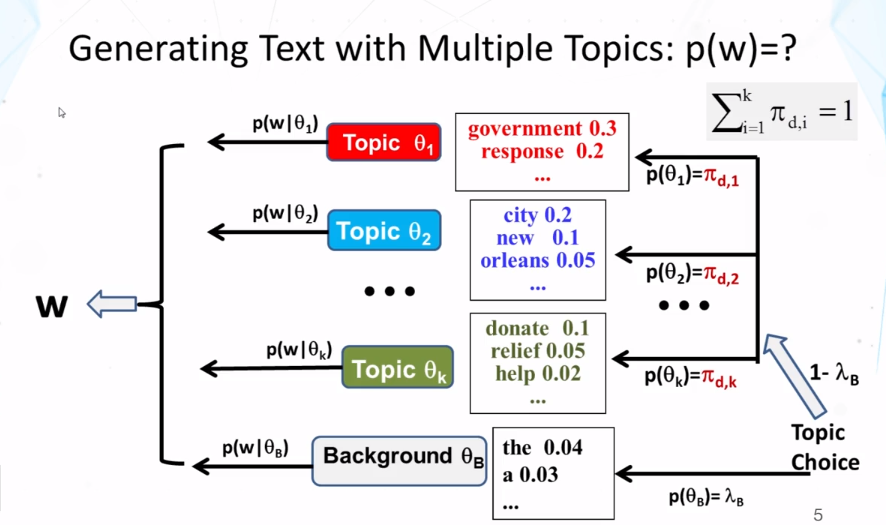
Explain how to compute the probability of observing a word from a mixture model like PLSA.
Explain the basic idea of the EM algorithm and how it works.
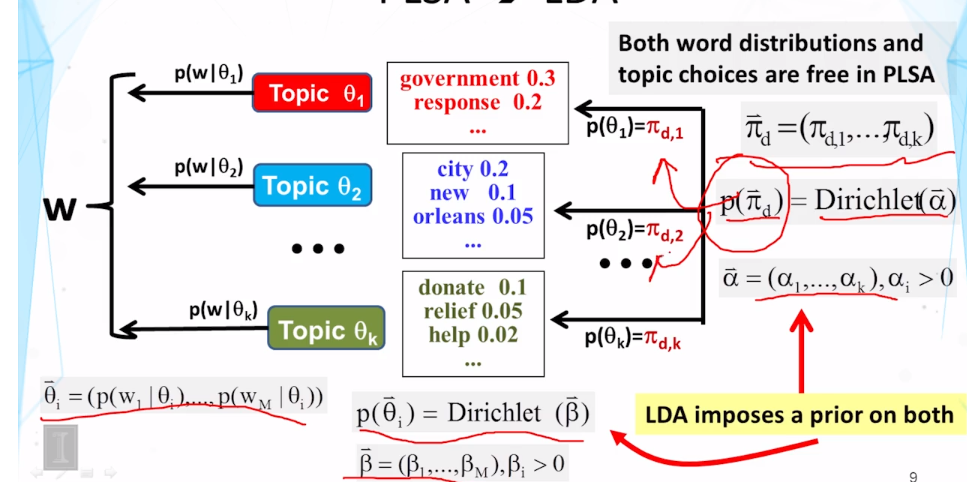
Explain the main difference between LDA and PLSA.
Guiding Questions
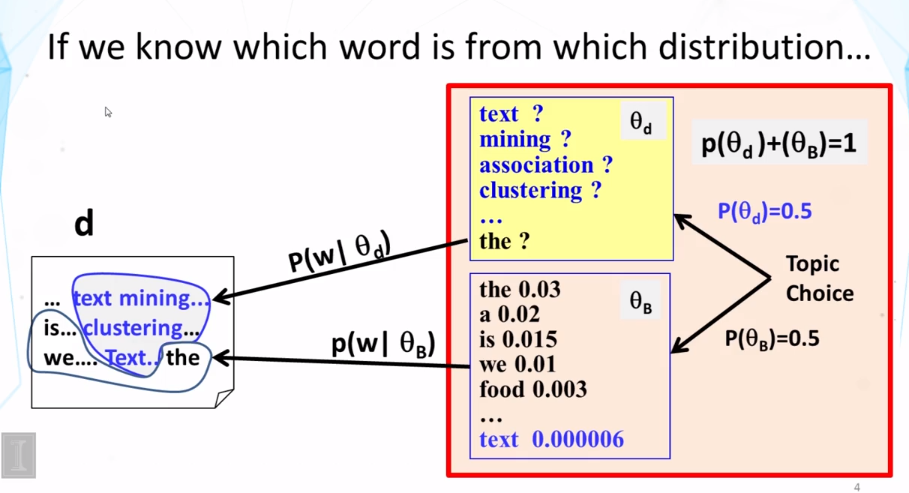
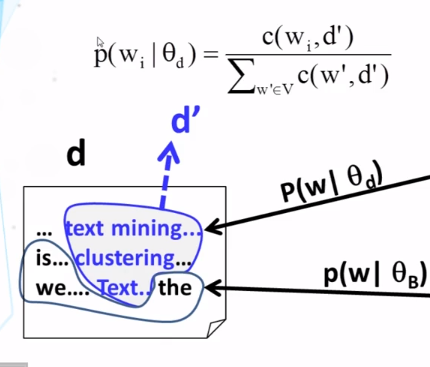
What is a mixture model? In general, how do you compute the probability of observing a particular word from a mixture model? What is the general form of the expression for this probability?
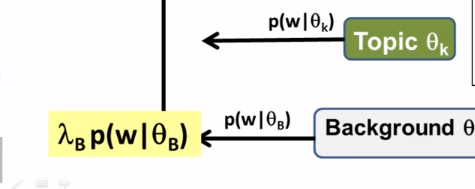
What does the maximum likelihood estimate of the component word distributions of a mixture model behave like? In what sense do they “collaborate” and/or “compete”? Why can we use a fixed background word distribution to force a discovered topic word distribution to reduce its probability on the common (often non-content) words?
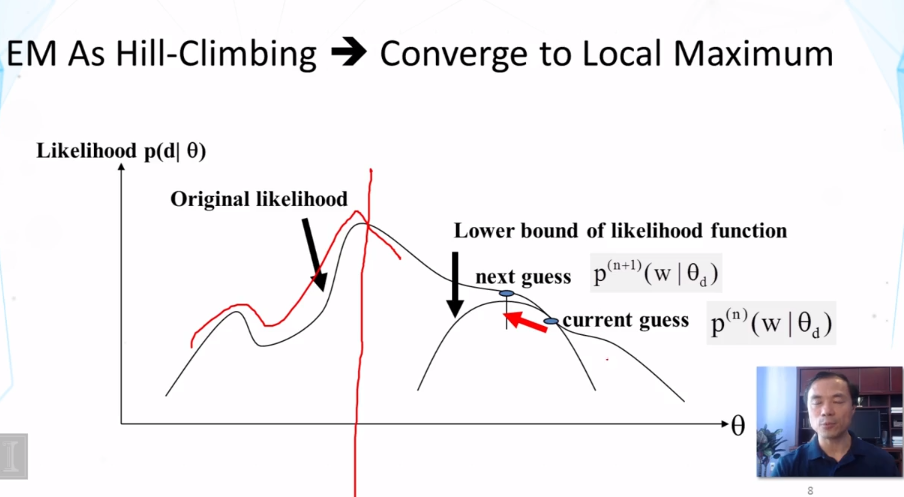
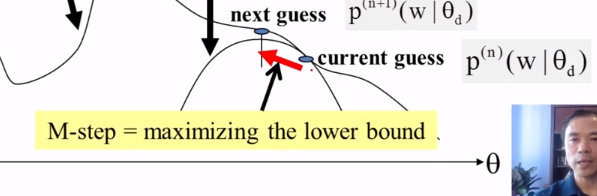
What is the basic idea of the EM algorithm? What does the E-step typically do? What does the M-step typically do? In which of the two steps do we typically apply the Bayes rule? Does EM converge to a global maximum?
What is PLSA? How many parameters does a PLSA model have? How is this number affected by the size of our data set to be mined? How can we adjust the standard PLSA to incorporate a prior on a topic word distribution?
How is LDA different from PLSA? What is shared by the two models?
Additional Readings and Resources
C. Zhai and S. Massung, Text Data Management and Analysis: A Practical Introduction to Information Retrieval and Text Mining. ACM and Morgan & Claypool Publishers, 2016. Chapter 17.
Blei, D. 2012. Probabilistic Topic Models. Communications of the ACM 55 (4): 77–84. doi: 10.1145/2133806.2133826.
Qiaozhu Mei, Xuehua Shen, and ChengXiang Zhai. Automatic Labeling of Multinomial Topic Models. Proceedings of ACM KDD 2007, pp. 490-499, DOI=10.1145/1281192.1281246.
Yue Lu, Qiaozhu Mei, and Chengxiang Zhai. 2011. Investigating task performance of probabilistic topic models: an empirical study of PLSA and LDA. Information Retrieval, 14, 2 (April 2011), 178-203. doi: 10.1007/s10791-010-9141-9.
Key Phrases and Concepts
Mixture model
Component model
Constraints on probabilities
Probabilistic Latent Semantic Analysis (PLSA)
Expectation-Maximization (EM) algorithm
E-step and M-step
Hidden variables
Hill climbing
Local maximum
Latent Dirichlet Allocation (LDA)
Video Lecture Notes
9-1 Probabalistic Topic Models
9-1-1 Mixture of Unigram Language Models


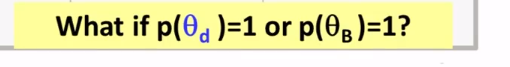

9-1-2 Mixture Model Estimation Part 1


9-1-3 Mixture Model Estimation Part 2
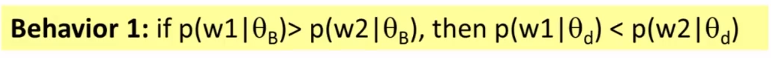




9-1-4 Expectation Maximization Algorithm Part 1

9-1-5 Expectation Maximization Algorithm Part 2

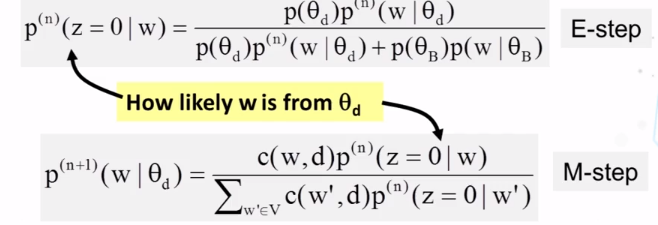

9-1-6 Expectation Maximization Algorithm Part 3


9-2 Probabalistic Latent Semantic Analysis PLSA Part 1

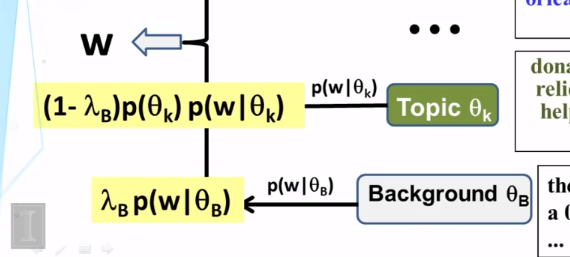
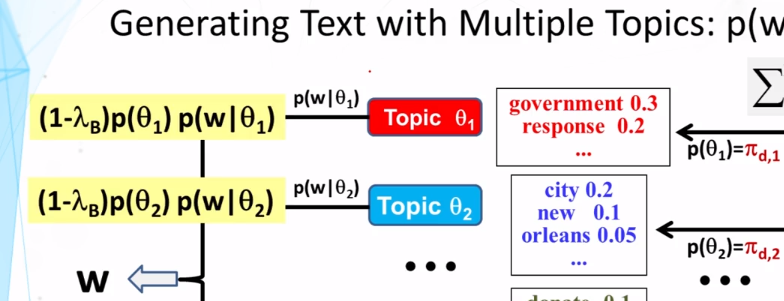
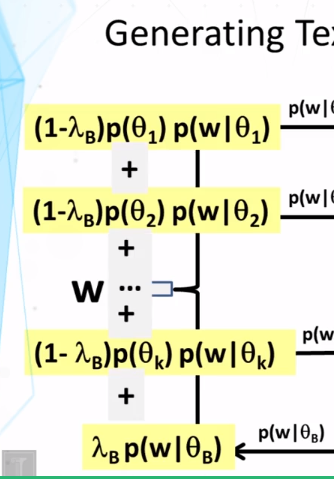



9-3 Probabalistic Latent Semantic Analysis PLSA Part 2

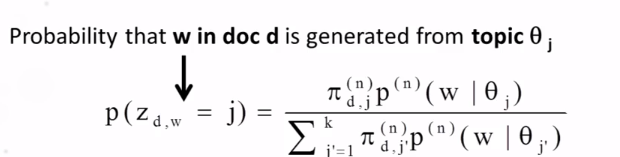
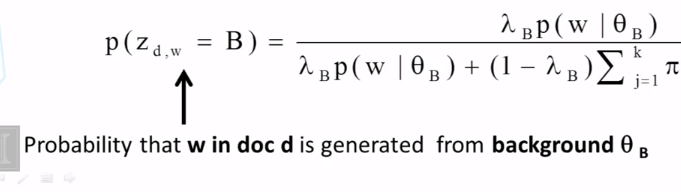


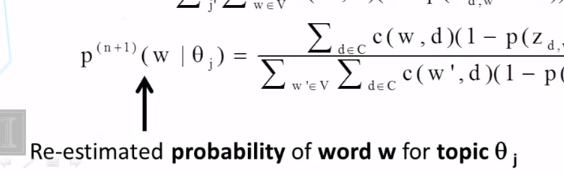





9-4 Latent Dirichet Allocation LDA Part 1







9-5 Latent Dirichet Allocation LDA Part 2





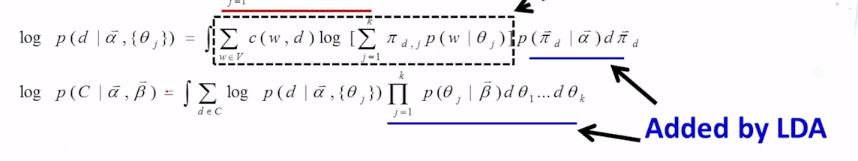


CS 425 Distributed Systems
Goals
- Design Leader Election algorithms including Ring algorithm and Bully algorithm.
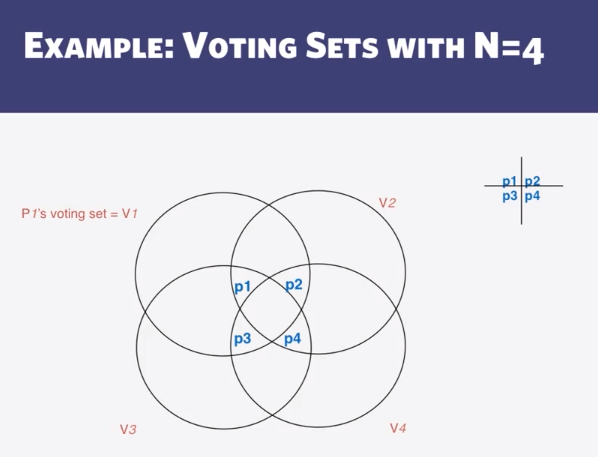
- Design Mutual Exclusion algorithms including Ricart-Agrawala’s algorithm and Maekawa’s algorithm.
- Know the design of Leader Election used in industry systems: Google’s Chubby system and Apache Zookeeper.
- Know how industry systems like Google’s Chubby support mutual exclusion.
Key Concepts
- Google Chubby Leader Election
- Apache Zookeeper Leader Election
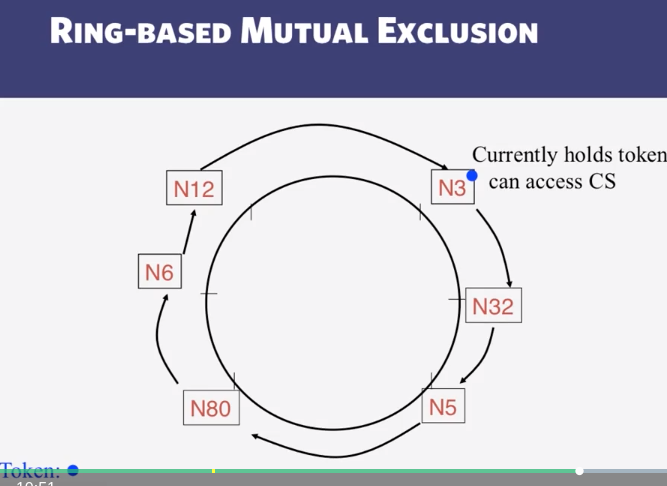
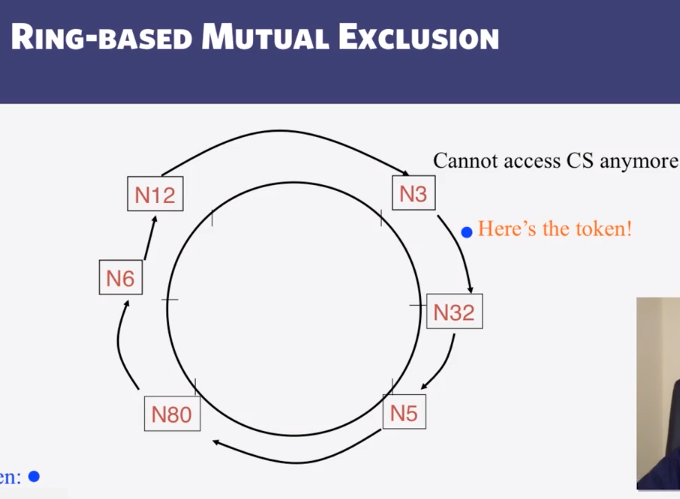
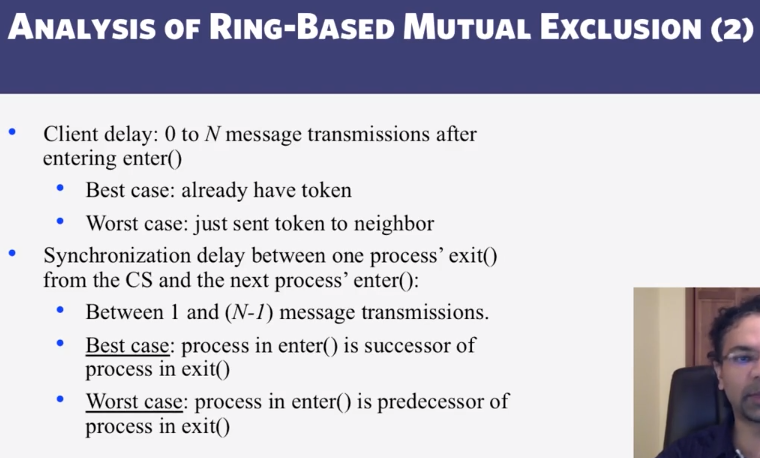
- Ring Mutual Exclusion
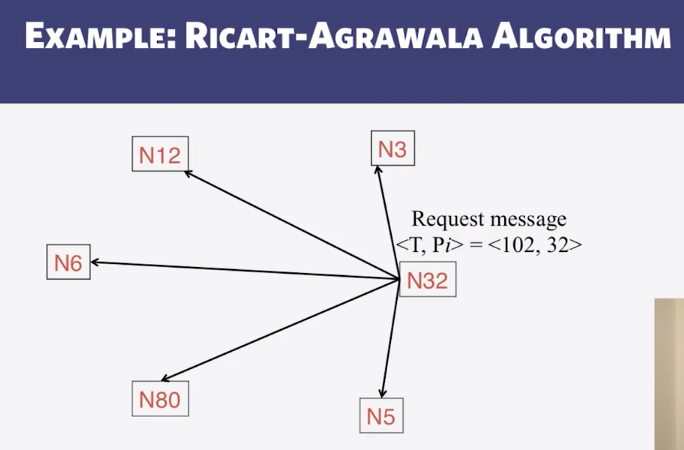
- Ricart-Agrawala’s Mutual Exclusion
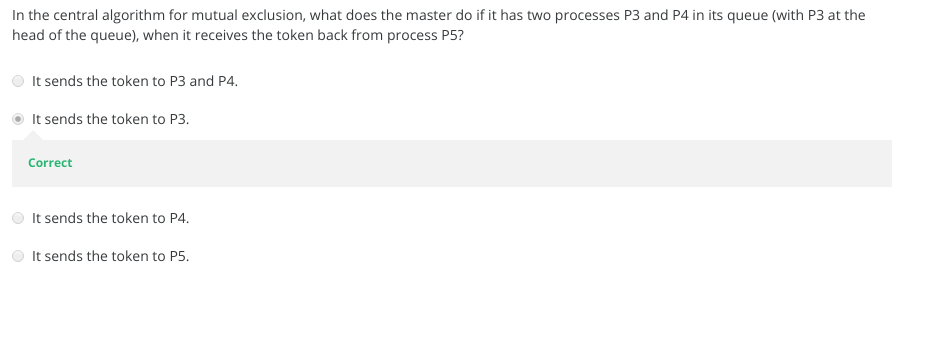
- Maekawa Mutual Exclusion
Guiding Questions
- What are the safety and liveness conditions for Leader Election?
- Why is Leader Election hard?
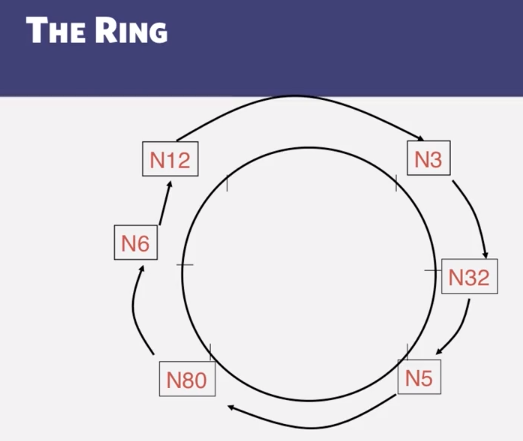
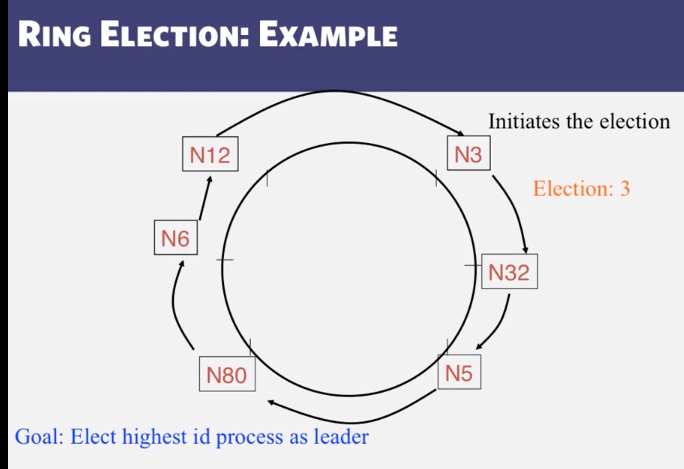
- How long does the Ring Election algorithm take to complete?
- How long does the Bully Election algorithm take to complete?
- How does Google Chubby use quorums for election?
- What are the safety and liveness conditions for Mutual Exclusion?
- How do semaphores work?
- How long does the Ring Mutual Exclusion algorithm take to complete?
- How long does the Ricart-Agrawala’s algorithm take to complete?
- Why is Maekawa’s algorithm “optimal”?
- How does Google Chubby use quorums for mutual exclusion?
Readings and Resources
- (Optional, fun video) Amazon Web Services (AWS) Training Videos
Video Lecture Notes
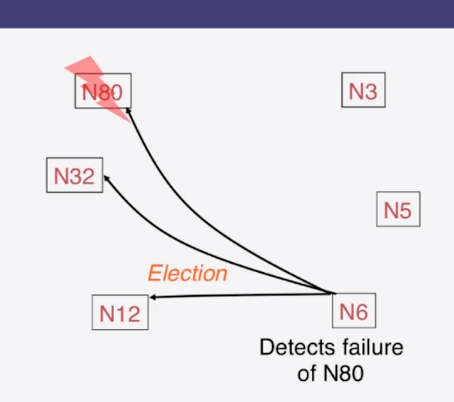
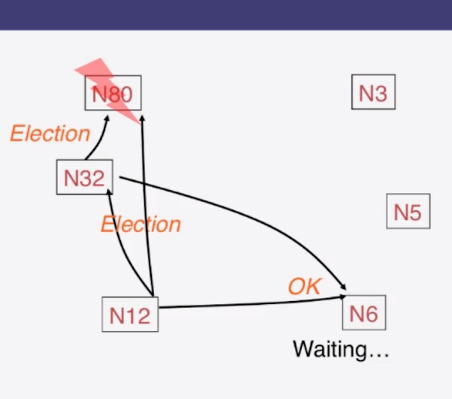
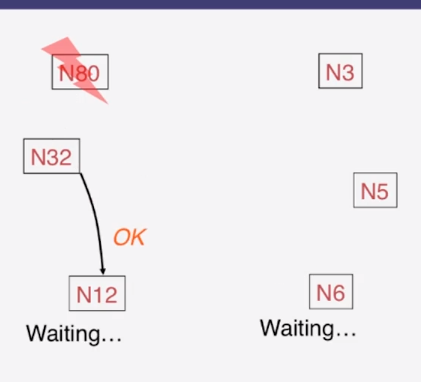
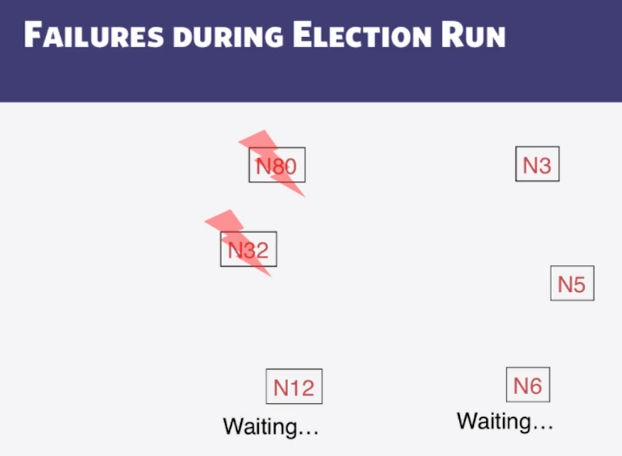
9-1-1 The Election Problem






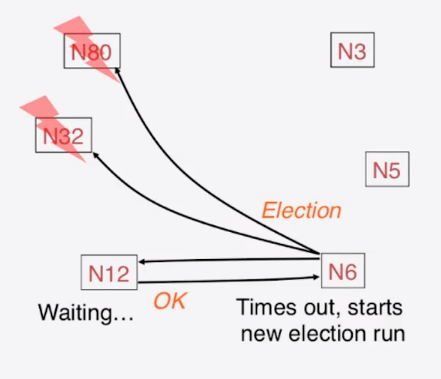
9-1-2 Ring Leader Election



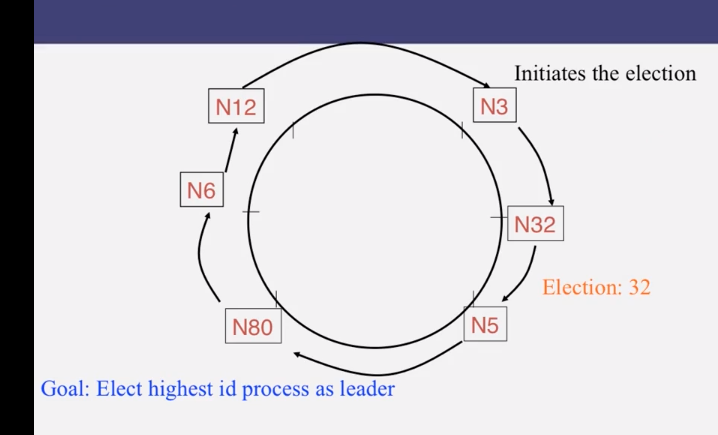
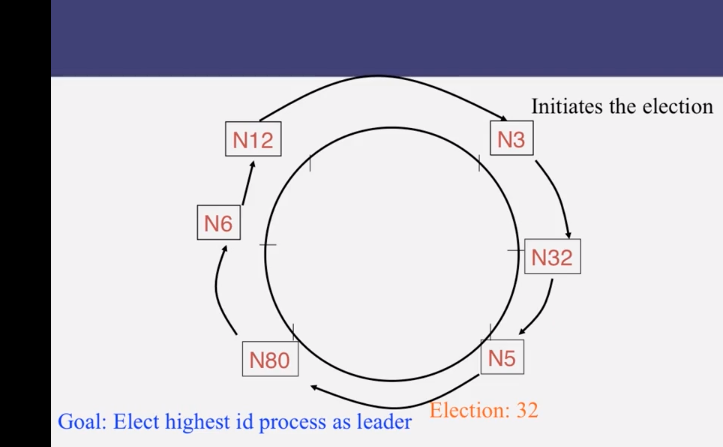
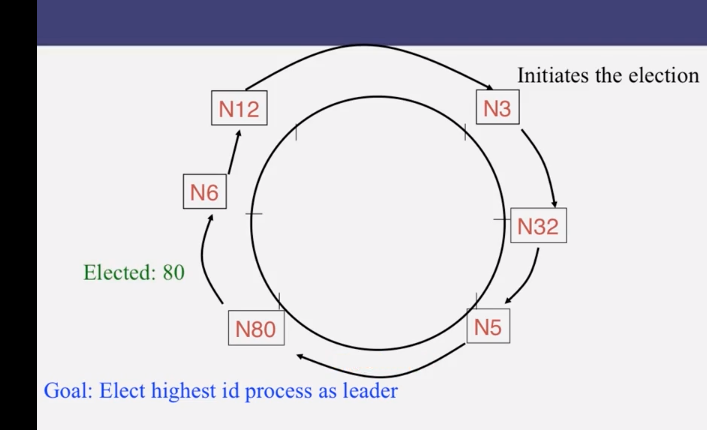
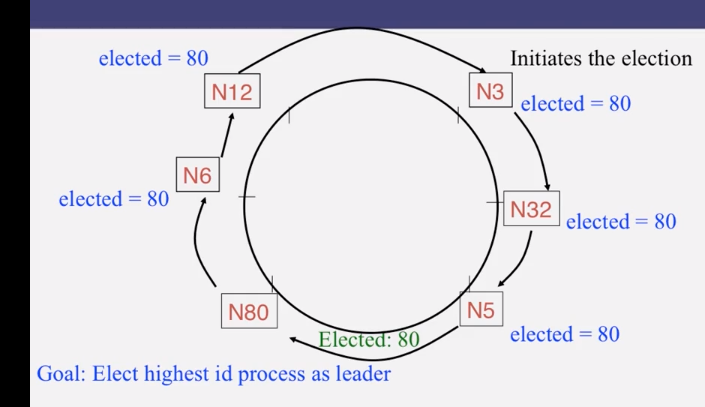




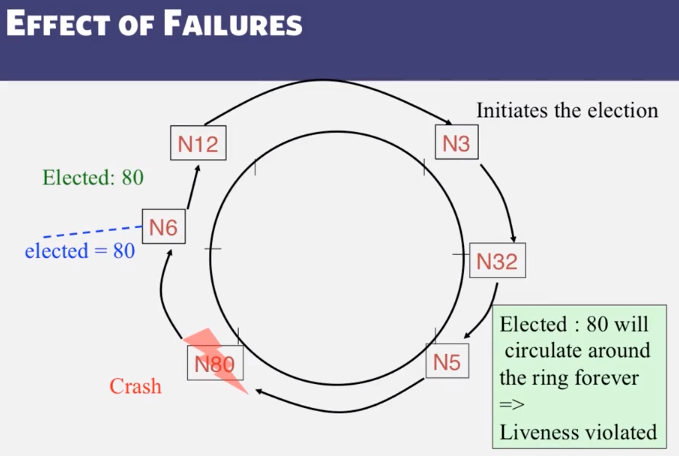



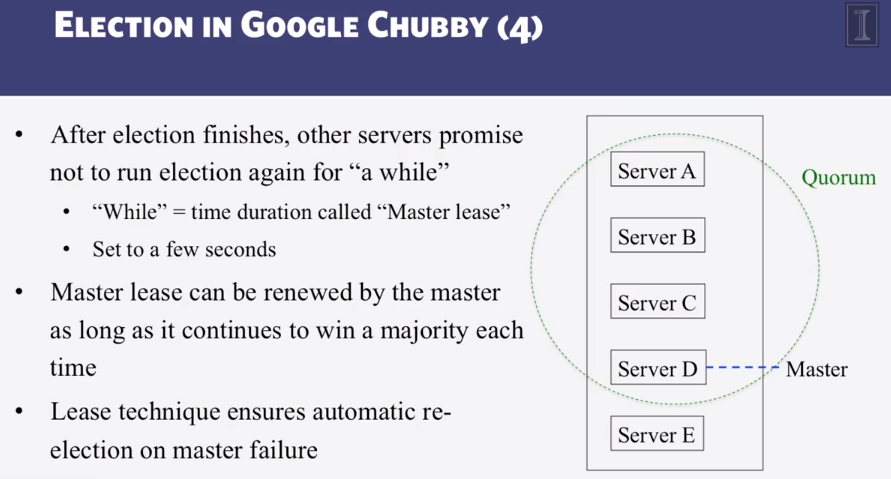
9-1-3 Election in Chubby








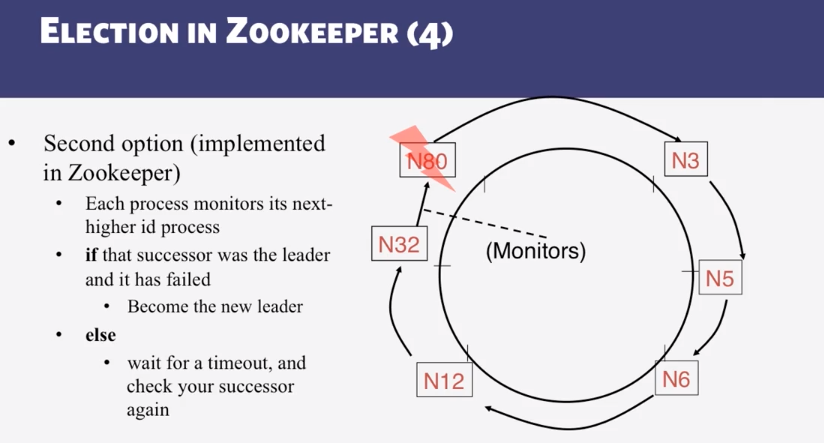

9-1-4 Bully Algorithm







9-2-1 Introduction and Basics








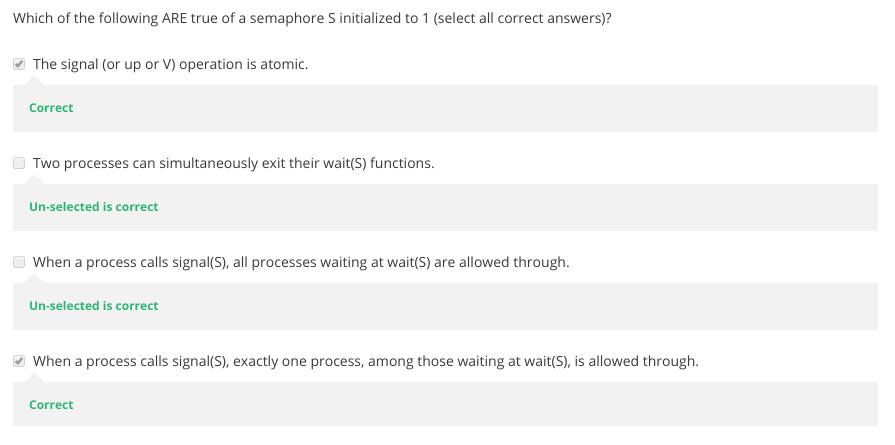

9-2-2 Distributed Mutual Exclusion









9-2-3 Ricart Agrawalas Algorithm




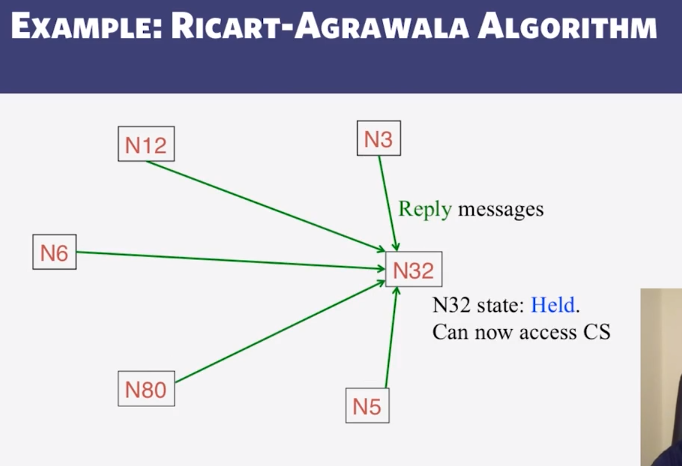
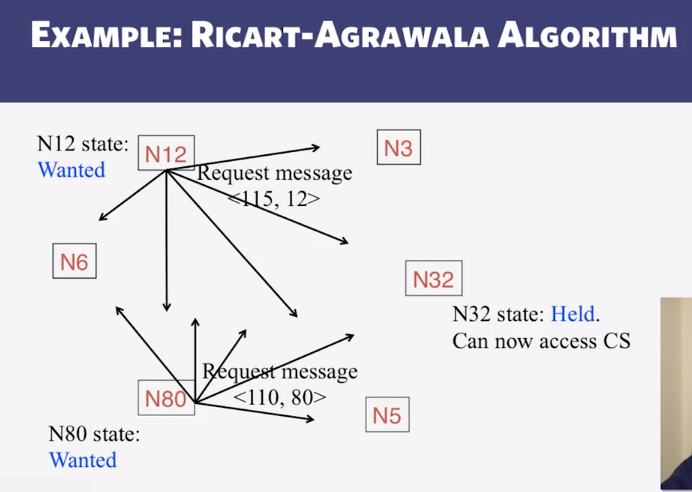
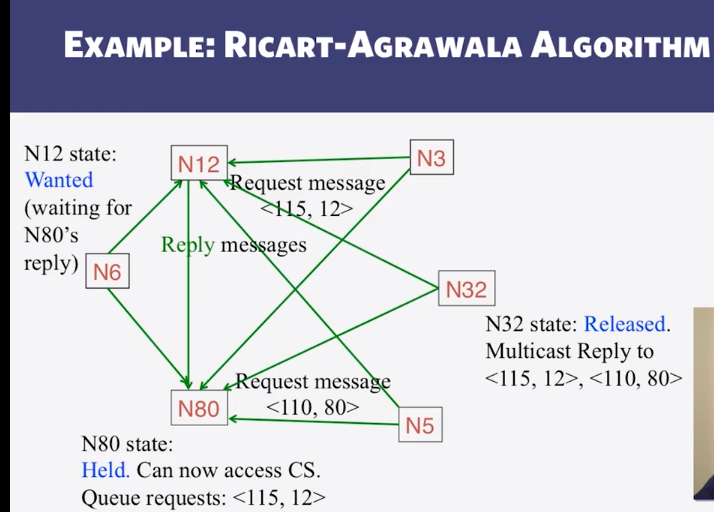



9-2-4 Maekawas Algorithm and WrapUp


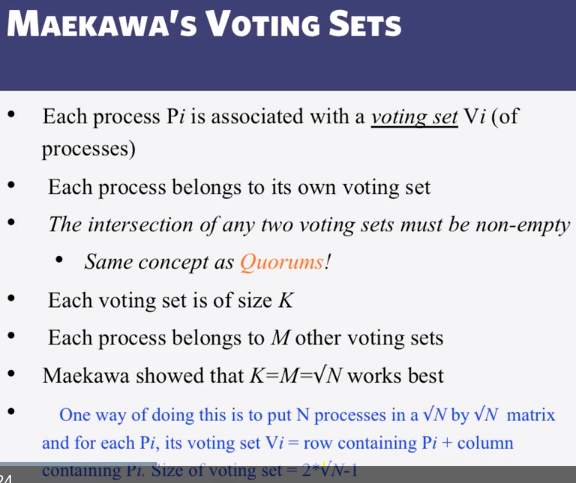











CS 427 Software Engineering
Goals and Objectives
- Explain what is validation and verification, respectively.
- Classify a given activity into validation or verification.
- Explain why conduct testing, who write tests, when to write tests, and when to run tests, respectively
- Explain what a test case consists of
- Explain when to use automated tests in contrast to manual tests, and when to use manual tests in contrast to automated tests.
- Explain the purpose of the given kind of tests.
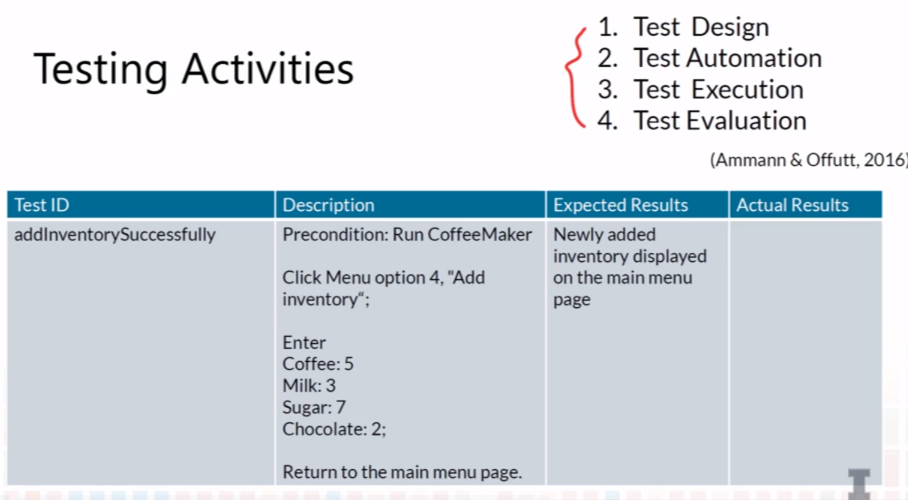
- List the four types of testing activities, and explain their differences
- List the type of knowledge needed by each of the four types of testing activities
- Explain the differences between mistake, fault, erroro, and failure.
- Classify a given case into mistake, fault, error, or failure
- Explain the three conditions illustrated in the PIE model
- Use the PIE model to explain why covering every statement in the software under test is necessary
- Use the PIE model to explain why even covering every statement in the software under test is not sufficient.
- Conduct equivalence partitioning given requirements
- Conduct boundary value analysis given requirements
- Conduct black-box testing given a program under test.
- Explain the type of faults that black-box testing is good at detecting while white-box testing is not.
- Explain the type of faults that white-box testing is good at detecting while black-box testing is not.
- Explain differences between the given major types of code coverage
- Measure code coverage of the given program under test by the given test input values with respect to the given type of code coverage
- Generate test input values to achieve 100% coverage of the given program under test with respect to the given type of code coverage.
Video Lecture Notes
9-6-1 Testing Overview
- Can write tests pretty much at any point in the Waterfall design cycle.




9-6-2 Test Cases







9-6-3 Testing Activities

9-6-4 Relating Fault and Failure




- Fault: erroneous piece of code
- Error: an unexpected result/output of code
- Failure: crashes that occur as a result of bad code.
- see here for paper on PIE…
9-6-5 Black Box Testing








9-6-6 White Box Testing



9-6-7 Code Coverage








