- CS 410 Text Information Systems
- CS 425 Distributed Systems
- CS 427 Software Engineering
CS 410 Text Information Systems
Goals and Objectives
- Explain the similarity and differences in the three different kinds of feedback, i.e., relevance feedback, pseudo-relevance feedback, and implicit feedback.
- Explain how the Rocchio feedback algorithm works.
- Explain how the Kullback-Leibler (KL) divergence retrieval function generalizes the query likelihood retrieval function.
- Explain the basic idea of using a mixture model for feedback.
- Explain some of the main general challenges in creating a web search engine.
- Explain what a web crawler is and what factors have to be considered when designing a web crawler.
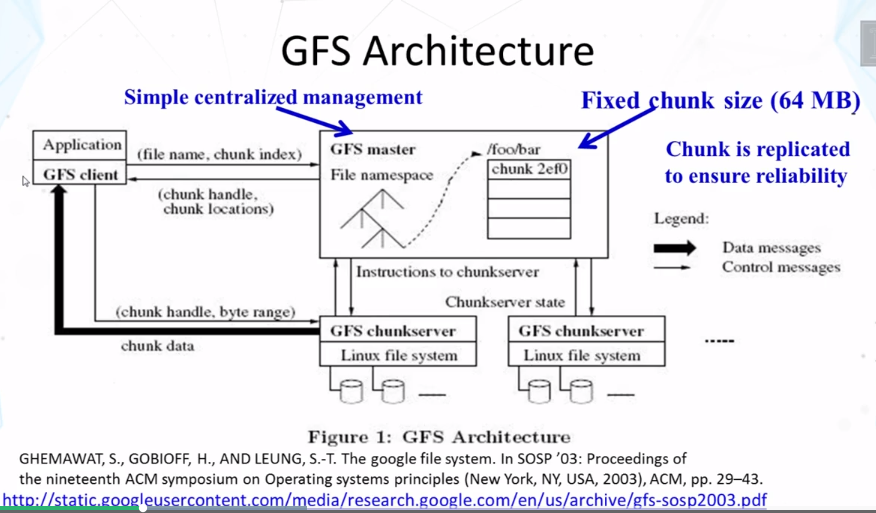
- Explain the basic idea of Google File System (GFS).
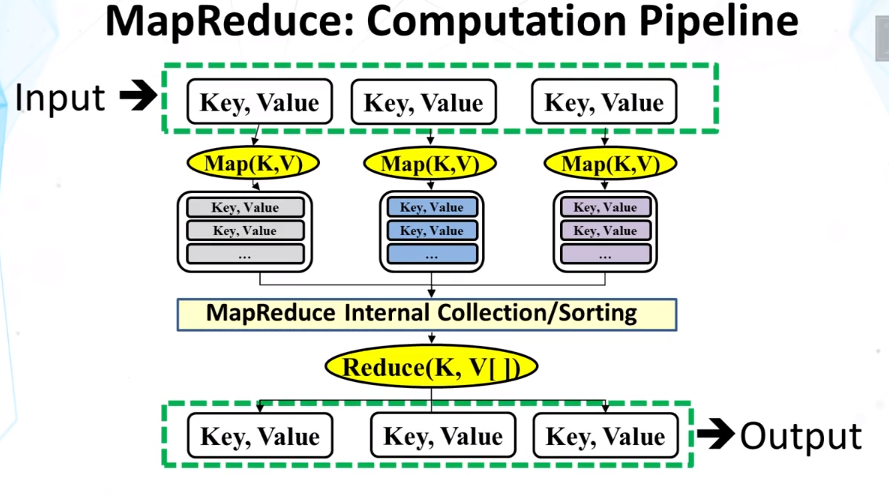
- Explain the basic idea of MapReduce and how we can use it to build an inverted index in parallel.
- Explain how links on the web can be leveraged to improve search results.
- Explain how PageRank algorithm works.
Guiding Questions
- What is relevance feedback? What is pseudo-relevance feedback? What is implicit feedback?
- How does Rocchio work? Why do we need to ensure that the original query terms have sufficiently large weights in feedback?
- What is the KL-divergence retrieval function? How is it related to the query likelihood retrieval function?
- What is the basic idea of the two-component mixture model for feedback?
- What are some of the general challenges in building a web search engine?
- What is a crawler? How can we implement a simple crawler?
- What is focused crawling? What is incremental crawling?
- What kind of pages should have a higher priority for recrawling in incremental crawling?
- What can we do if the inverted index doesn’t fit in any single machine?
- What’s the basic idea of the Google File System (GFS)?
- How does MapReduce work? What are the two key functions that a programmer needs to implement when programming with a MapReduce framework?
- How can we use MapReduce to build an inverted index in parallel?
- What is anchor text? Why is it useful for improving search accuracy?
- What is a hub page? What is an authority page?
- What kind of web pages tend to receive high scores from PageRank?
- How can we interpret PageRank from the perspective of a random surfer “walking” on the Web?
- How exactly do you compute PageRank scores?
- How does the HITS algorithm work?
Additional Readings and Resources
- C. Zhai and S. Massung. Text Data Management and Analysis: A Practical Introduction to Information Retrieval and Text Mining, ACM Book Series, Morgan & Claypool Publishers, 2016. Chapters 7 & 10
Key Phrases and Concepts
- Relevance feedback
- Pseudo-relevance feedback
- Implicit feedback
- Rocchio feedback
- Kullback-Leiber divergence (KL-divergence) retrieval function
- Mixture language model
- Scalability and efficiency
- Spams
- Crawler, focused crawling, and incremental crawling
- Google File System (GFS)
- MapReduce
- Link analysis and anchor text
- PageRank
Video Lecture Notes
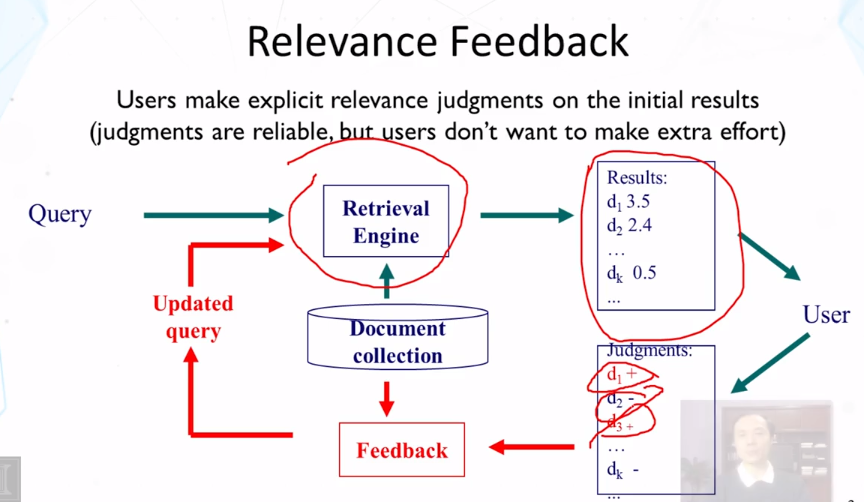
5-1 Feedback in Text Retrieval
5-2 Feedback in Vector Space Model Rocchio
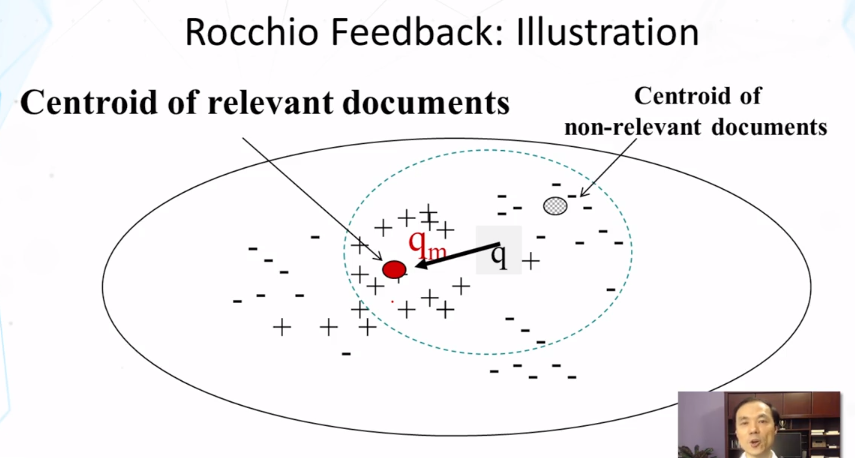
- Feedback in vector space model
- how can a TR system learn from examples to improve retrieval accuracy?
- positive examples: docs known to be relevant
- negatvie examples: docs known to be non-relevant
- general method: query modicfication
- adding new (weighted) terms (query expansion)
- adjusting weights of old terms
- how can a TR system learn from examples to improve retrieval accuracy?
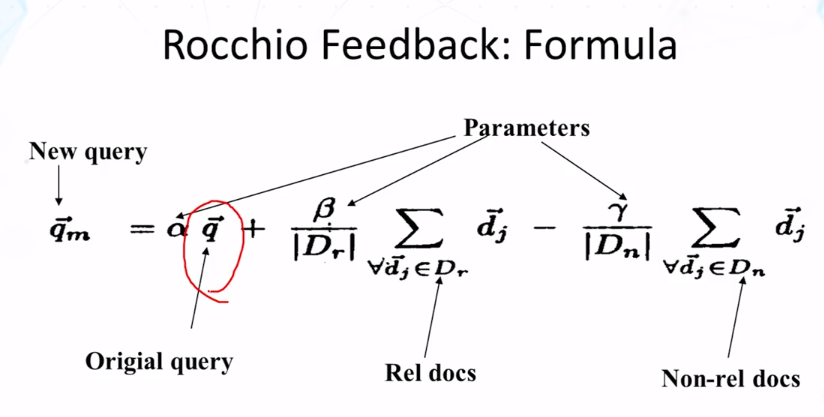
- Rocchio in Practice
- Negative (non-relevant) examples are not very important
- Often truncate the vector (ie, consider only a small number of words that have highest weights in the centroid vector)(efficiency concern)
- Avoid “over-fitting” (keep relatively high weight on the original query weights)
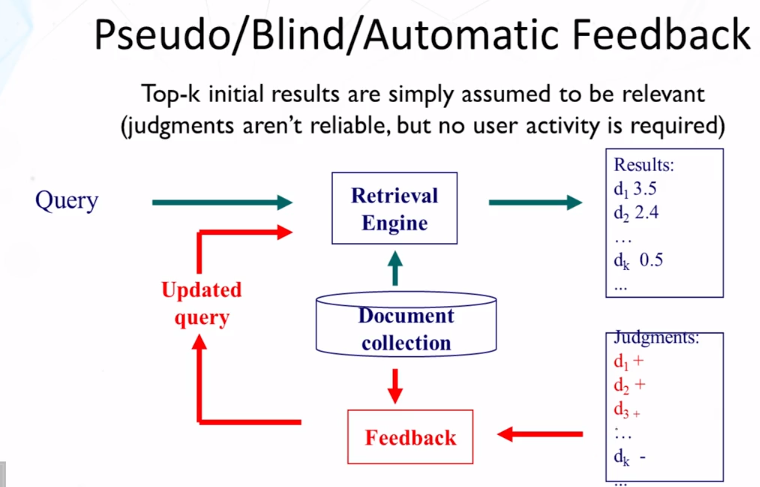
- Can be used for relevence feedback and pseudo feedback (Β should be set to a larger value for relevance feedback than for pseudo feedback)
- Usually robust and effective

5-3 Feedback in Text Retrieval feedback in LM
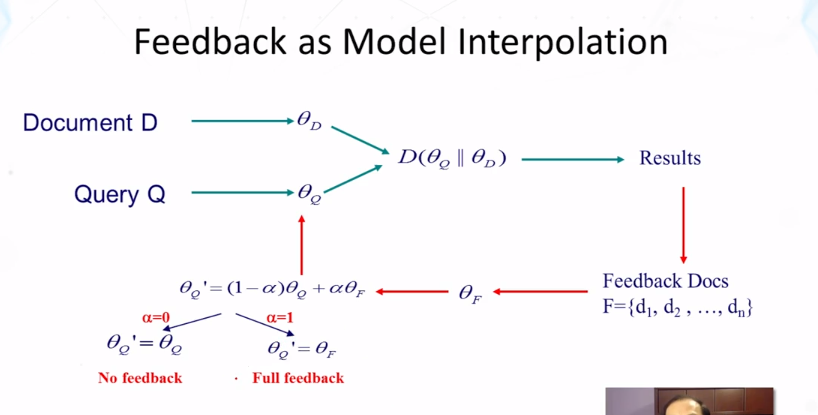
- Feedback with LM
- Query likelihood method can’t naturally support relevance feedback
- Solution:
- Kullback-Leibler( KL) divergence retrieval model as a generalization of query likelihood
- Feedback is achieved through query model estimation/updating




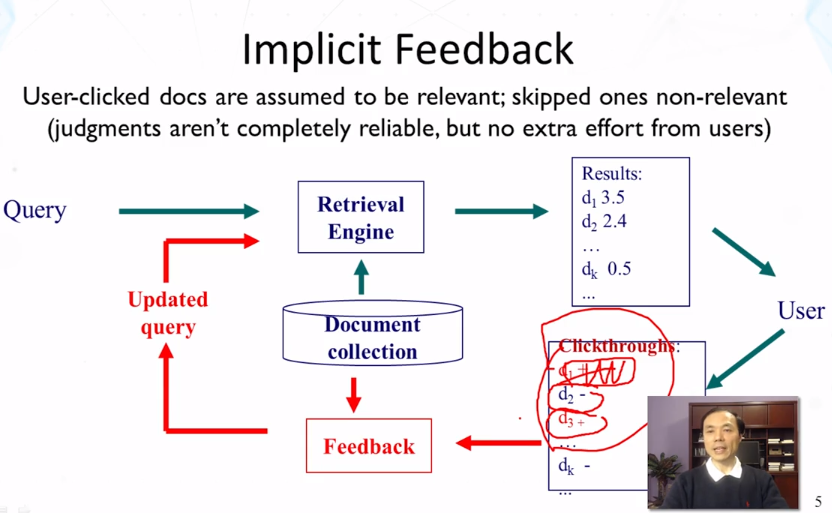
- Summary of feedback in Text Retrieval
- Feedback = learn from examples
- Three major feedback scenarios
- Relevance, pseudo, and implicit feedback
- Rocchio for VSM (vector space model)
- Query Model estimation for LM
- Mixture model
- many other methods (eg, relevance model) have been proposed
5-4 Web Search Introduction & Web Crawler
- Web Search: Challenges & Opportunities
- Challenges
- scalability
- how to handle the size of the web and ensure completeness of coverage?
- how to serve many user queries quickly?
- low quality information and spams
- dynamics of the web
- new pages are constantly created and some pages may be updated very quickly
- scalability
- Opportunities
- many additional heuristics (eg links) can be leveraged to improve search accuracy
- Challenges
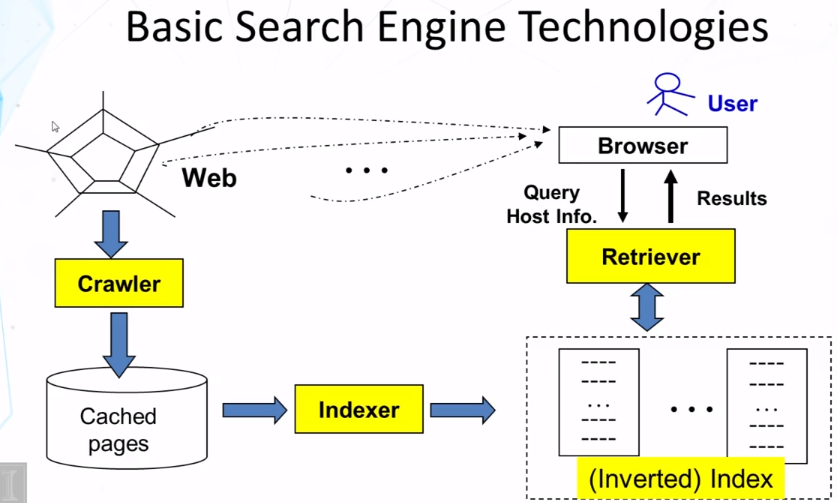
- Component I: Crawler/Spider/Robot
- Building a “toy crawler” is easy
- Start with a set of “seed pages” in a priority queue
- fetch pages from the web
- parse fetched pages for hyperlinks; add them to the queue
- follow the hyperlinks in the queue
- A real crawler is much more complicated…
- Robustness (server failure, trap, etc)
- Crawling courtesy (server load balance, robot exlclusion, etc)
- Handling file types (images, PDF files, etc)
- URL extensions (cgi script, internal references, etc)
- recognize redundant pages (identical and duplicates)
- discover “hidden” urls (eg, truncating a long url)
- Building a “toy crawler” is easy
- Major Crawling strategies
- Breadth-first is common (balance server load)
- parallel crawling is natural
- variation: focused crawling
- targeting at a subset of pages (eg, all pages about “automobiles”)
- typically given a query
- How to find new pages (they may not linked to an old page!)
- Incremental/repeated crawling
- need to minimize reource overhead
- can learn form the past experience (updated daily vs monthly)
- target at 1) frequently updated pages; 2) frequently accessed pages
5-5 Web indexing
- Overview of web indexing
- standard IR techniques are the baseis, but insufficient
- scalability
- efficiency
- Google’s gontributions:
- google file system (gfs): distributed file system
- mapreduce: software framework for parallel computation
- hadoop: open source implementation of mapreduce
- standard IR techniques are the baseis, but insufficient
- Mapreduce: a framework for parallel programming
- minimize effort of programmer for simple parallel processing tasks
- Features
- hide many low-level details (network, storage)
- build-in fault tolerance
- automatic load balancing
5-6 Link Analysis
- Ranking Algorithms for Web Search
- Standard IR (information retrieval) models apply but aren’t sufficient
- Different information needs
- documents have additional information
- information quality varies a lot
- Major extensions
- exploiting links to improve scoring
- exploiting clickthroughs for massive implicit feedback
- in general, rely on machine learning to combine all kinds of features
- Standard IR (information retrieval) models apply but aren’t sufficient
- Pagerank: capturing page “popularity”
- intutions
- links are like citations in literature
- a page taht is cited often can be expected to be more useful in general
- pagerank is essentially “citation counting”, but improves over simple counting
- consider “indirect citations” (being cited by a highly cited paper counts a lot…)
- smoothing of citations (every page is assumed to have a non-zero pseudo citation count)
- PageRank can also be interpreted as random surfing (thus capturing popularity)
- intutions
5-7 Link Analysis Part 2
- The pagerank algorithm
- Random surfing model: At any range,
- with probability α randomly jumping to another page
- with probability (1-α), randomly picking a link to follow.
- p(di): PageRank score of di = average probability of visiting page di
- Random surfing model: At any range,
- PageRank in Practice
- computation can be quite efficient since M is usually sparse
- Normalization doesn’t affect ranking, leading to some variants of the formula
- The zero-outlink problem: p(di)’s don’t sum to 1
- one possible solution = page-specific damping factor (α =1-0 for a page with no outlink)
- Many extensions (eg, topic-specific PageRank)
- Many other applications (eg, social network analysis)

5-8 Link analysis Part 3
- HITS: Capturing Authorities & Hubs
- Intuitions
- Pages that are widely cited are good authorities
- Pages taht cite many other pages are good hubs
- The key idea of HITS (Hypertext-Induced Topic Search)
- Good authorities are cited by good hubs
- Good hubs point to good authorities
- Iterative reinforcement…
- Many applications in graph/network analysis
- Intuitions
- Summary
- link information is very useful
- anchor text
- pagerank
- HITS
- Both pagerank and HITS have many applications in analyzing other graphs or networks
- link information is very useful

CS 425 Distributed Systems
Goals
- Know why key-value/NoSQL are gaining popularity
- Know the design of Apache Cassandra
- Know the design of Apache HBase
- Use various time synchronization algorithms
- Apply Lamport and vector timestamps to order events in a distributed system
Key Concepts
- Key-value and NoSQL stores
- Cassandra system
- CAP theorem
- Consistency-availability tradeoff and spectrum
- Eventual consistency
- HBase system
- ACID vs. BASE
- Time synchronization algorithms in asynchronous systems: Cristian’s, NTP, and Berkeley algorithms
- Lamport causality and timestamps
- Vector timestamps
Guiding Questions
- Why are key-value/NoSQL systems popular today?
- How does Cassandra make writes fast?
- How does Cassandra handle failures?
- What is the CAP theorem?
- What is eventual consistency?
- What is a quorum?
- What are the different consistency levels in Cassandra?
- How do snitches work in Cassandra?
- Why is time synchronization hard in asynchronous systems?
- How can you reduce the error while synchronizing time across two machines over a network?
- How does HBase ensure consistency?
- What is Lamport causality?
- Can you assign Lamport timestamps to a run?
- Can you assign vector timestamps to a run?
Readings and Resources
- Cassandra
- HBase
- Cassandra 2-0 Paper
- Cassandra NoSQL Presentation
- Cassandra 1-0 documentation at datastax.com
- Cassandra Apache wiki
- MongoDB
Video Lecture Notes
5-1-1 Why Key-Value with NoSQL
- Distributed Hash Table to construct relational database (P2P)
- Mismatch with today’s workloads
- Data: large and unstructured
- lots of random reads and writes
- sometime write-heavy
- foreign keys rarely needed
- joins infrequent
- Needs of today’s workloads
- speed
- avoid single point of failure (SPoF)
- Fewer system administrators
- incremental scalability
- scale out, not up
- why?
- scale out, not up
- scale up = grow your cluster capacity by replacing with more powerful machines
- traditional approach
- not cost-effective, as you’re buying above the sweet spot on the price curve
- and you need to replace machines often
- scale out = incrementally grow your cluster capacity by adding more COTS machines (components off the shelf)
- cheaper
- over a long duration, phase in a few newer (faster) machines as you phase out a few older machines
- used by most companies who run datacenters and clouds today
- scale up = grow your cluster capacity by replacing with more powerful machines
- key-value/nosql data model
- NoSQL = “Not only SQL”
- Necessary API operations: get(key) and put(key, value)
- get returns value; put updates value if already exists
- and some extended operaitons, eg “CQL” in cassandra key-value store
- Tables
- “Column families” in Cassandra, “Table” in HBase, “Collection” in MongoDB
- Like RDBMS tables, but…
- May be unstructured: may not have schemas
- some columns may be missing from some rows
- Don’t always support joins or have foreign keys
- can have index tables, just like RDBMSs
- Which of the following may NOT be present in key-value/NoSQL stores? (select all correct answers)
- Joins (c)
- Foreign Keys (c)
- Tables (not c)
- Rows (not c)
- Some columns in some rows
- Column-Oriented Storage
- NoSQL systems often use column-oriented storage
- RDBMSs store an entire row together( on disk or at a server)
- NoSQL systems typically store a column together (or a group of columns).
- Entrie within a column are indexed and easy to locate, given a key (and vice-versa)
- Why useful?
- range searches within a column are fast since you don’t need to fetch the entire database
- eg, Get me all the blog_ids from the blog table that were updated within the past month
- search in the last updated column, fetch corresponding blog_id column
- don’t need to fetch the other columns
- Why is column-oriented storage useful? (select all correct answers)
- Queries that touch only a few columns are faster than those in a row-oriented storage. (c)
- It enables faster range searches using one column. (c)
- It leads to lower total storage for the table. (not c)
- It prevents the entire table from being read for a query. (c)
- NoSQL systems often use column-oriented storage
5-1-2 Cassandra
- Widely used
- Data Placement Strategies
- Replication Strategy: two options:
- SimpleStrategy
- NetworkTopologyStrategy
- SimpleStrategy: uses the partitioner, of which there are two kinds
- RandomPartitioner:Chord-like hash partitioning
- ByteOrdered Partitioner: ASsigns ranges of keys to servers.
- easier for range queries (eg, Get me all twitter users starting with [a-b])
- NetworkTopologyStrategy: for multi-DC deployments
- Two replicas per DC (data center)
- Three replicas per DC
- Per DC
- First replica placed according to Partitioner
- Then go clockwise around ring until you hit a different rack
- Replication Strategy: two options:
- Snitches
- Maps: IPs to racks and DCs. Configured in cassandra.yaml config file
- Some options:
- SimpleSnitch: Unaware of Topology (rack-unaware)
- RackInferring: Assumes topology of network by octet of server’s IP address
- 101-102-103-104 = x.<DC octet>.<rack octet>.<node octet>
- PropertyFileSnitch: uses a config file
- EC2Snitch: uses EC2
- EC2 Region = DC
- Availability zone = rack
- Other snitch options available
- Writes
- Need to be lock-free and fast (no reads or disk seeks)
- Client sends write to one coordinator node in Cassandra cluster
- coordinator may be per-key, or per-client, or per-query
- Per-key coordinator ensures writes for the key are serialized
- Coordinator uses Partitioner to send query to all replica nodes responsible for key
- When X replicas respond, coordinator returns an acknowledgement to the client
- X? We’ll see later.
- Always writable: Hinted Handoff Mechanism
- if any replica is down, the coordinator writes to all other replicas, and keeps the write locally until down replica comes back up.
- When all replicas are down, the Coordinator (front end) buffers writes (for up to a few hours)
- One ring per datacenter
- Per-DC coordinator elected to coordinate with other DCs
- Election done via Zookeeper, which runs a Paxos (consensus) variant
- Paxos: elswhere in this course
- WRites at a replica node
- log it in disk commit log (for failure recovery)
- Make changes to appropriate memtables
- Memtable = In-memory representation of multiple key-value pairs
- Cache that can be searched by key
- Write-back cache as opposed to write-through
- Later, when memtable is full or old, flush to disk
- Data File: An SSTable (Sorted string table) – list of key-value pairs, sorted by key
- Index File: an SSTable of (key, position in data sstable) pairs
- And a Bloom filter (for efficient search) – next slide
- Bloom filter
- Compact way of representing a set of items
- Checking for existence in set is cheap
- Some probability of false positives: an item not in set may check true as being in set
- Never false negatives

- Compaction
- Data updates accumulate over time and SStables and logs need to be compacted
- the process of compaction merges SSTables, ie, by merging updates for a key
- run periodically and locally at each server
- Data updates accumulate over time and SStables and logs need to be compacted
- Deletes
- Delete: don’t delete item right away
- Add a tombstone to the log
- Eventually, when compaction encounters tombstone it will delete item
- Delete: don’t delete item right away
- Reads
- Read: Similar to writes, except
- Coordinator can contact X replicas (eg, in same rack)
- Coordinator sends read to replicas that have responded quickest in past
- When X replicas respond, coordinator returns the latest-timestamped value from among those X
- Coordinator also fetches value from other replicas
- checks consisten cy in the background, initiating a read repair if any two values are different
- This mechanism seeks to eventually bring all replicas up to date
- A row may be split across multiple SSTables => reads need to touch multiple SSTables => reads slower than writes (but still fast)
- Coordinator can contact X replicas (eg, in same rack)
- Read: Similar to writes, except
- Membership
- any server in cluster could be the coordinator
- So every server needs to maintain a list of all the other servers that are currently in the server
- List needs to be updated automatically as servers join, leave, and fail.
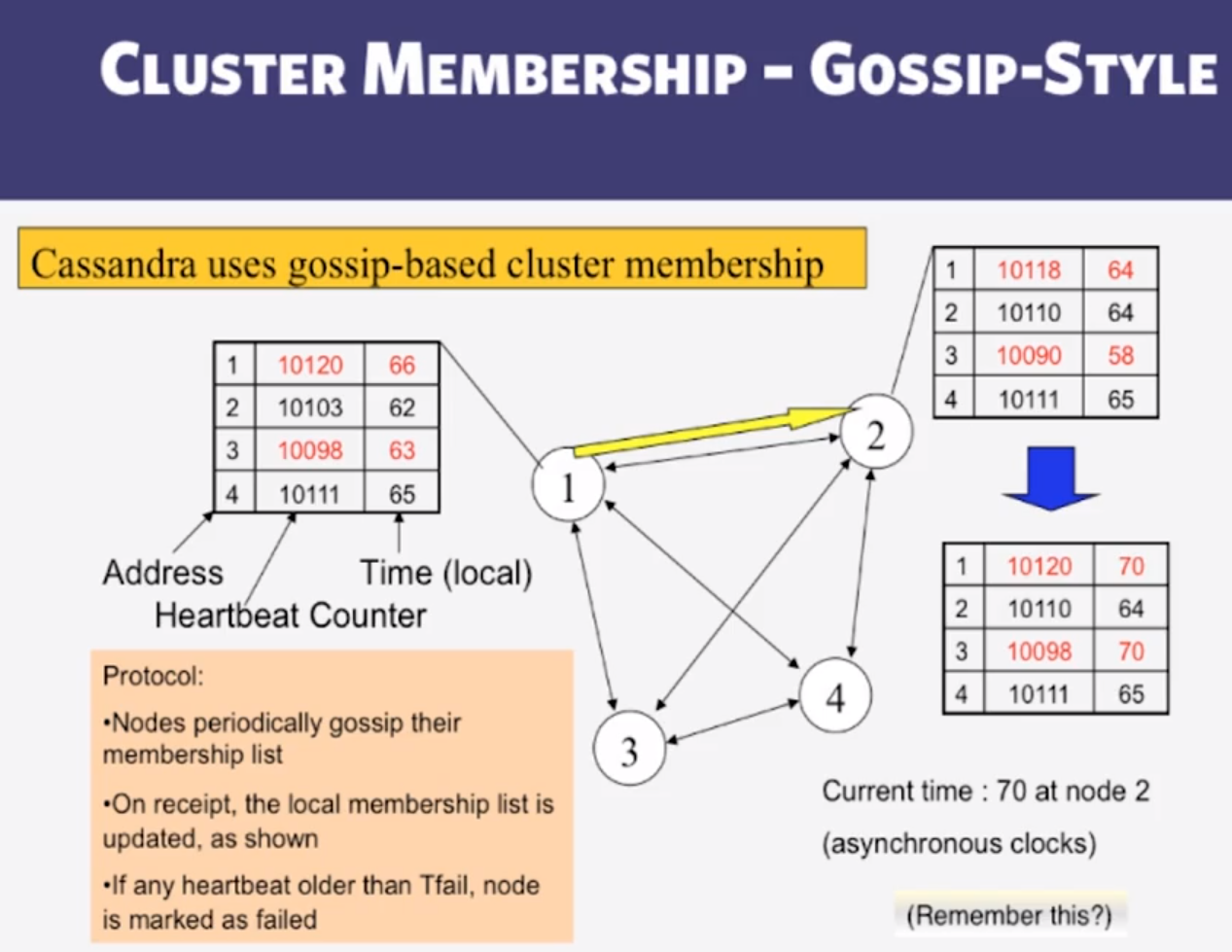
- Suspicion Mechanisms in Cassandra
- Suspicion mechanisms to adaptively set the timeout based on underlying network and failure behavior
- Accrual detector: Failure Detector outputs a vlue (PHI) representing suspicion
- Apps set an appropriate threshold
- PHI calculation for a member
- Inter-arrival times for gossip messages
- PHI(t) = -log(CDF or Provbability(t_now - t_last))/log10
- PHI basically determines the detection timeout, but takes into account historical inter-arrival time variations for gossiped heartbeats.
- In Practice, PHI = 5 => 10-15 sec detection time.
- Cassandra vs RDBMS
- MySQL is one of the most popular (and has been for a while)
- on > 50 GB data
- MySQL
- Writes 300 ms avg
- Reads 350 ms avg
- Cassandra
- Writes 0-12 ms avg
- Reads 15 ms avg
- Orders of magnitude faster What’s the catch? What did we lose?
5-1-3 The CAP theorem
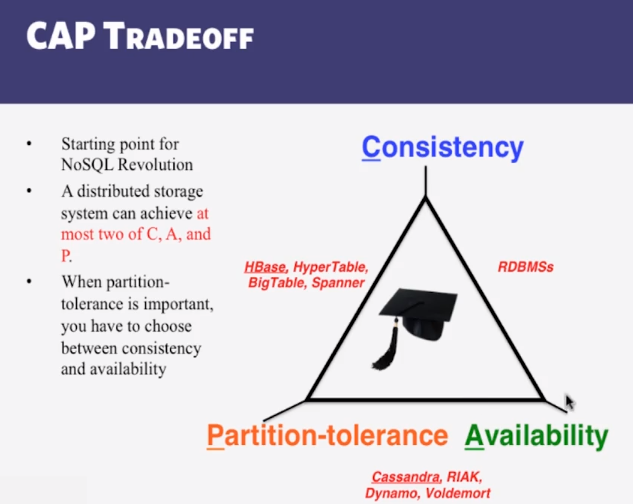
- CAP Theorem
- Prposed by Eric Brewer (Berkeley)
- Proved by Gilbert and Lynch (NUS and MIT)
- In a DS you can stisfy at most 2 out of the 3 guarantees:
- Consistency: all nodes see same data at any time, or reads return latest written value by any client
- Availability: the system allows operations all the time, and operations return quickly
- Partition-tolerance: the system continues to work in spite of network partitions
- Why is availability important?
- Availabilty = reads/writes complete reliably and quickly.
- Measurements have shown that a 500 ms increase in latency for opeartions at Amazon.com or at Google.com can cause a 20% drop in revenue.
- At amazon, each added millisecond of latency implies a $6M yearly loss
- SLAs (Service Level Agreements) written by providers predominantly deal with latencies faced by clients.
- Why is consistency important?
- Consistency = all nodes see same data at any time, or reads return latest written value by any client.
- When you access your bank or investment account via multiple clients (laptop, workstation, phone, tablet), you want the updates done from one client to be visible to other clients.
- When thousands of customers are looking to book a flight, all updates from any client (eg book a flight) should be accessible by other clients.
- why is Partition-tolerance important?
- Partitions can happen across datacenters when the Internet gets disconnected
- internet router outages
- under-sea cables cut
- DNS not working
- Partitions can also occur within a datacenter, eg a rack switch outage
- Still desire system to continue functioning normally under this scenario
- Partitions can happen across datacenters when the Internet gets disconnected
- CAP Theorem fallout
- Since partition-tolerance is essential in today’s cloud computing systems, CAP theorem implies that a system has to choose between consistency and availability
- Cassandra
- Eventual (weak) consistency, availability, partition-tolerance
- Traditional RDBMSs
- strong consistency over availability under a partition
- Eventual consistency
- If all writes stop (to a key), then all its values (replicas) will converge eventually
- If writes continue, then system always tries to keep converging.
- Moving “wave” of updated values lagging behind the lateset values sent by clients, but always trying to catch up.
- May still return stale values to clients (eg if many back-to-back writes)
- But works well when there are a few periods of low writes – system converges quickly.
- RDBMS vs Key-Value stores
- While RDBMS provide ACID
- Atomicity
- Consistency
- Isolation
- Durability
- Key-value stores like Cassandra provide BASE
- Basically Available Soft-state Eventual Consistency
- Prefers Availability over Consistency
- Eventual Consistency says: All values for a given key will eventually be the same after writes have stopped.
- While RDBMS provide ACID
- Back to cassandra: mystery of x
- Cassandra has consistency levels
- Client is allowed to choose a consistency level for each operation (read/write)
- ANY: any server (may not be replica)
- Fastest: coordinator caches write and replies quickly to client
- ALL: all replicas
- Ensures strong consistency, but slowest
- ONE: at least one replica
- Faster than ALL, but cannot tolerate a failure
- QUOROM: quorum across all replicas in all datacenters (DCs)
- global consistency, but still fast
- LOCAL_QUORUM: quorum in coordinator’s DC
- Faster: only waits for quorum in first DC client contacts
- EACH_QUORUM: quorum in every DC
- Lets each DC do its own quorum: supports hierarchical replies
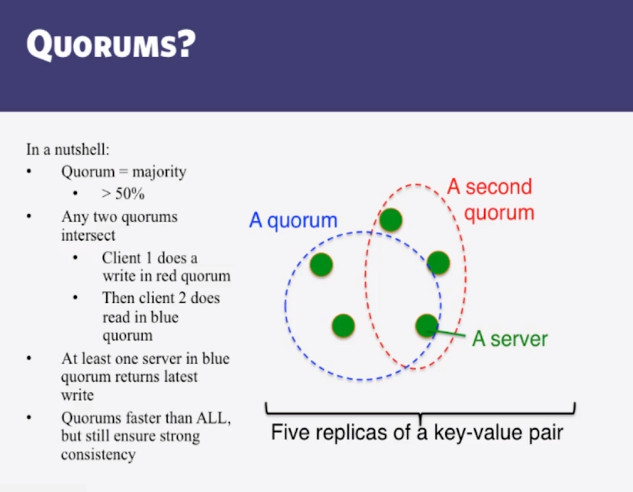
- Quorums in Detail
- Several key-value/NoSQL stores (eg Riak and Cassandra) use quorums
- Reads
- Client specifies value of R ( ≤ N = total number of replicas of that key).
- R = read consistency level.
- Coordinator waits for R replicas to respond before sending result to client.
- In background, coordinator checks for consistency of remaining (N-R) replicas, and initiates read repair if needed.
- Writes come in two flavors
- Client specifies W (≤ N)
- W = write consistency level.
- Client writes new value to W replicas and returns. Two falvors:
- Coordinator blocks until quorum is reached.
- Asynchronous: Just write and return.
- R = read replica count, W = write replica count
- Two necessary conditions:
- W+R > N
- W > N/2
- Select values vased on application
- (W=1, R=1): very few writes and reads
- (W=N, R=1): great for read-heavy workloads
- (W=N/2+1, R=N/2+1): great for write-heavy workloads
- (W=1, R=N): great for write-heavy workloads with mostly one client writing per key
- Types of Consistency
- cassandra offers eventual consistency
5-1-4 The Consistency Spectrum


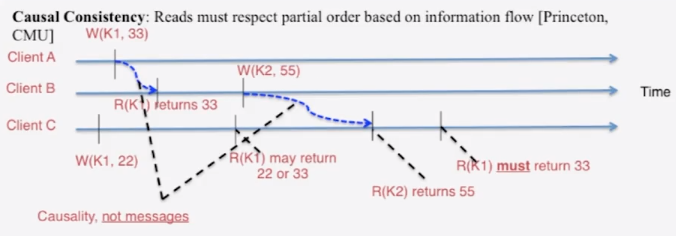
- Strong consistency models
- Linearizability: Each operation by a client is visible (or available) instantaneously to all other clients
- Instantaneously in real time
- Sequential Consistency (Lamport):
- “…the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program.”
- After the fact, find a “reasonable” ordering of the operations (can re-order operations) that obeys sanity (consistency) at all clients, and across clients
- Transaction ACID properties, eg newer key-value/NoSQL stores (sometimes called “NewSQL”)
- Hyperdex (Cornell)
- Spanner (Google)
- Transaction chains (Microsoft Research)
- Linearizability: Each operation by a client is visible (or available) instantaneously to all other clients
5-1-5 HBase
- Cassandra is AP, while HBase is CP
- HBase
- Google’s BigTable was first “blob-based” storage system
- Yahoo! Open-sourced it –> HBase
- Major Apache project today
- Facebook uses HBase internally
- API functions
- Get/Put(row)
- Scan(row range, filter) –range queries
- MultiPut
- Unlike Cassandra, HBase prefers consistency (over availability)
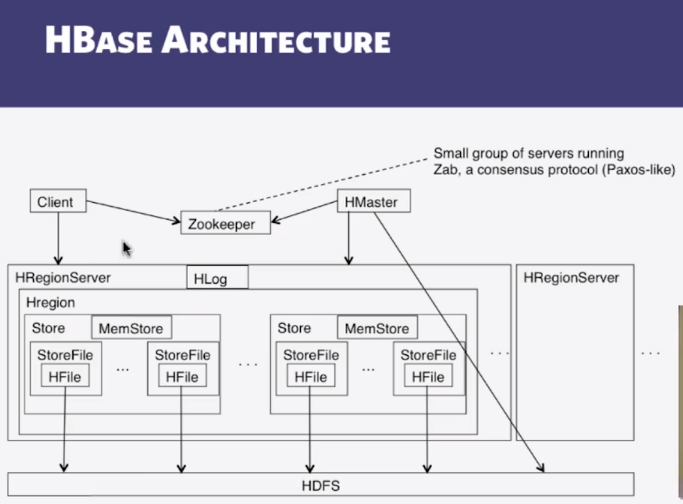
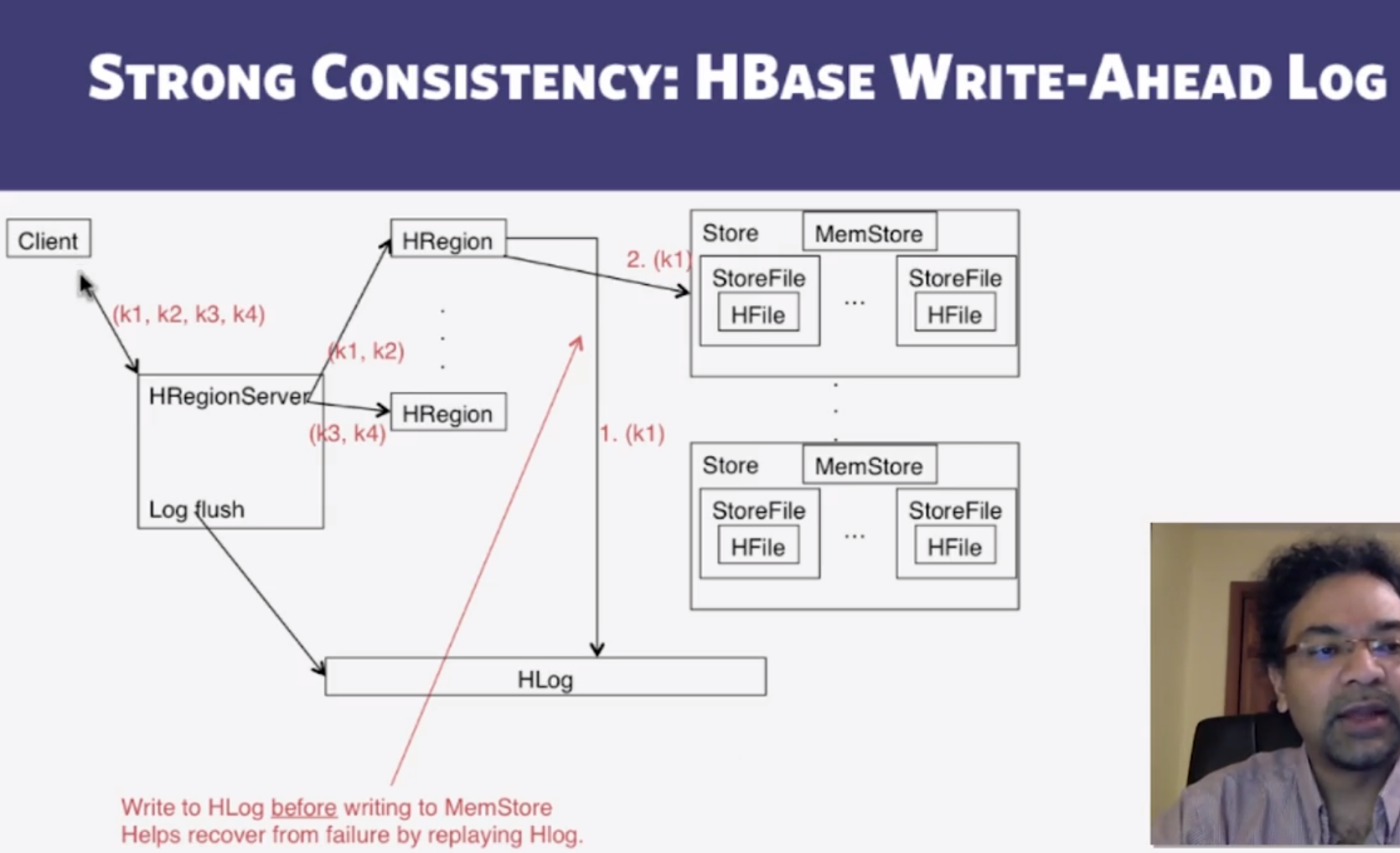
- HBase Storage Hierarchy
- HBase Table
- Split into multiple regions: replicated across servers
- ColumnFamily = subset of columns with similar query patterns
- One Store per combination of ColumnFamily + region
- Memstore for each Store: in-memory updates to Store; flushed to disk when full
- StoreFiles for each store for each region: where the data lives
- HFile
- StoreFiles for each store for each region: where the data lives
- Memstore for each Store: in-memory updates to Store; flushed to disk when full
- Split into multiple regions: replicated across servers
- HFile
- SSTable from Google’s BigTable
- HBase Table
- Log Replay
- After recovery from failure, or upon bootup (HRegionServer/HMaster)
- Replay any stale logs (use timestamps to find out where the databse is with respect to the logs)
- Replay: add edits to the MemStore
- After recovery from failure, or upon bootup (HRegionServer/HMaster)
- Cross-Datacenter Replication
- single Master cluster
- Other Slave clusters replicate the same tables
- Master cluster synchronously sends HLogs over to slave clusters
- Coordination among clusters is via Zookeeper
- Zookeeper can be used like a file system to store control informmation
- /hbase/replication/state
- /hbase/replication/peers/
- /hbase/replication/rs/
- Summary
- Traditional Database (RDBMSs) work with storng consistency, and offer ACID
- Modern workloads don’t need such strong guarantees, but do need fast response times (availability)
- Unfortunately, CAP theorem
- Key-Value/NoSQL systems offer BASE
- Eventual consistency, and a variety of other consistency models striving towards storng consistency
- We discussed design of
- Cassandra
- HBase
5-2-1 Introduction and Basics of Time and Ordering
- Why is it Challenging?
- End hosts in Internet-based systems (like clouds)
- each have their own clocks
- Unlike processors (CPUs) within one server or workstation which share a system lcock
- Processes in Internet-based systems follow an asynchronous system model
- No bounds on
- Message delays
- Processing delays
- Unlike multi-processor (or parallel) systems whcih follow a synchronous system model
- No bounds on
- End hosts in Internet-based systems (like clouds)
- Some definitions
- An Asynchronous Distributed System consists of a number of processes
- Each process has a state (values of variables)
- Each process takes actions to change its state, which may be an instruction or a communication action (send, receive)
- An even is the occurrence of an action
- Each process has a local clock – events within a process can be assigned timestamps, and thus ordered linearly
- But – in a distributed system, we also need to know the time order of events across different processes.
- Clock Skew vs Clock drift
- EAch process (running at some end host) has its own clock.
- When comparing two clocks at two processes:
- Clock Skew = Relative Difference in clock values of two processes
- Liek distance between two vehicles on a road
- Clock Drift = Relative Difference in clock frequencies (rates) of two processes
- Like difference in speeds of two vehicles on the road
- Clock Skew = Relative Difference in clock values of two processes
- A non-zero clock skew implies clocks are not synchronized
- A non-zero clock drift causes skew to increase (eventually)
- If faster vehicle is ahead, it will drift away
- If faster vehicle is behind, it will catch up and then drift away
- How often to Synchronize?
- Maximum Drift Rate (MDR) of a clock
- Absolute MDR is defined relative to Coordinated Universal Time (UTC). UTC is the correct time at any point of time.
- MDR of a process depends on the environment
- Max drift rate between two clocks with similar MDR is 2*MDR
- Given a max acceptable skew M between any pair of clocks, need to synchronize at least once every M/(2*MDR)
- since time = d / r
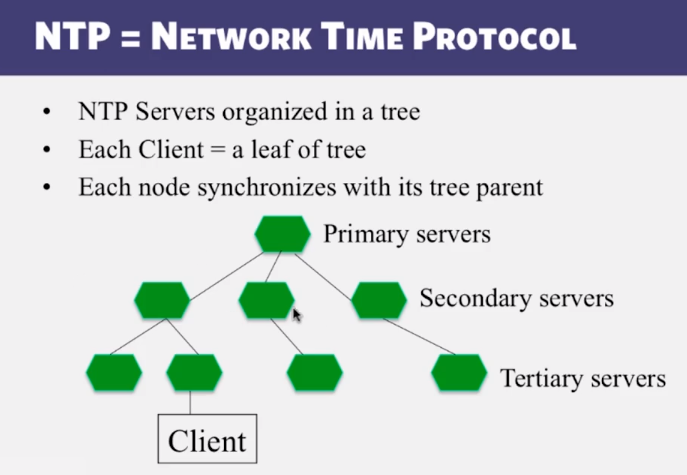
- External vs internal synchronization
- Consider a group of processes
- External Synchronization
- Each process C(i)’s clock is within a bound D of a well-known clock S external to the group
- |C(i)-S| < D at all times
- External clock may be connected to UTC or an atomic clock
- eg, Cristian’s algorithm, NTP
- Internal Synchronization
- Every pair of processes in gorup have clocks within bound D
- |C(i)-C(j)| < D at all times and for all processes i,j
- eg, Berkeley algorithm
- External Synchronization with D => Internal Synchronization with 2*D
- Internal synchronization does not imply External Synchronization
- In fact, the entire system may drift away from the extern clock S!
5-2-2 Cristian’s Algorithm

- Gotchas
- Allowed to increase clock value but should never decrease clock value
- may violate ordering of events within the same process
- Allowed to increase or decrease speed of clock
- if error is too high, take multiple readings and average them
- Allowed to increase clock value but should never decrease clock value
5-2-3 NTP
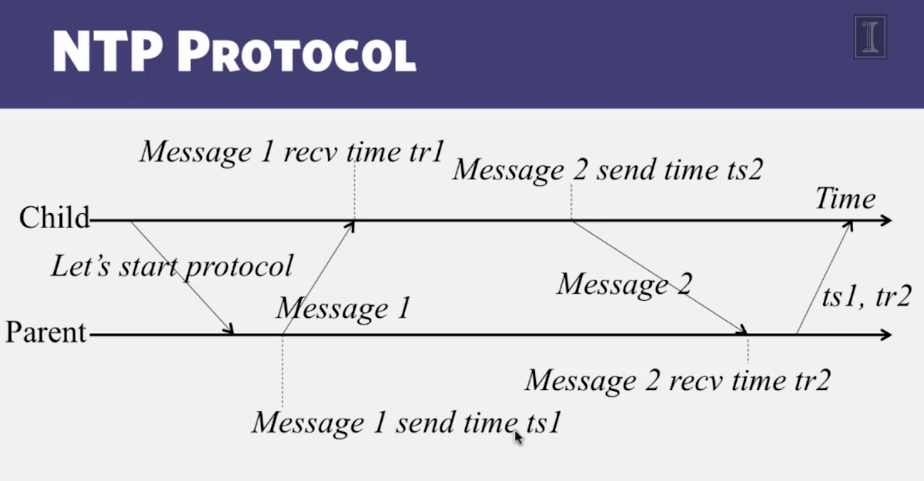


- Gotchas
- We still have a non-zero error!
- WE just can’t seem to get rid of error
- Can’t as long as message latencies are non-zero
- Can we avoid synchronizing clocks altogether, and still be able to order events?
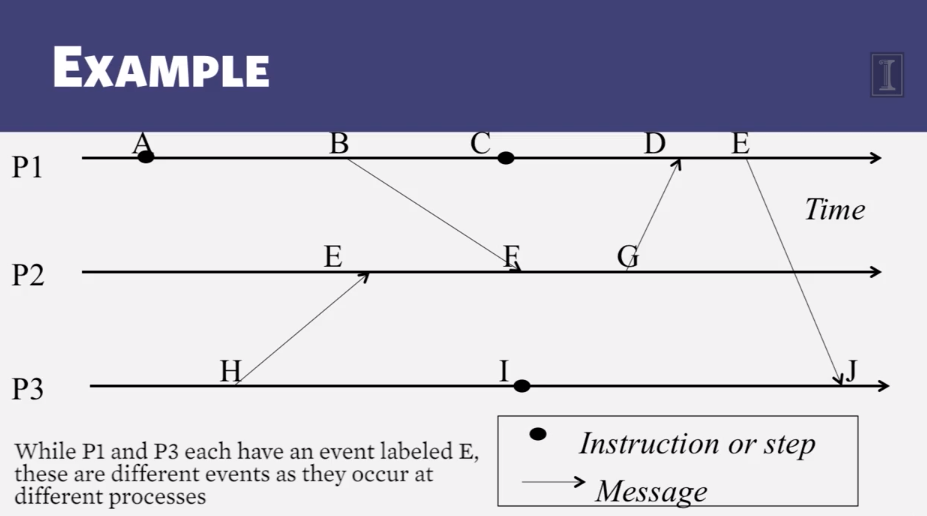
5-2-4 Lamport Timestamps
- Ordering events in a DS
- Hard
- To order events across processes, trying to sync clocks is one approach
- what if we instead assigned timestamps to events that were not absolute time?
- As long as these timestamps obey causality, that would work
- If an event A causally happens before another event B, then timestamp(A) < timestamp(B)
- Humans use Causality all the time
- eg, I enter a house only after I unlock it
- eg, You receive a letter only after I send it
- Logical (Lamport) Ordering
- Proposed by Leslie Lamport in the 1970s
- Used in almost all distributed systems since then
- Almost all cloud computing systems use some form of logical ordering of events

- In practice: Lamport Timestamps
- Goal: assign logical timestamp to each event
- Timestamps obey causality
- rules
- each process uses a local counter which is an integer
- initial value of counter is zero
- A process increments its coutner when a send or an instruction happens at it. The counter is assigned to the event as its timestamp
- A send (message) event carries its timestamp
- For a receive (message) event the coutner is updated by max(local clock, message timestamp) +1
- each process uses a local counter which is an integer

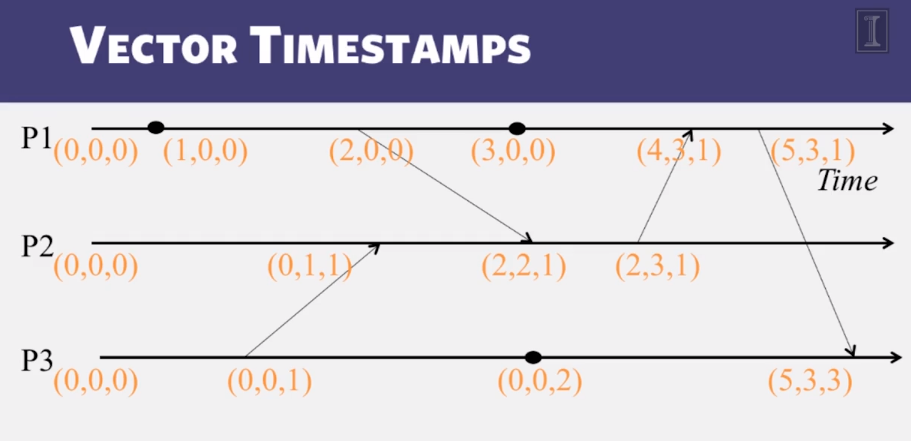
5-2-5 Vector Clocks
- Vector Timestamps
- used in key-value stores like Riak
- Each process uses a vector of integer clocks
- suppose there are N processes in the group 1…N
- Each vector has N elements
- Process i maintains vector Vi[1…N]
- jth element of vector clock at process i, Vi[j], is i’s knowledge of latest events at rpocess j
- Assigning vector timestamps
- incrementing vector clocks
- On an instruction or send event at process i, it increments only its ith elemetn of its vector lcokc
- Each message carries the send-event’s vector timestamp Vmessage>[1…N]
- On receiving a message at process i:
- Vi[i] = Vi[i] + 1
- Vi[j] = max(Vmessage[j], Vi[j]) for j ≠ i
- incrementing vector clocks


CS 427 Software Engineering
Goals and Objectives
Video Lecture Notes
4-1 Definition of Software Architecture
- Definitions of Software ARchitecture
- “A software system’s architecture is the set of of princiapal design decisions about the system.”
- The software architecture of a program or computing system is the structure or strucutures of the system, whcih comprise software elements, the externally visible properties of those elements, and the relationshipts among them.”
- A model of software architecture “consists of three components: elements, form, and rationale.”
- Elements (what): Processing, data, or connecting elements
- Form (how): Constraints (properties, relationships) on the elements
- Rationale (why): System constraints, often derived from system requirements
- Benefits of sofware architecture
- Understanding
- Reuse
- Construction
- Evolution
- Analysis
- Management
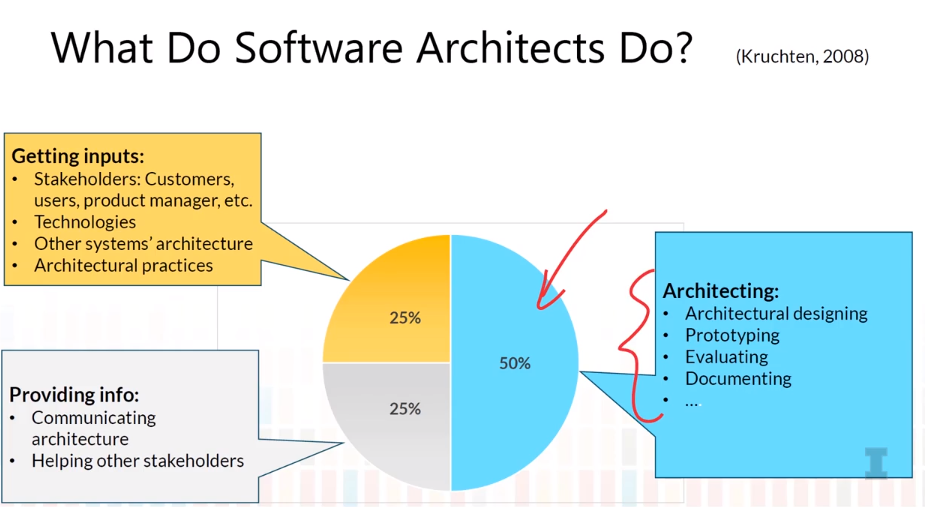
4-2 Software Architect
- Important skills of software architects
- “software architects should design, develop, nurture, and maintain the architecture of the software-intensive systems they are involved with.”
- Domain Knowledge
- Software Development Expertise
- Communication Skills
- “software architects should design, develop, nurture, and maintain the architecture of the software-intensive systems they are involved with.”
4-3 Abstraction
- Definition of Abstraction
- Removing detail to simplify and foucus attention
- Generalizing to identify the common core or essence
- Importance of Abstraction in CS
- “Once you realize that computing is all about constructing, manipulating, and reasoning about abstractions, it becomes clear that an important prerequisiite for writing(good) computer programs is the ability to handle abstractions in a precise manner.”
- “Computer science is not computer programming. Thinking like a computer scientist means more than being able to program a computer. It requires thinking at multiple levels of abstraction.”
- Types of Abstraction in Software Engineering
- Procedural abstraction
- Naming a sequence of instructions
- Parameterizing a procedure
- Data abstraction
- Naming a collection of data
- Data type defined by a set of procedures
- Control abstraction
- Without specifying all register/binary-level steps
- Performance abstraction O(N)
- Procedural abstraction
- Software Development process also has abstractions
- Requirements (What)
- Architecture
- OO Design
- Implementation (How)
- How to get good abstractions
- learn from others
- generalize from examples
- look for/eliminate duplication
- Abstractions can fool you
- suppose a collection c has operation: getItemNumbered(int index)
- How do you iterate?
C++
1
2
3
for (i = 0; i < c.length(); i++){
c.getItemNumbered(i);
}
- But what if the collection is a linked list?
4-4 Modularity
- Functional Independence
- Cohesion (Good)
- Measure of interconnection within a module
- The degree to which one part of a module depends on another
- Maximize cohesion
- Coupling (Less desirable)
- Measure of interconnection among modules
- The degree to which one module depends on others
- Minimize coupling
- Cohesion (Good)
- Major types of cohesion
- Coincidental - grouped by chance (Low cohesion)
- logical - same idea
- temporal - same time
- procedural - one after another
- communicational - shared data
- sequential - output of one being input of the other
- functional - a single well-defined task (high cohesion)
- Information hiding
- EAch module should hide a design decision from others
- Ideally, one design decision per module, but usually design decisions are closely related
- Example design decisions
- Representation of data
- Use of a particular software package
- Use of a particular printer
- Use of a particular operating system
- Use of a particular algorithm
- Other reasons for modularity
- collaborative/distributed development: reduced communication
- security - compartmentalization
- reliability - localization of failure
- Conway’s law: the architecture of a system is the same as the structure of the group that developed it.
- ways to achieve modularity
- reuse a design with good modularity
- think about and hide design decisions
- reduce coupling and increase cohesion
- eliminate duplication
- reduce impact of changes
4-5 Architecture
- Three views of software architecture
- Static view
- Dynamic view
- Deployment view
- Components and connectors
4-6 Architectural Styles
- Architectural Style
- Vocabularly of components and connectors
- Compositions constraints
- Client-server style
- Example: SVN
- Easy to add new clients to structure
- Layered/Tiered style: 3-tier/n-tier client-server (eg local file system)
- Presentation tier
- Logic tier
- data tier
- Pipe-and-filter style
- eg cat contatctbook | grep “illinois” | sort > illini
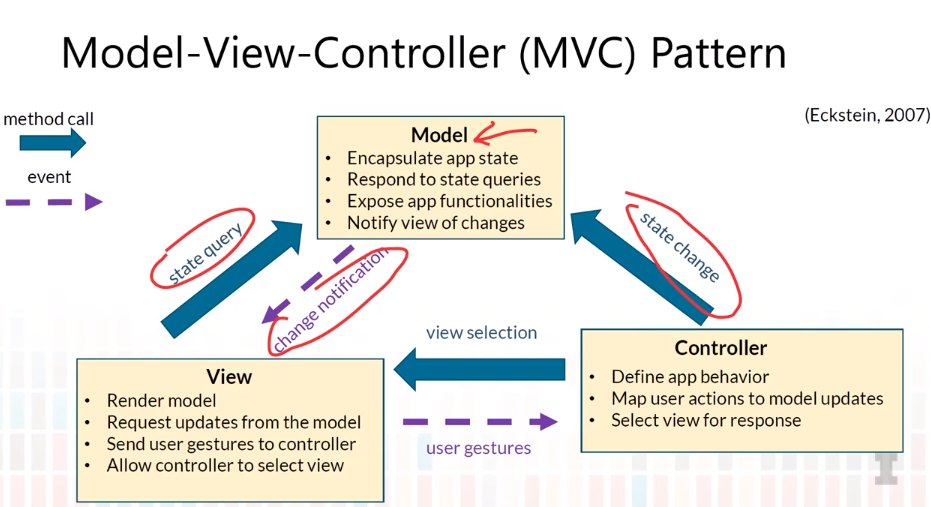
4-7 MVC Pattern
- Architectural Pattern
- A general, reusable solution to a commonly occuring problem in software architecture within a given context.
- Not the same as architectural style
- Vocabularly of components and connectors
- Composition constraints
- Model-View-Controller Pattern