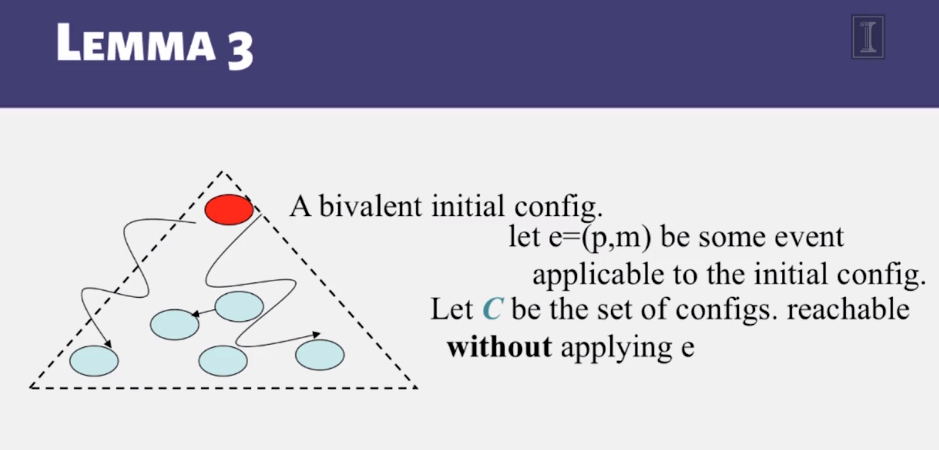
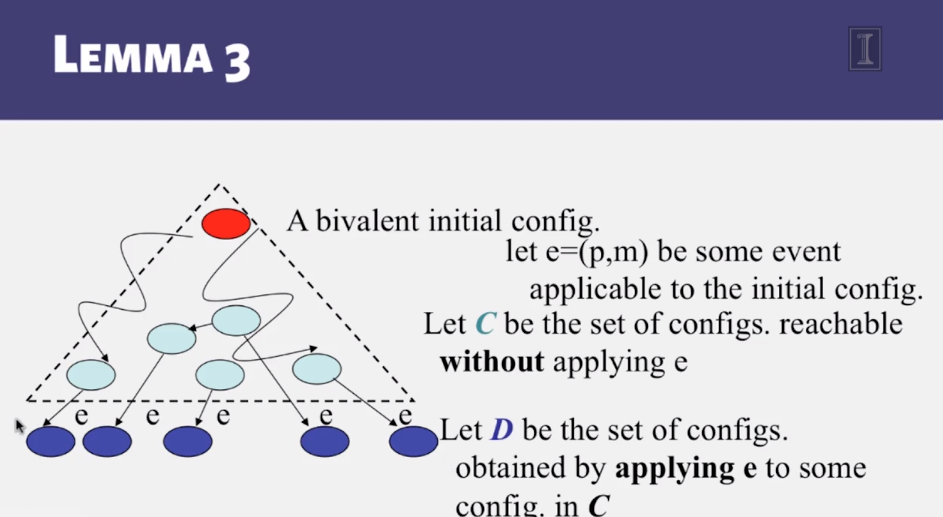
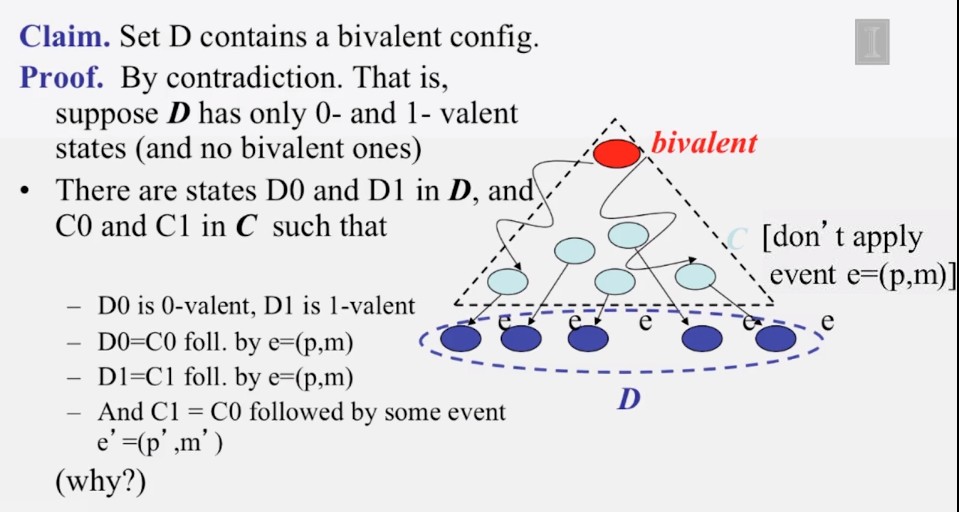
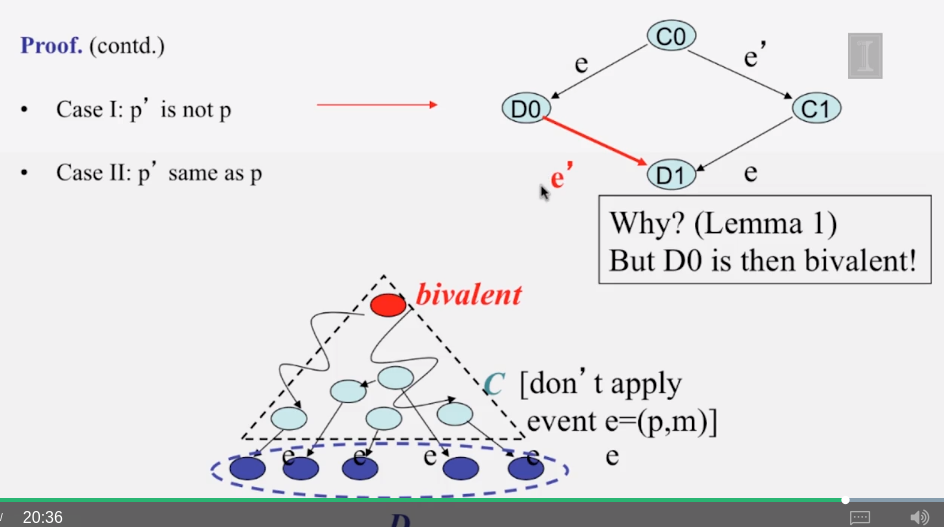
- CS 410 Text Information Systems
- Goals and Objectives
- Guiding Questions
- Additional Readings and Resources
- Key Phrases and Concepts
- Video Lecture Notes
- 6-1 Learning to Rank Part 1
- 6-2 Learning to Rank Part 2
- 6-3 Learning to Rank Part 3
- 6-4 Future of Web Search
- 6-5 Recommender Systems-Content-Based Filtering Part 1
- 6-6 Recommender Systems-Content-Based Filtering Part 2
- 6-7 Recommender Systems-Collaborative Filtering Part 1
- 6-8 Recommender Systems-Collaborative Filtering Part 2
- 6-9 Recommender Systems-Collaborative Filtering Part 3
- CS 425 Distributed Systems
- Goals
- Key Concepts
- Guiding Questions
- Readings and Resources
- Video Lecture Notes
- 6-1-1 What is Global Snapshot
- 6-1-2 Glboal snapshot algorithm
- 6-1-3 Consistent cuts
- 6-1-4 Safety and liveness
- 6-2-1 Multicast ordering
- 6-2-2 Implementing Multicast Ordering 1
- 6-2-3 Implementing Multicast Ordering 2
- 6-2-4 Reliable Multicast
- 6-2-5 Virtual Synchrony
- 6-3-1 The Consensus Problem
- 6-3-2 Consensus in Synchronous Systems
- 6-3-3 Paxos put Simply
- 6-3-4 The FLP Proof
- CS 427 Software Engineering
CS 410 Text Information Systems
Goals and Objectives
- Explain how we can extend a retrieval system to perform content-based information filtering (recommendation).
- Explain how we can use a linear utility function to evaluate an information filtering system.
- Explain the basic idea of collaborative filtering.
- Explain how the memory-based collaborative filtering algorithm works.
Guiding Questions
- What is content-based information filtering?
- How can we use a linear utility function to evaluate a filtering system? How should we set the coefficients in such a linear utility function?
- How can we extend a retrieval system to perform content-based information filtering?
- What is the exploration-exploitation tradeoff?
- How does the beta-gamma threshold learning algorithm work?
- What is the basic idea of collaborative filtering?
- How does the memory-based collaborative filtering algorithm work?
- What is the “cold start” problem in collaborative filtering?
Additional Readings and Resources
- C. Zhai and S. Massung. Text Data Management and Analysis: A Practical Introduction to Information Retrieval and Text Mining, ACM Book Series, Morgan & Claypool Publishers, 2016. Chapters 10 - Section 10.4,Chapters 11
Key Phrases and Concepts
- Content-based filtering
- Collaborative filtering
- Beta-gamma threshold learning
- Linear utility
- User profile
- Exploration-exploitation tradeoff
- Memory-based collaborative filtering
- Cold start
Video Lecture Notes
6-1 Learning to Rank Part 1
- How can we combine many features? (learning to rank)
- General Idea:
- Given a query-doc pair (Q,D), define various kinds of features Xi(Q,D)
- Examples of feature: the number of overlapping terms, BM25 score of Q and D, p(Q|D), PageRank of D, p(Q|Di), where Di may be anchor text or big font text, “does the URL contain ‘~’?”…
- Hypothesize p(R=1|Q,D)=s(X1(Q,D)),…,Xn(Q,D),λ) where λ is a set of parameters
- Learn λ by fitting functions with training data, ie, 3-tuples like (D,Q,1)(Dis relevant to Q) or (D,Q,0)(D is non-relevant to Q)
- General Idea:
6-2 Learning to Rank Part 2

6-3 Learning to Rank Part 3
- More Advanced Learning Algorithms
- Attempt to directly optimize a retrieval measure (eg MAP, nDCG)
- More difficult as an optimization problem
- Many solutions were proposed
- Can be applied to many other ranking problems beyond search
- Recommender systems
- Computational advertising
- Summarization
- Attempt to directly optimize a retrieval measure (eg MAP, nDCG)
- Summary
- Machine Learning has been applied to text retrieval since many decades ago (eg, Rocchio feedback)
- Recent use of machine learning is driven by
- large-scale training data available
- need for combining many features
- need for robust ranking (again spams)
- Modern Web search engines all use some kind of ML technique to combine many features to optimize ranking
- Learning to ranki is still an active research topic
6-4 Future of Web Search
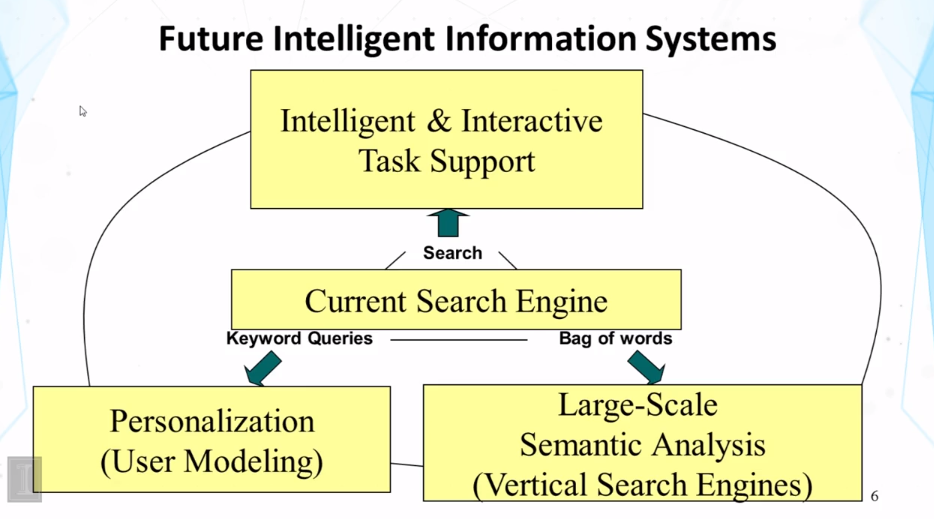
- Next generation search engines
- more specialized/customized (vertical search engines)
- special group of users (community engines, eg, Citeseer)
- Personalized (better understanding of users)
- Special genre/domain (better understanding of documents)
- Learning over time (evolving)
- Integration of search, navigation, and recommendation/filtering (full-fledged information management)
- Beyond search to support tasks (eg shopping)
- Many opportunities for innovations!
- more specialized/customized (vertical search engines)
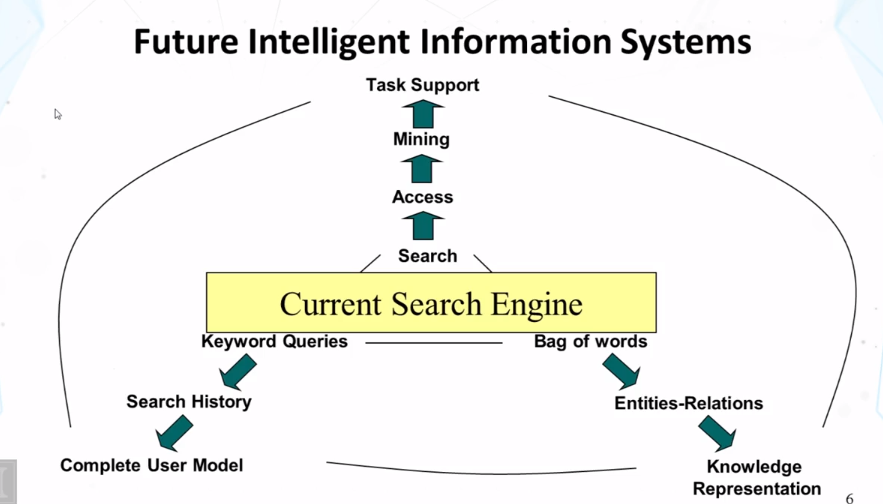
- Above image shows what current search engines do (search, keyword queries, bag of words), and what people are working to expand it to do.
6-5 Recommender Systems-Content-Based Filtering Part 1
- Two modes of text access: Pull vs Push
- Pull mode (search engines)
- users take initiative
- Ad hoc information need
- Push mode (recommender systems)
- systems take initiative
- stable information need or system has good knowledge about a user’s need
- Pull mode (search engines)
- Recommender ≈ Filtering system
- Stable & long term interest, dynamic info source
- System must make a delivery decision immediately as a document “arrives”
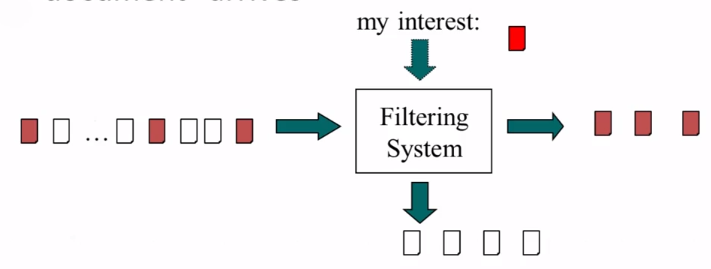
- Basic Filtering Question: Will User U Like Item X?
- Two different ways of answering it
- look at what items U likes, and then check if X is similar
- Item similarity => content-based filtering
- Look at who likes X, and then check if U is similar
- User similarity => collaborative filtering
- look at what items U likes, and then check if X is similar
- Can be combined
- Two different ways of answering it
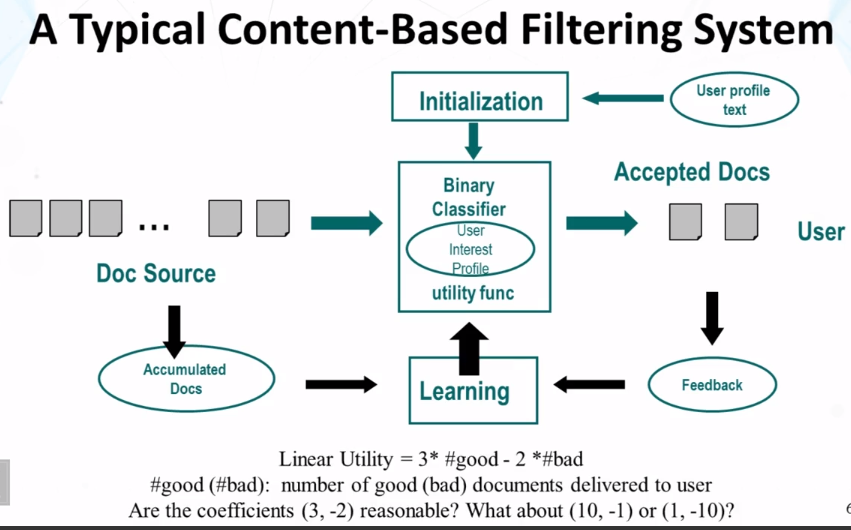
- Three Basic Problems in content-based filtering
- making filtering decision (binary classifier)
- Doc text, profile text –> yes/no
- Initialization
- initialize the filter based on only the profile text or very few examples
- Learning from
- Limited relevance judegements (only on “yes” docs)
- Accumulated documents
- All trying to maximize the utility
- making filtering decision (binary classifier)
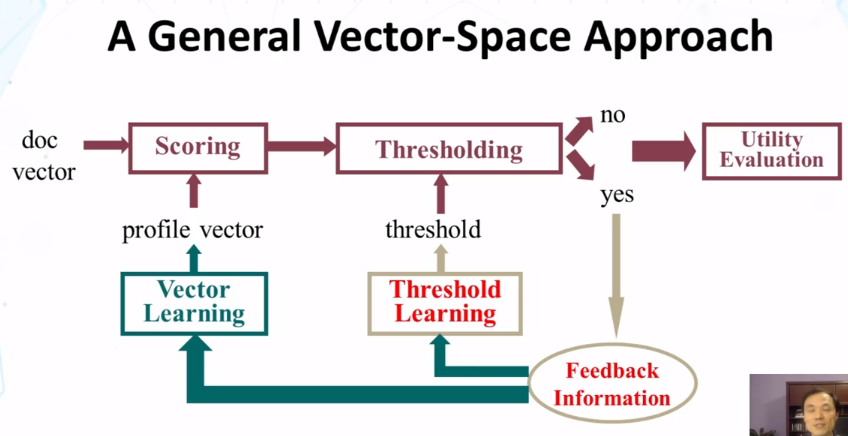
- Extend a retrieval system for information filtering
- “Reuse” retrieval techniques to score documents
- use a score threshold for filtering decision
- learn to improve scoring with traditional feedback
- new approaches to threshold setting and learning
6-6 Recommender Systems-Content-Based Filtering Part 2
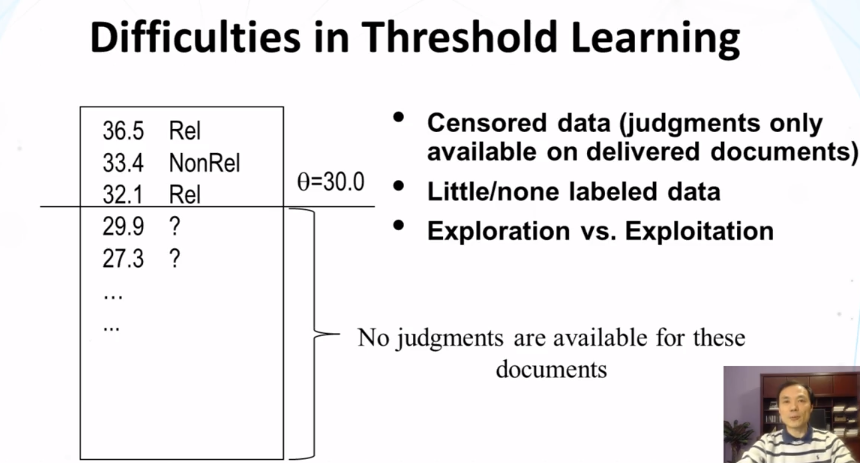
- Empirical utility optimization
- Basic idea
- compute the utility on the training data for each candidate score threshold
- choose the threshold that gives the maximum utility on the training data set
- difficulty: biased training sample!
- we can only get an upper bound for the true optimal threshold
- could a discarded item be possibly interesing to the user?
- solution:
- heuristic adjustment (lowering) of threshold
- Basic idea
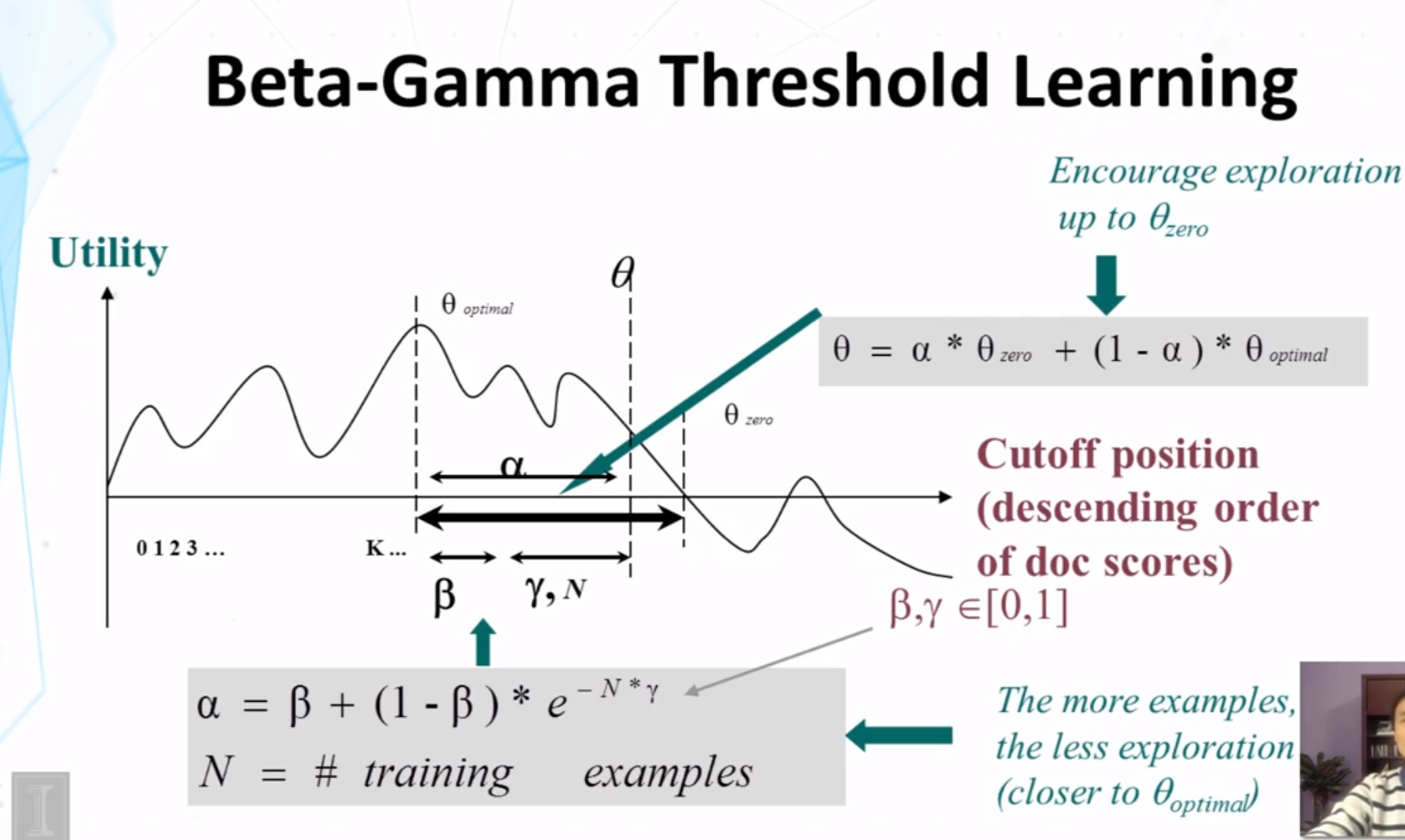
- Beta-Gamma thereshold learning
- Pros
- explicitly addresses exploration-exploitation tradeoff (“safe” exploration)
- Arbitrary utility (with appropriate lower bound)
- empirically effective
- Cons
- Purely heuristic
- Zero utility lower bound often too conservative
- Pros
- Summary
- Two strategies for recommendation/filtering
- content-based (item similarity)
- collaborative filtering (user similarity)
- Content-based recommender system can be built based on a search engine system by
- adding threshold mechanism
- adding adaptive learning algorithms
- Two strategies for recommendation/filtering
6-7 Recommender Systems-Collaborative Filtering Part 1
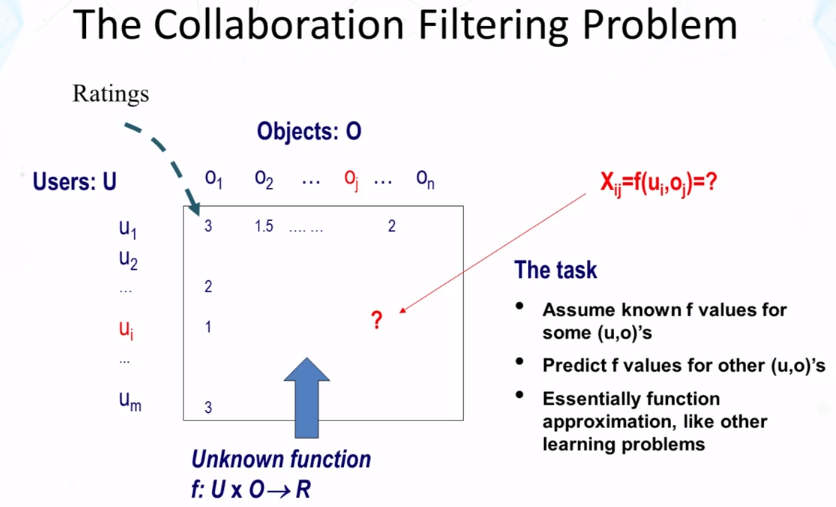
- What is Collaborative filtering (CF) ?
- Making filtering decisions for an individual user based on the judgements of other users
- Inferring individual’s interest/preferences from that of other similar users
- General idea
- Given a user u, find similar users {u1, …, um}
- Predict u’s preferences based on the preferences of u1, …, um
- User similarity can be judged based on their similarity in preferences on a common set of items.
- CF: Assumptions
- Users with the same interest will have similar preferences
- Users with similar preferences probably share the same interest
- Examples
- “interest is infomration retrieval” => “favor SIGIR papers”
- “favor SIGIR papers” => “interest is information retrieval”
- Sufficiently large number of user preferences are avaialable (if not, there will be a “cold start” problem)
6-8 Recommender Systems-Collaborative Filtering Part 2


- Improving User similarity meeasures
- Dealing with missing values: set to default ratings (eg, average ratings)
- Inverse user frequency (IUF): similar to IDF
6-9 Recommender Systems-Collaborative Filtering Part 3
- Summary of Recommender Systems
- Filtering/Recommendations is “easy”
- The user’s expectation is low
- Any recommendation is better than none
- Filtering is “hard”
- Must make a binary decision, though ranking is also possible
- Data sparseness (limited feedback information)
- “cold start” (little information about users at the beginning)
- Content-based vs Collaborative filtering vs Hybrid
- Recommendation can be combined with search –> Push+Pull
- Many advanced algorithms have been proposed to use more context information and advanced machine learning.
- Filtering/Recommendations is “easy”
CS 425 Distributed Systems
Goals
- Design an algorithm to calculate a distributed snapshot.
- Assign FIFO/Causal/Total ordering to multicast messages.
- Design a reliable multicast protocol.
- Know the working of the industry-standard protocol called Paxos.
- Know why consensus is hard to solve.
Key Concepts
- Global Snapshots
- Multicast Ordering
- Multicast Reliability
- Paxos
- Impossibility of Consensus
Guiding Questions
- What is the difference between a safety property and a liveness property?
- How does the Chandy-Lamport algorithm work?
- How do you assign FIFO/Causal timestamps to multicasts in a distributed system?
- How does Paxos use quorums to ensure safety?
- Why is consensus impossible to solve in asynchronous systems?
Readings and Resources
Video Lecture Notes
6-1-1 What is Global Snapshot
- Distributed Snapshot
- More often, each country’s representative is sitting in their respective capital, and sending messages to each other (say emails)
- How do you calculate a “global snapshot” in that DS ?
- what does a “global snapshot” even mean?
- In the Cloud
- each application or service is running on multiple servers
- servers handling concurrent events and interacting with each other
- the ability to obtain a “global photograph” of the system is important
- some uses of having a global picture of the system
- checkpointing: can restart distributed application on failure
- Garbage collection of objects: objecst at servers that don’t have any other objects (at any servers) with pointers to them
- Deadlock detection: useful in database transaction systems
- Termination of computation: useful in batch computing systems like Folding@Home, SETI@Home
- What’s a global snapshot?
- Global snapshot = global state = individual state of each process in the DS + Individual state of each communication channel in the DS
- Capture the instantaneous state of each process
- And the instantaneous state of each communication channel, ie messages in transit on the channels
- Obvious first solution
- Synchronize clocks of all processes
- ask all processes to record their states at known time t
- Problems?
- time synchronization always has error
- your bank might inform you, “we lost the state of our distritbuted cluster due to a 1 ms clock skew in our snapshot algorithm”
- also, does not record the state of messages in the channels
- time synchronization always has error
- again: synchronization not reuired – causality is enough!
- Why does time synchronization not work as a way to calculate a global snapshot in a distributed system? (select all correct answers)
- time sync is inaccurate
- it may not capture channel states
-
it may not capture process states
- Moving from state to state
- whenever an event happens anywhere in the system, the global state changes
- process receives message
- process sends message
- process takes a step
- state to state movement obeys causality
- next: causal algorithm for global snapshot
- whenever an event happens anywhere in the system, the global state changes
6-1-2 Glboal snapshot algorithm
- System model
- Problem: record a global snapshot (state for each process, and state for each channel)
- System model:
- N processes in the system
- there are two uni-directional communication channels between each ordered process pair: Pj –> Pi and Pi –> Pj
- Communication channels are FIFO-ordered
- No failure
- All messages arrive intact, and are not duplicated
- other papers later relaxed some of these assumptions
- Requirements
- snapshot should not interfere with normal application actions, and it should not require application to stop sending messages
- Each process is able to record its own state
- process state: applicaiton-defined state or, in the worst case:
- its heap, registers, program counter, code, etc (essentially the coredump)
- Global state is collected in a distributed manner
- Any process may initiate the snapshot
- We’ll assume just one snapshot run for now
- Chandy-Lamport global snapshot algorithm
- first, initiator Pi records its own state
- initiator process creates special messages called “Marker” messages
- not an application message, does not interfere with application messages
- for j=1 to N except i
- Pi sends out a Marker message on outgoing channel Cij
- N-1 channels
- Starts recording the incoming messages on each of the incoming channels at Pi: Cji (for j= 1 to N except i)
- Whenever a process Pi receives a Marker message on an incoming channel Cki
- if (this is the first Marker Pi is seeing)
- Pi records its own state first
- Marks the state of channel Cki as “empty”
- for j = 1 to N except i
- Pi sends out a Marker message on outgoing channel Cij
- Starts recording the incoming messages on each of the incoming channels at Pi: Cji (for j = 1 to N except i and k)
- else // already seen a Marker message
- Mark the state of channel Cki as all the messages that have arrived on it since recording was turned on for Cki
- if (this is the first Marker Pi is seeing)
- The algorithm terminates when
- All processes have received a Marker
- to record their own state
- all processes have received a Marker on all the (N-1) incoming channels at each
- to record the state of all channels
- All processes have received a Marker
- Then, if needed, a central server collects all these partial state pieces to obtain the full global snapshot.
- Which of the following does a process NOT do when it receives its first marker message?
-
Starts recording the state of some incoming channels - Starts recording the state of some outgoing channels
-
Records its own state -
Marks the state of the incoming channel as empty
-
6-1-3 Consistent cuts
- Cuts
- cut = time frontier at each process and at each channel
- events at the process/channel that happen before the cut are “in the cut”
- and happening after the cut are “out of the cut”
- Consistent cuts
- a cut that obeys causality
- a cut C is a consistent cut iff for (each pair of events e, f in the system)
- such that event e is in the cut C, and if f –> e (f happens-before e)
- then: event f is also in the cut C
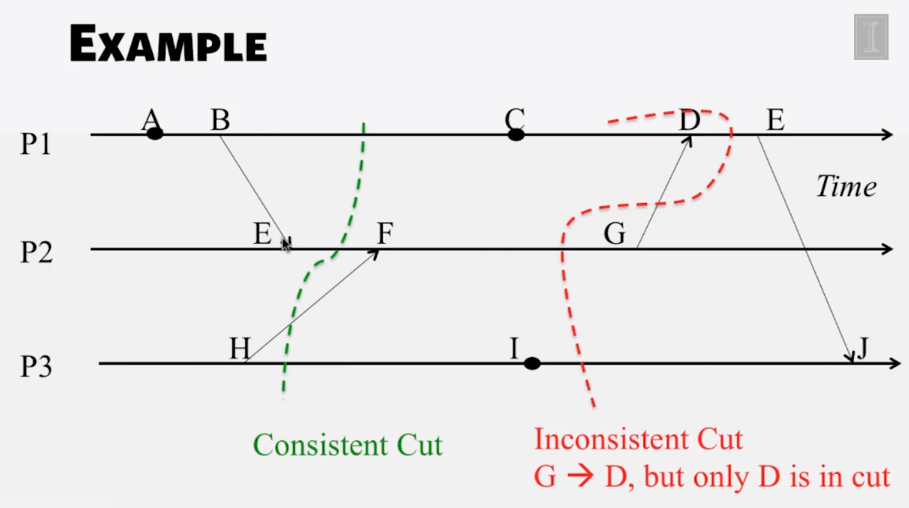
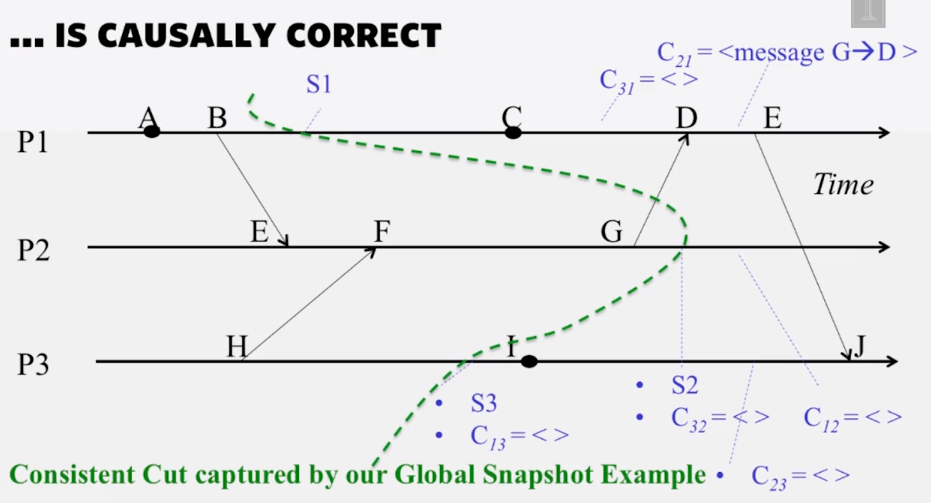
- Any run of the Chandy-Lamport Global snapshot algorithm creates a consistent cut


6-1-4 Safety and liveness
- Correctness in DS
- can be seen in two ways
- liveness and safety
- often confused – it’s important to distinguish from each other.
- liveness
- guarantee that something good will happen, eventually, meaning if you let the system run long enough, then
- Examples in real world
- guarantee that “at least one of the atheletes in the 100m final will win gold” is liveness
- a criminal will eventually be jailed
- Examples in a DS
- distributed computation: Guarantee that it will terminate
- “Completeness” in failure detectors: every failure is eventually detected by some non-faulty process
- In consensus: all processes eventually decide on a value
- Safety
- guarantee that something bad will never happen
- examples in real world
- a peace treaty between two nations provides safety
- war will never happen
- an innocent person will never be jailed
- a peace treaty between two nations provides safety
- examples in DS:
- There is no deadlock in a distributed transaction system
- No object is orphaned in a distributed object system
- “Accuracy” in failure detectors
- in consensus: no two processes decide on different values
- Can we guarantee both?
- Can be difficult to satisfy both liveness and safety in an asynchronous DS!
- failure detector: completeness (liveness) and accuracy (safety) cannot both be guaranteed by a failure detector in an asynchronous DS
- Consensus: Decisions (liveness) and correct decisions (Safety) cannot both be guaranteed by any consensus protocol in an asynchronous DS
- Very difficult for legal systems (anywhere in the world) to guaranteed that all criminals are jailed (liveness) and no innocents are jailed (safety)
- Can be difficult to satisfy both liveness and safety in an asynchronous DS!
- In the language of global states:
- recall that a DS moves from one global state to another global state, via causal steps
- liveness with respect to a property Pr in a given state S means
- S satisfies Pr, or there is some causal path of global states from S to S’ where S’ satisfies Pr
- Safety with respect to a property Pr in a given state S means
- S satisfies Pr, and all global states S’ reachable from S also satisfy Pr
- using global snapshot algorithm
- chandy-lamport algorithm can be used to detect global properties that are stable
- stable = once true, stays true forever afterwards
- stable liveness examples
- computation has terminated
- stable non-safety examples
- there is a deadlock
- an object is orphaned (no pointers point to it)
- all stable global properties can be detected using the Chandy-Lamport algorithm
- due to its causal correctness
- chandy-lamport algorithm can be used to detect global properties that are stable
- Summary
- the ability to calculate global snapshots in a DS is very important
- but don’t want to interrupt running DS application
- chandy-lamport algorithm calculates global snapshot
- obeys causality (creates a consistent cut)
- can be used to detect stable global properties
- safety vs liveness
6-2-1 Multicast ordering



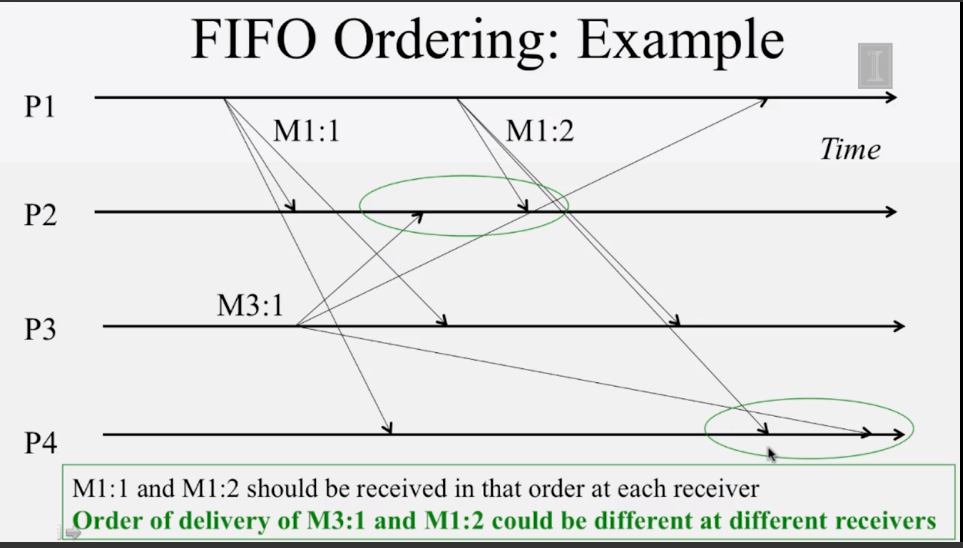

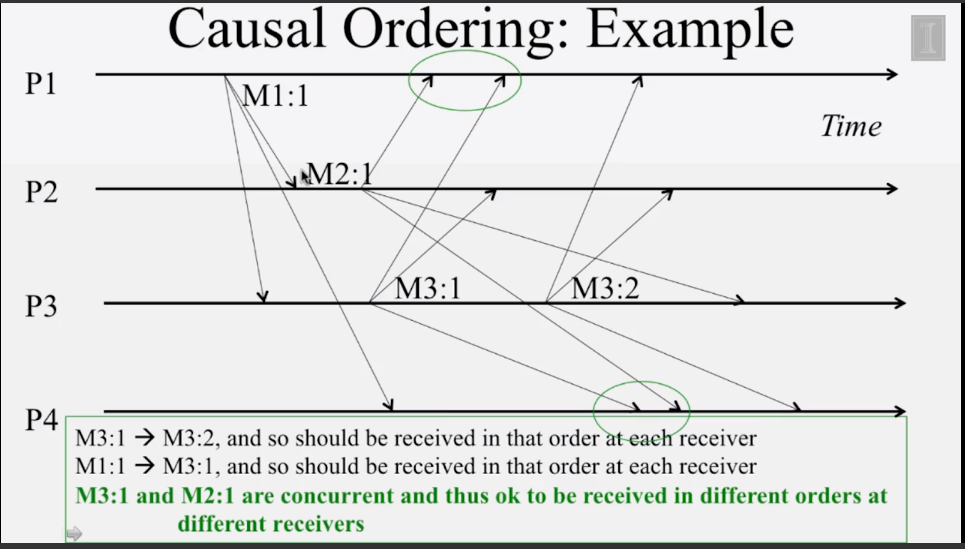



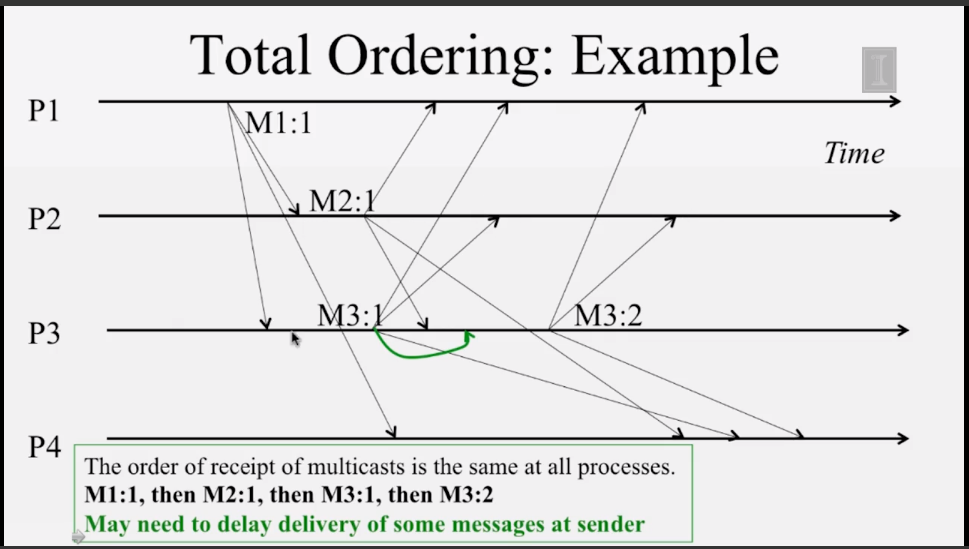

6-2-2 Implementing Multicast Ordering 1



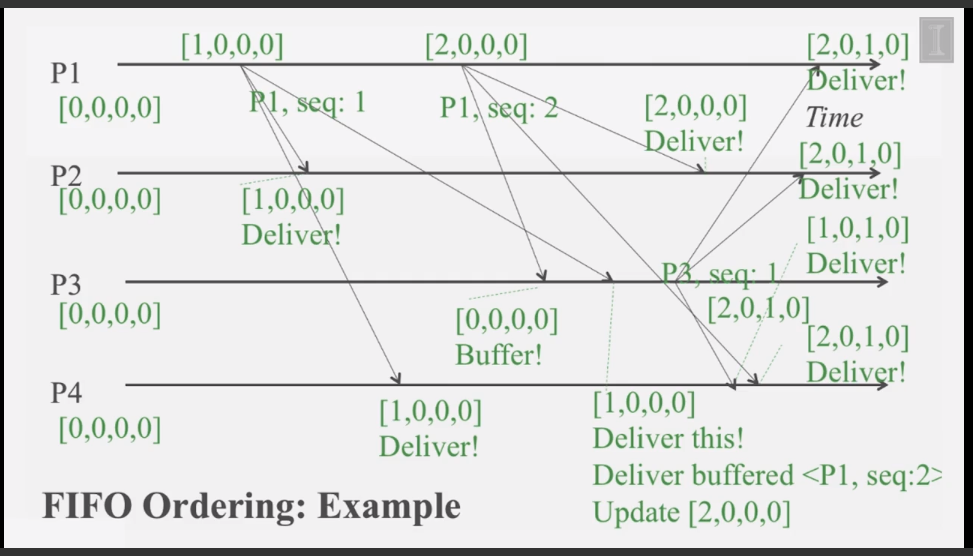


6-2-3 Implementing Multicast Ordering 2



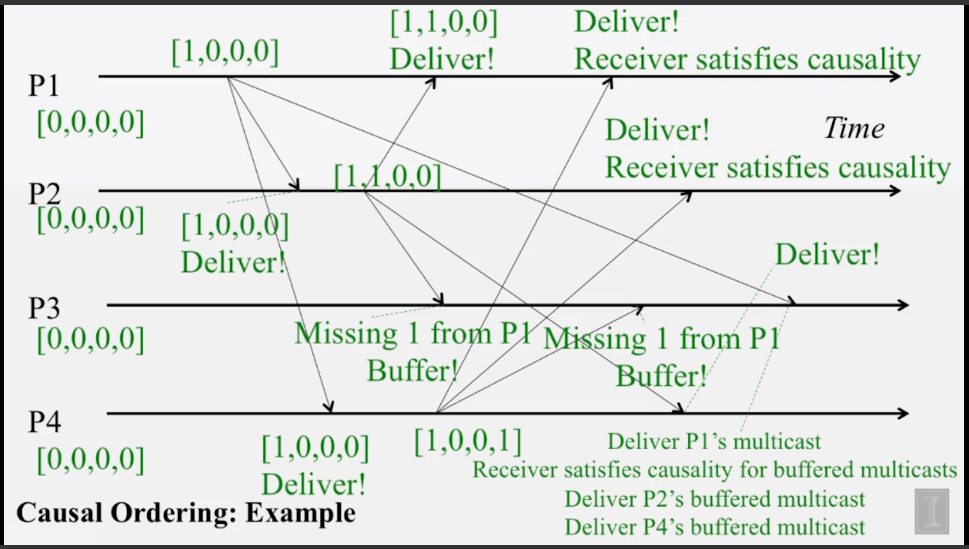

6-2-4 Reliable Multicast





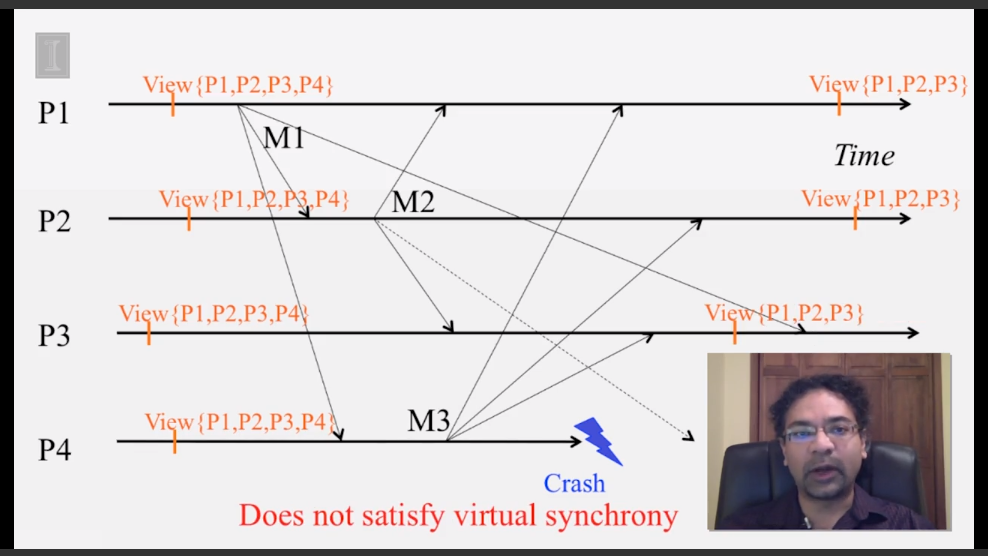
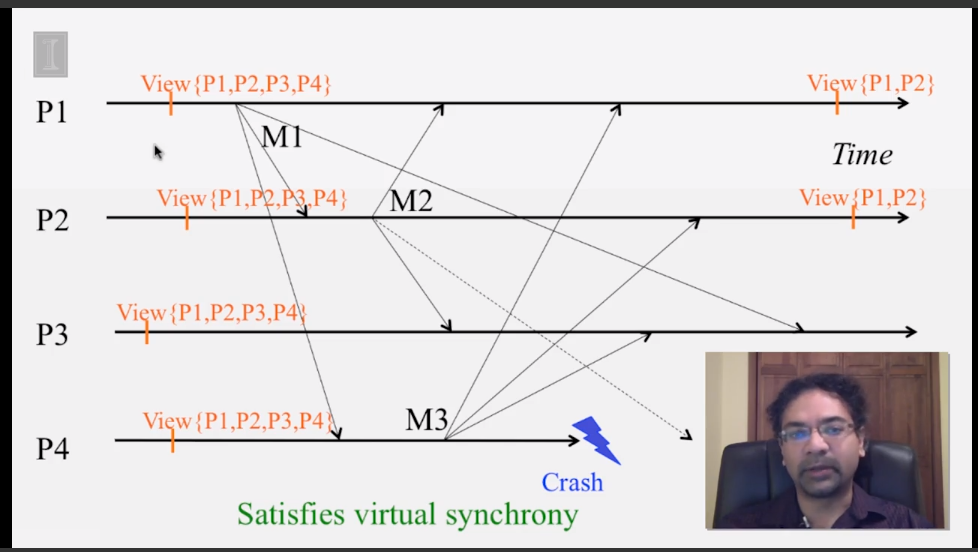
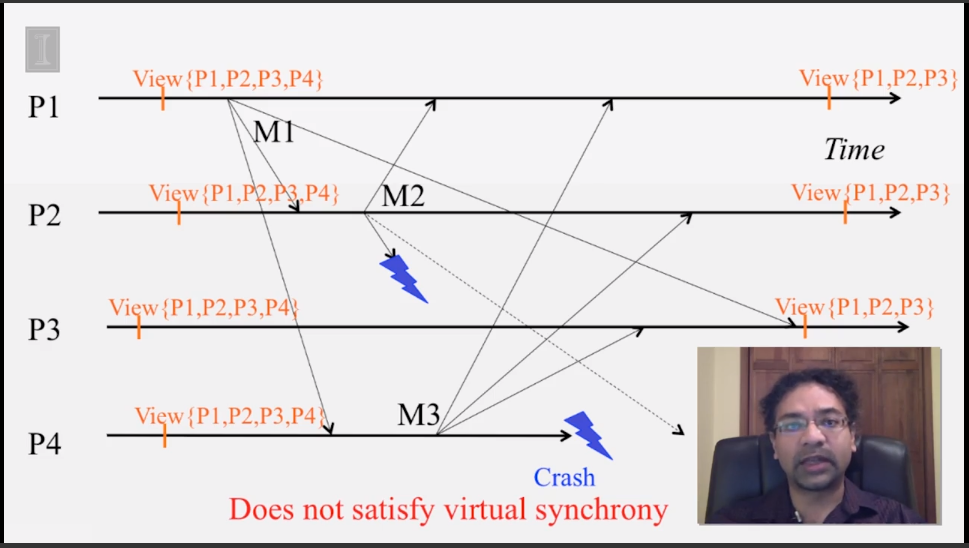
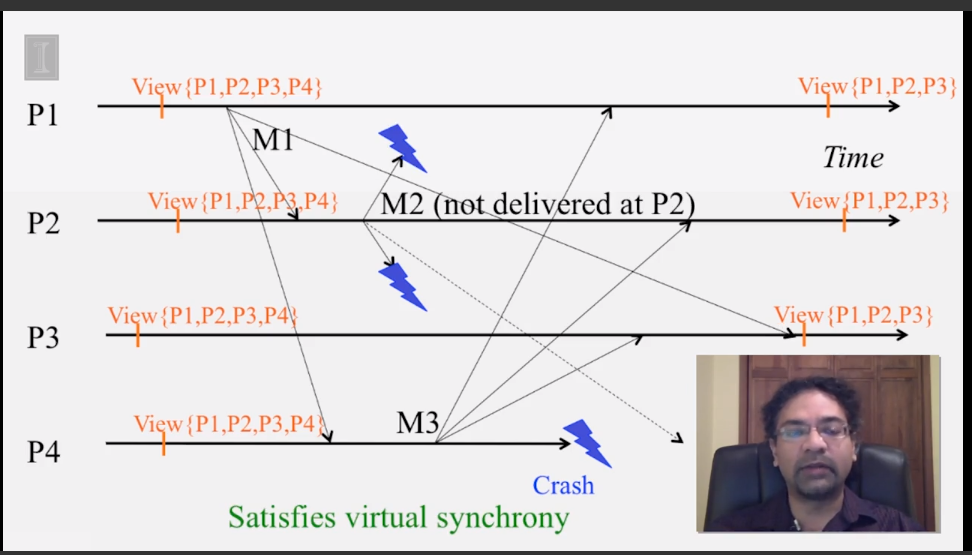
6-2-5 Virtual Synchrony



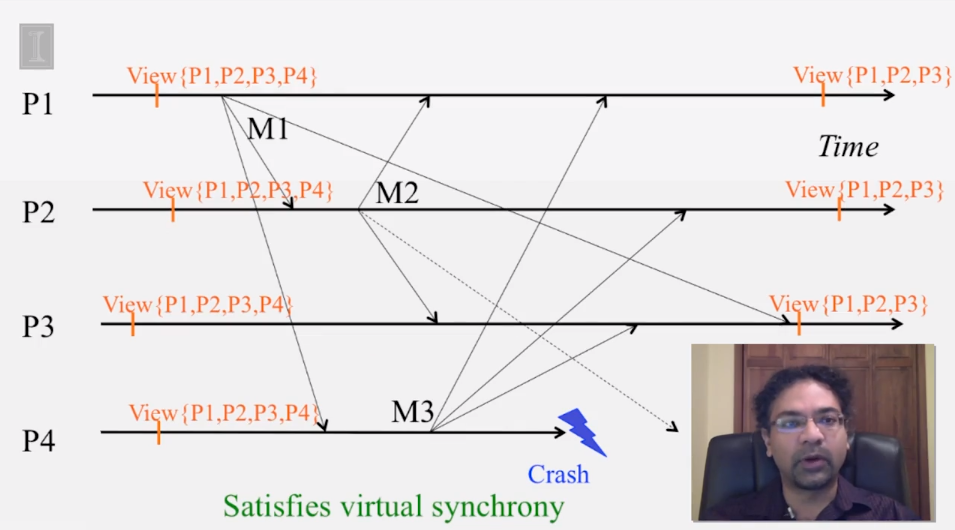
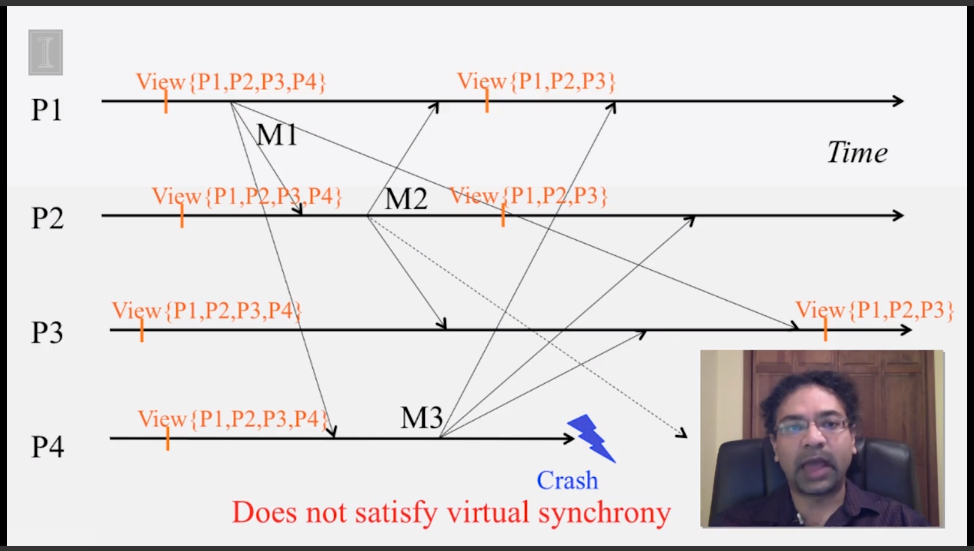
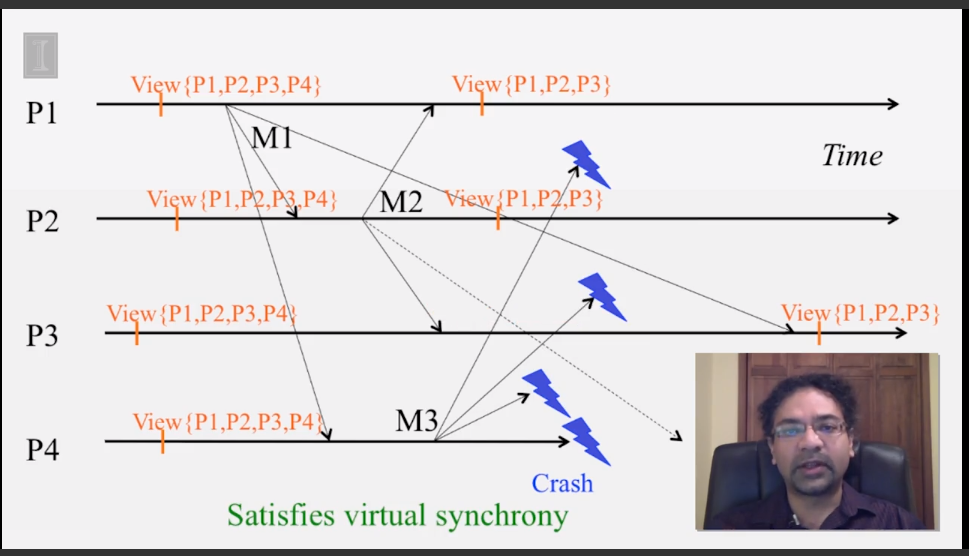


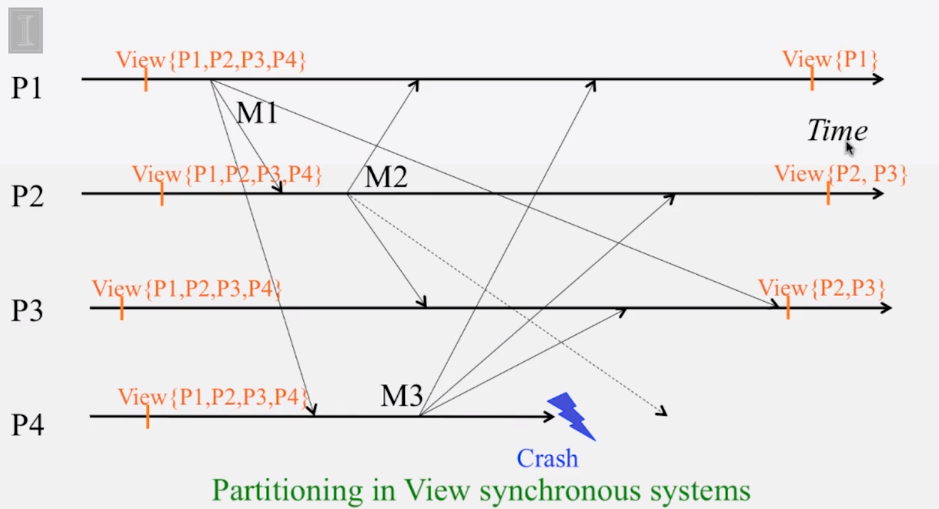

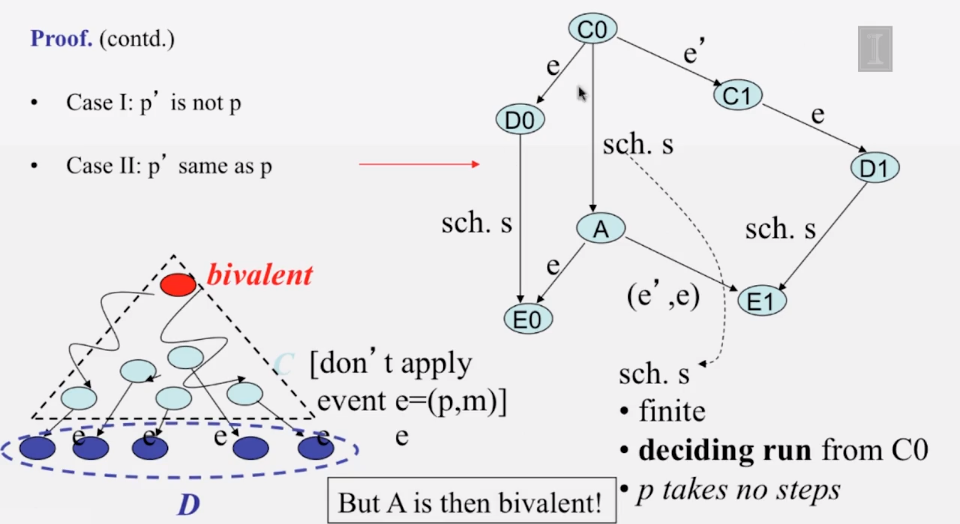
6-3-1 The Consensus Problem










6-3-2 Consensus in Synchronous Systems




6-3-3 Paxos put Simply





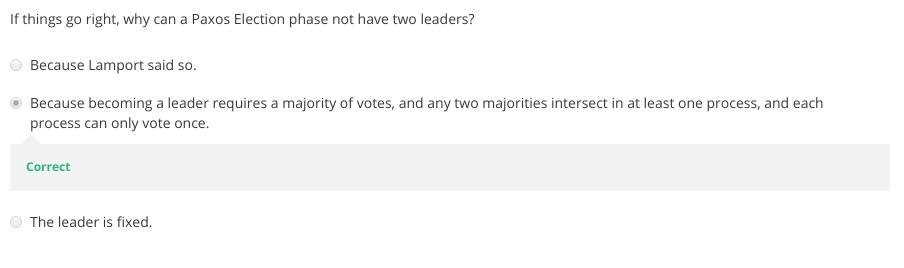






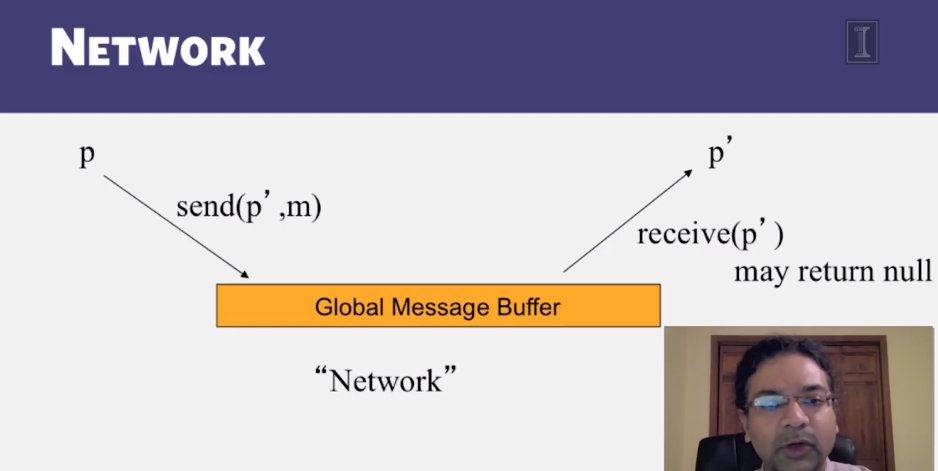
6-3-4 The FLP Proof




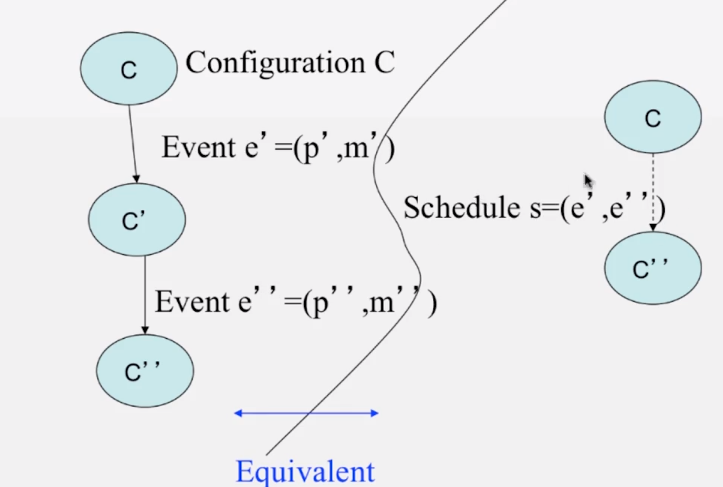
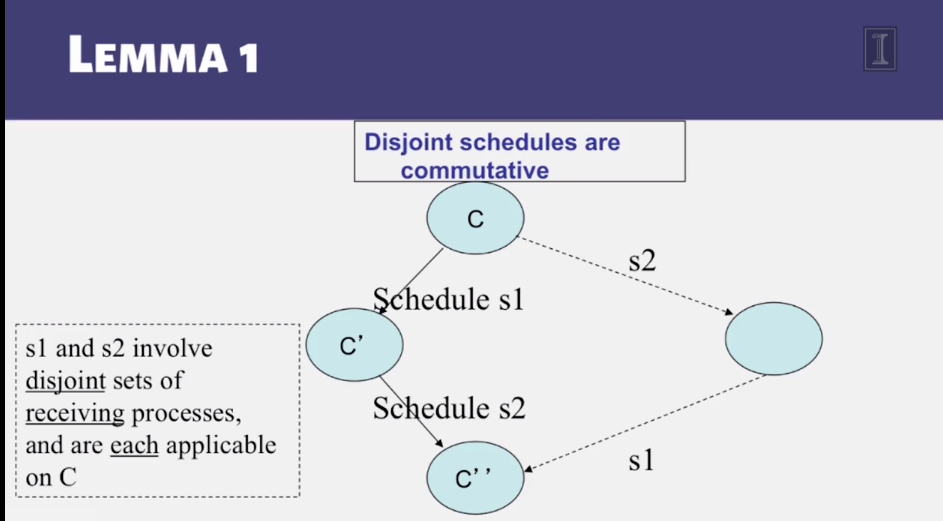








CS 427 Software Engineering
Video Lecture Notes
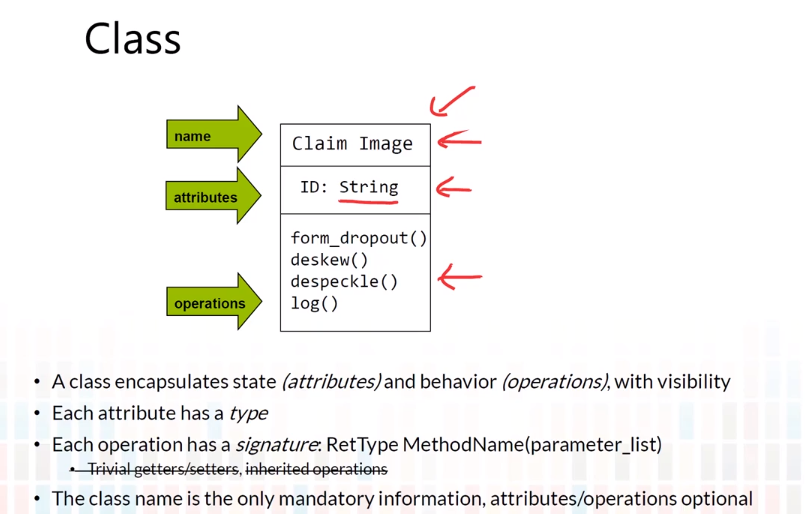
5-1 Object-Oriented Modeling
- Abstractions: Software under development
- Architecture
- OO Design
- Benefits of Modeling Notations
- Communication
- Documentation
- Quality Assurance
- Code Generation
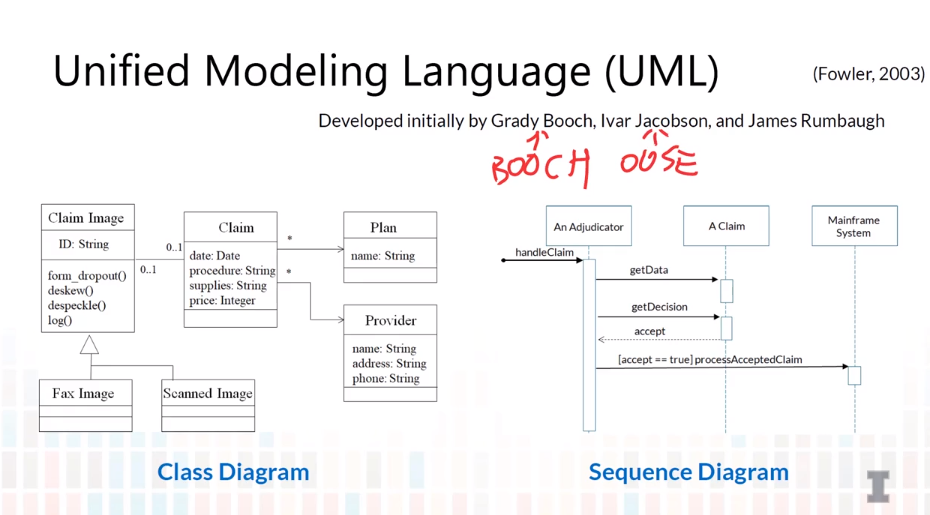
- Unified Modeling Language (UML)
- Class Diagram
- Sequence Diagram
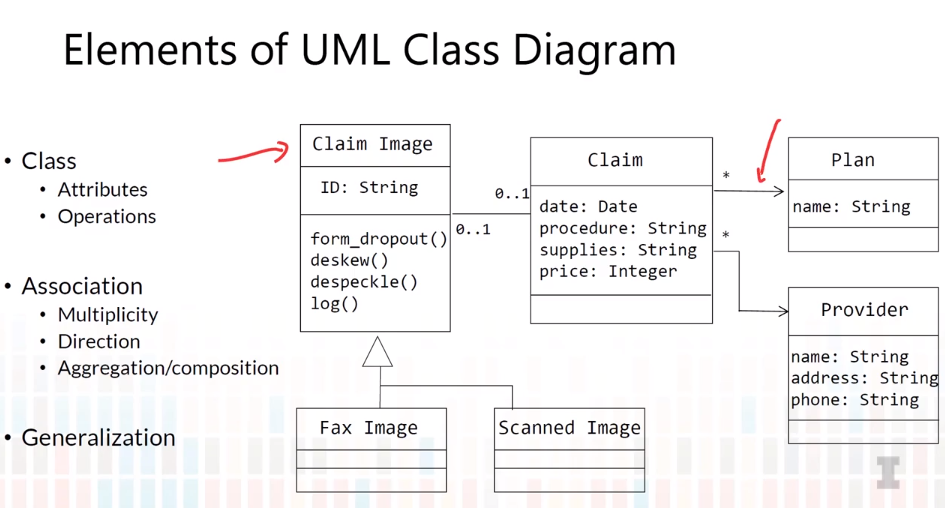
5-2 Class Diagram-Overview
- Purposes of class diagram
- Analysis - conceptual
- model problem, not software solution
- can include actors outside system
- Design - specification
- the structure of how a software system will be written
- Design - implementation
- Actual classes of implementation
- It DOES NOT capture how:
- classes interact with each other
- algorithm or behavior detail
- Analysis - conceptual
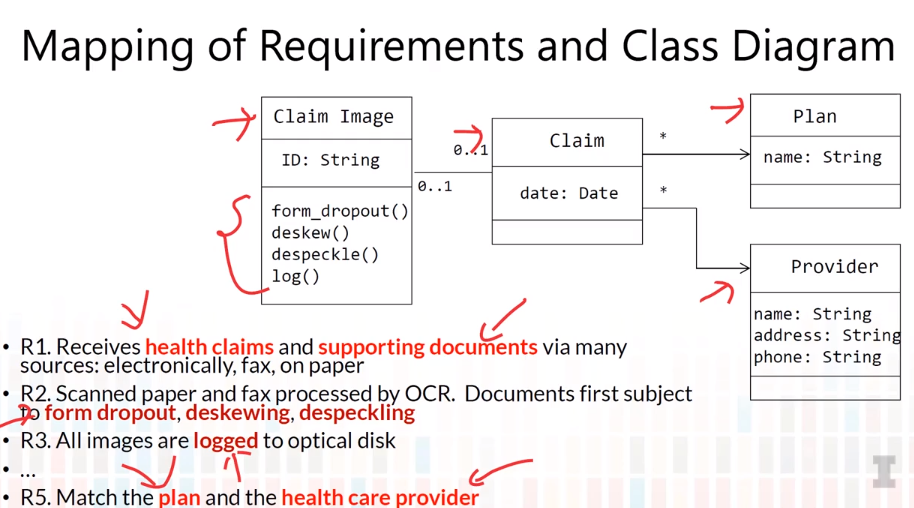
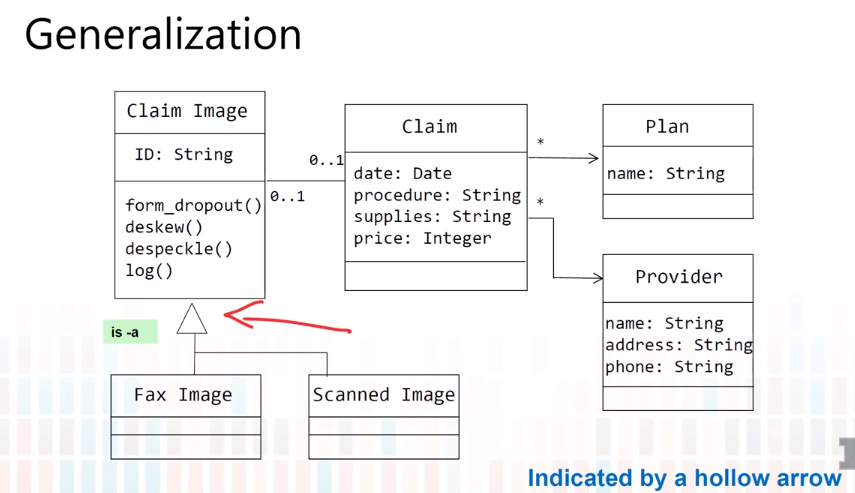
5-3 Class Diagram-Relationships
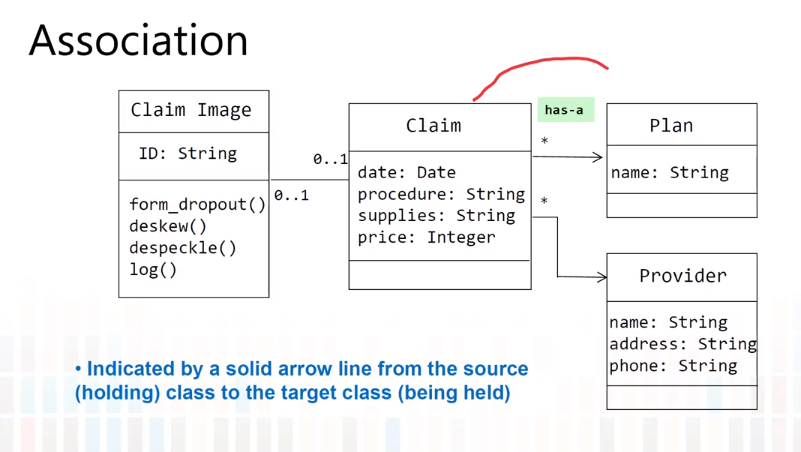
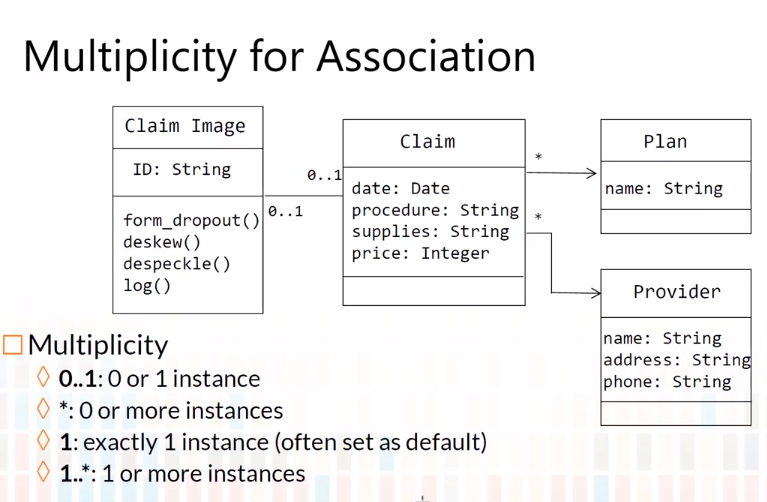
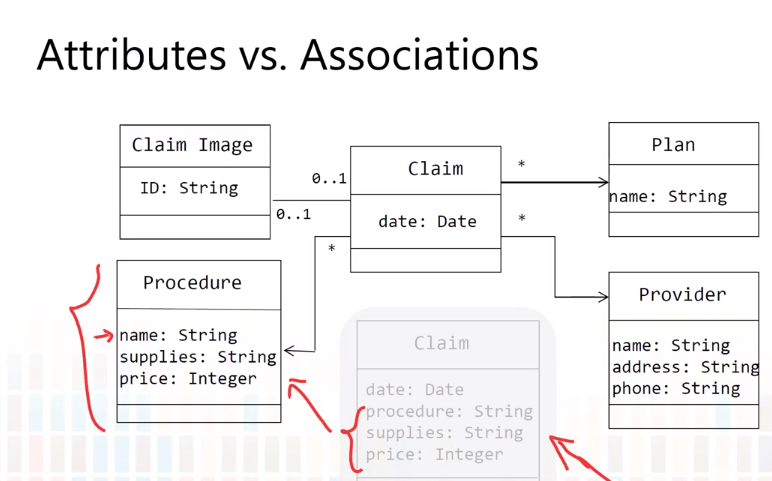


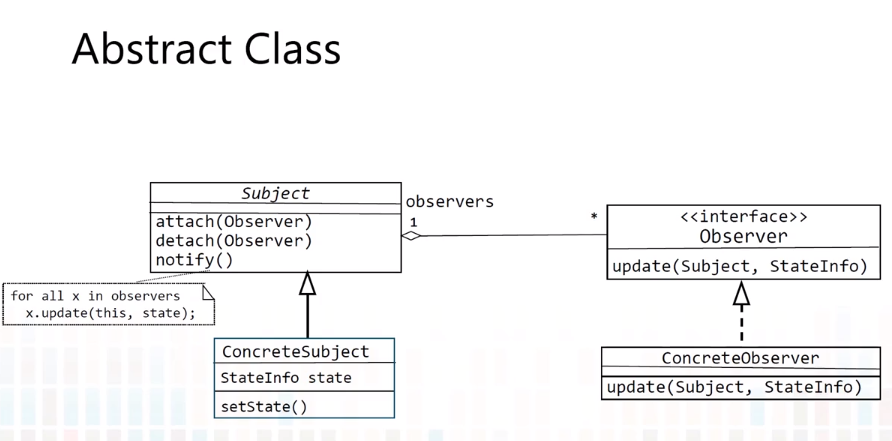
5-4 Class Diagram-Miscellaneous
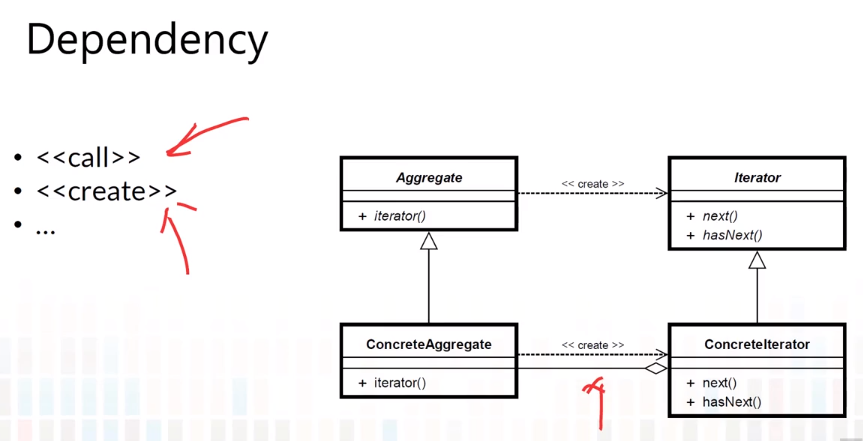
5-5 Requirements to Class Diagram
- Nouns are good candidates for classes/attributes
- Adjectives are good candidates for interfaces
- Verbs are good candidates for methods or relationships between classes
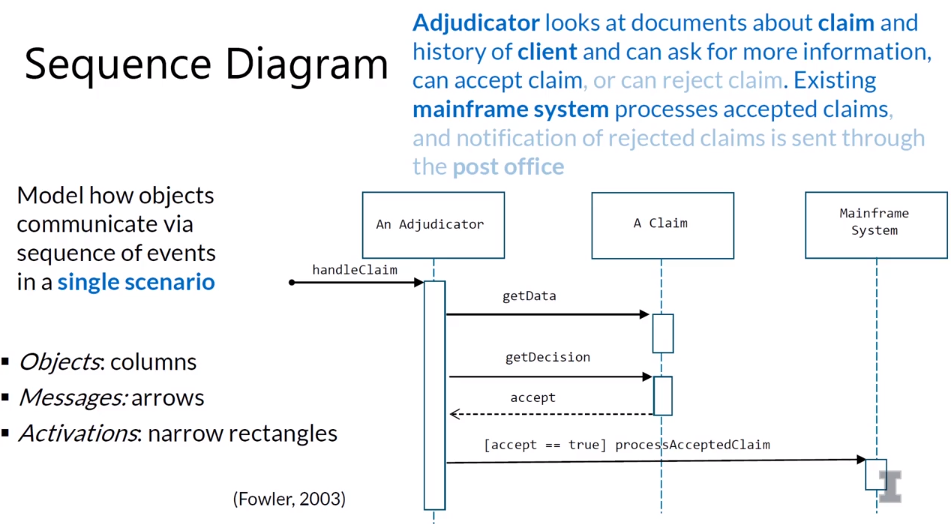
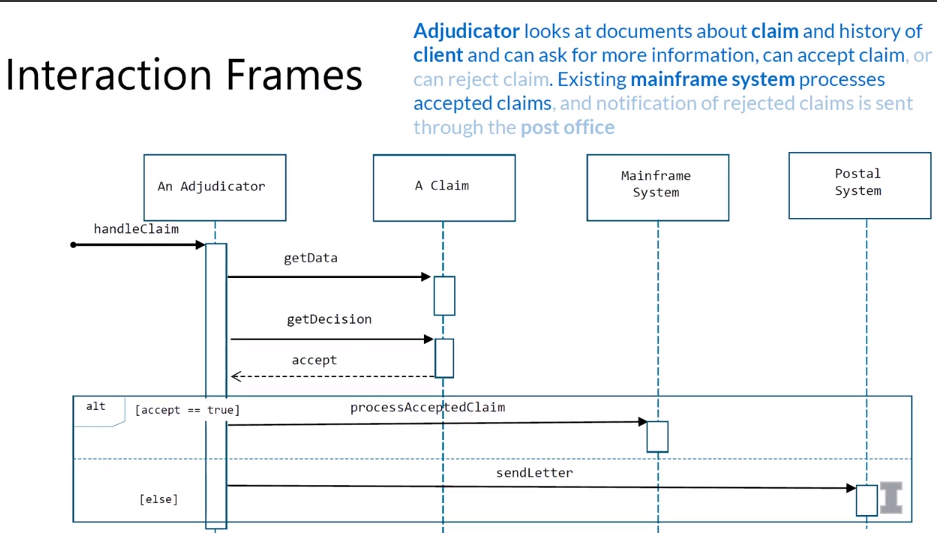
5-6 Sequence Diagram
- Purposes of UML Sequence Diagram
- Used during requirements analysis
- to refine use case descriptions
- to find additional objects (“participating objects”)
- Used during system design
- to refine subsystem interfaces
- Used during requirements analysis