CS 410 : Text Information Systems
Goals and Objectives
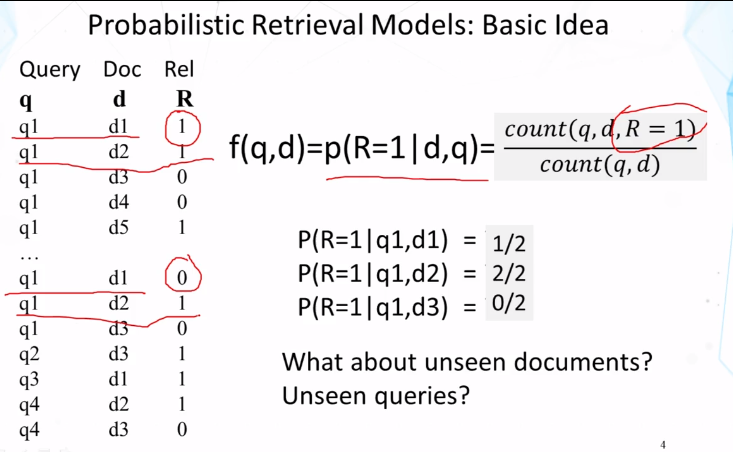
- Explain how to interpret p(R=1|q,d) and estimate it based on a large set of collected relevance judgments (or clickthrough information) about query q and document d.
- Explain how to interpret the conditional probability p(q|d) used for scoring documents in the query likelihood retrieval function.
- Explain what a statistical language model and a unigram language model are.
- Explain how to compute the maximum likelihood estimate of a unigram language model.
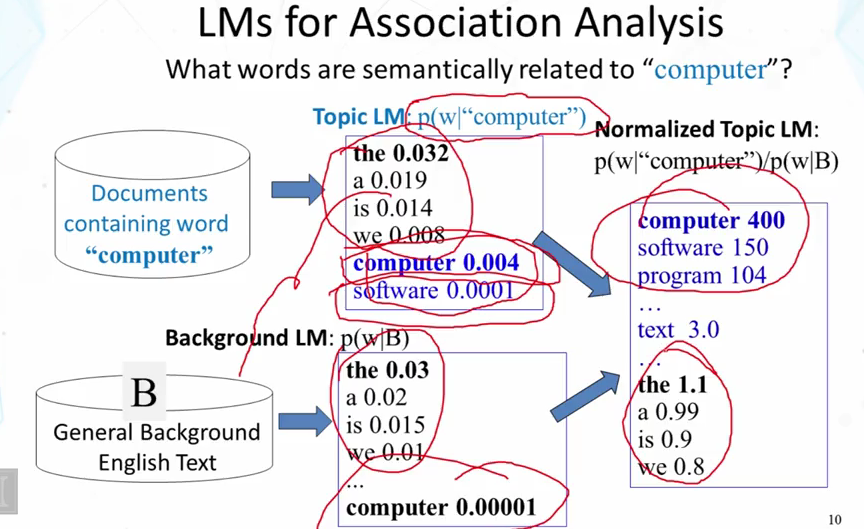
- Explain how to use unigram language models to discover semantically related words.
- Compute p(q|d) based on a given document language model p(w|d).
- Explain what smoothing does.
- Show that query likelihood retrieval function implements TF-IDF weighting if we smooth the document language model p(w|d) using the collection language model p(w|C) as a reference language model.
- Compute the estimate of p(w|d) using Jelinek-Mercer (JM) smoothing and Dirichlet Prior smoothing, respectively.
Guiding Questions
- Given a table of relevance judgments in the form of three columns (query, document, and binary relevance judgments), how can we estimate p(R=1|q,d)?
- How should we interpret the query likelihood conditional probability p(q|d)?
- What is a statistical language model? What is a unigram language model? How many parameters are there in a unigram language model?
- How do we compute the maximum likelihood estimate of the unigram language model (based on a text sample)?
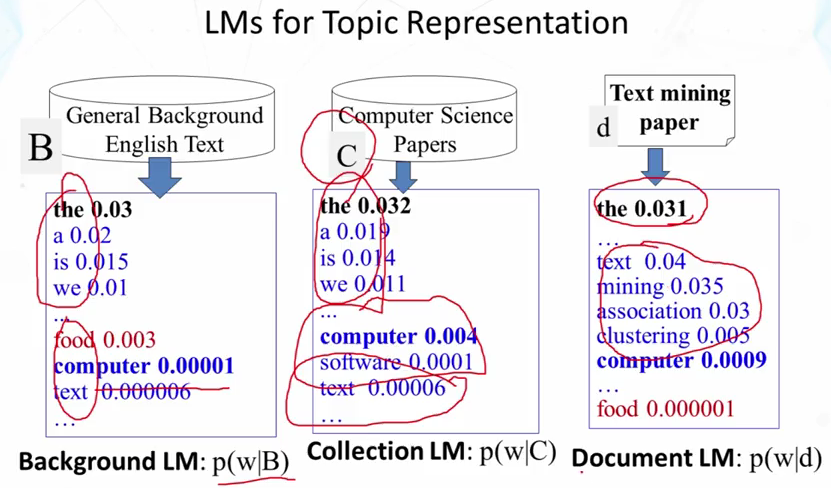
- What is a background language model? What is a collection language model? What is a document language model?
- Why do we need to smooth a document language model in the query likelihood retrieval model? What would happen if we don’t do smoothing?
- When we smooth a document language model using a collection language model as a reference language model, what is the probability assigned to an unseen word in a document?
- How can we prove that the query likelihood retrieval function implements TF-IDF weighting if we use a collection language model smoothing?
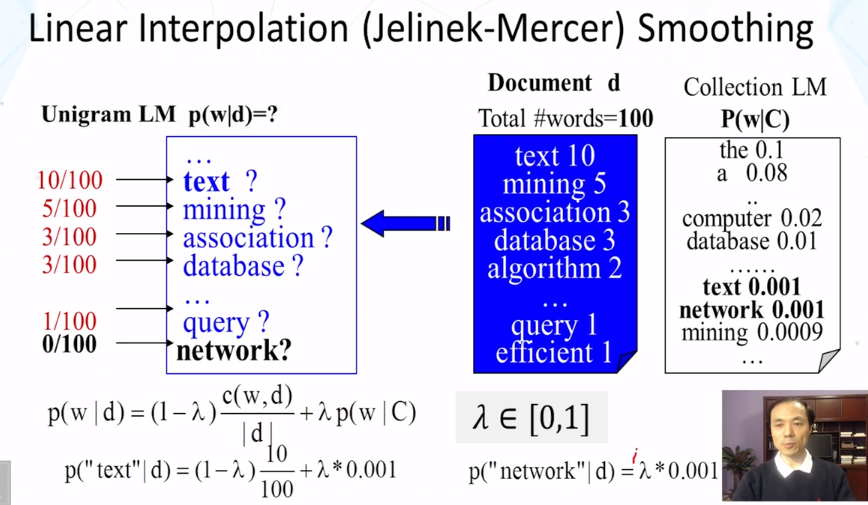
- How does linear interpolation (Jelinek-Mercer) smoothing work? What is the formula?
- How does Dirichlet prior smoothing work? What is the formula?
- What are the similarities and differences between Jelinek-Mercer smoothing and Dirichlet prior smoothing?
Additional Readings and Resources
- C. Zhai and S. Massung. Text Data Management and Analysis: A Practical Introduction to Information Retrieval and Text Mining, ACM Book Series, Morgan & Claypool Publishers, 2016. Chapter 6 - Section 6.4
Key Phrases and Concepts
- p(R=1|q,d) ; query likelihood, p(q|d)
- Statistical and unigram language models
- Maximum likelihood estimate
- Background, collection, and document language models
- Smoothing of unigram language models
- Relation between query likelihood and TF-IDF weighting
- Linear interpolation (i.e., Jelinek-Mercer) smoothing
- Dirichlet Prior smoothing
Video Lecture Notes
4.1 : Probabilistic Retrieval Model
- Many different retrieval models:
- Probabilistic models: f(d,q) = p(R=1|d,q), R ∈ {0,1}
- Classic probabilistic model -> BM25
- Language model -> Query Likelihood
- Divergence-from-randomness model -> PL2
- p(R=1|d,q) ≈ p(q|d,R=1)
- If a user likes document d, how likely would the user enter query q (in order to retrieve d)?
- Probabilistic models: f(d,q) = p(R=1|d,q), R ∈ {0,1}
- Instead, we prefer to use p(q|d,R=1):
- Assume a user formulates a query based on an “imaginary relevant document”

4.2 : Statistical Language Models
- What is a statistical language model?
- A probability distribution over word sequences
- Context Dependent
- Can also be regarded as a probabilistic mechanism for “generating” text, thus also called a “generative” model.
- Why is a LM useful?
- Quantify the uncertainties in natural language
- Allows us to answer questions like:
- Given that we see “John” and “feels”, how likely will we see “happy” as opposed to “habit as the next word? (speech recognition)
- Given that we observe “baseball” three times and “game” once in a news article, how likely is it about “sports”? (text categorization, information retrieval)
- Given that a user is interested in sports news, how likely would the user use “baseball” in a query? (information retrieval)
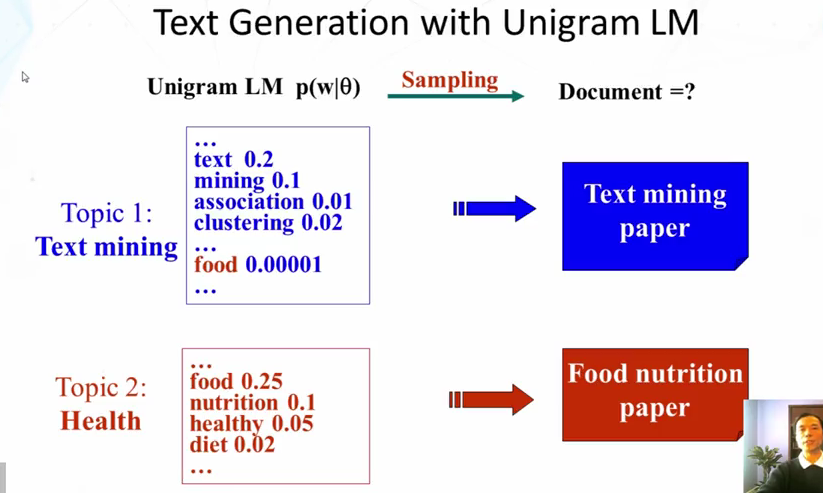
- The Simplest Language Model: Unigram LM
- Generate text by generating each word INDEPENDENTLY
- thus, p(w1, w2, …wn) = p(w1)p(w2)…p(wn)
- Parameters: {p(wi)} p(w1)+…+p(wn)=1 (N is vocabularly size)
- Text = sample drawn according to this word distribution

4.3 : Query Likelihood Retrieval Function
- p(q|d), if the user is thinking of this doc, how likely would she pose this query?

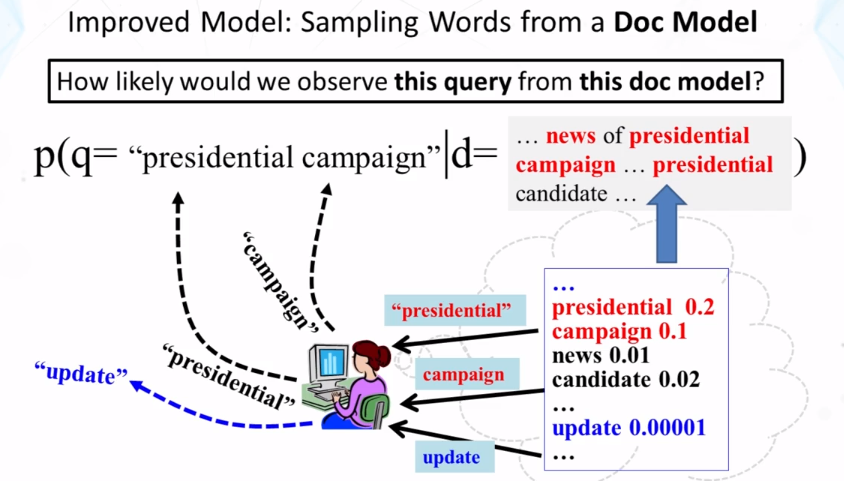

4.4 : Ranking Function based on Query likelihood
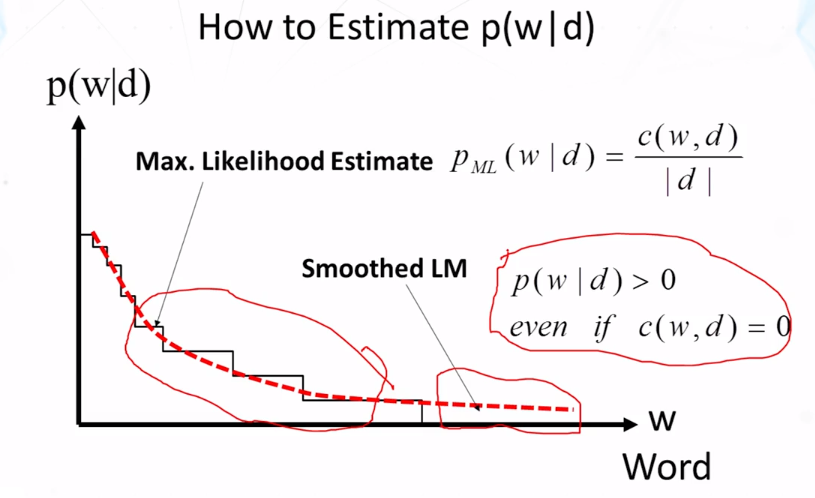
- Key Question: what probability should be assigned to an unseen word?
- Let the probability of an unseen word be proportional to its probability given by a refernce LM
- One possibility: Reference LM = Collection LM
- p(w|d) = {Pseen(w|d), if w is seen in d} , {αdP(w|C), otherwise}

4.5 : Statistical Language Model - Part 2


4.6 SMoothing Methods - Part 1


4.7 : Smoothing Methods - Part 2



CS 425 : Distributed Systems
Goals
- Know how Napster, Gnutella, FastTrack, and BitTorrent work.
- Know and analyze how distributed hash tables work (Chord, Pastry, and Kelips).
Key Concepts
- Peer-to-peer systems
- Industrial P2P systems: Napster, Gnutella, FastTrack, BitTorrent
- Distributed hash tables: Chord, Pastry, Kelips
Guiding Questions
- What is the difference between how Napster clients and Gnutella clients search for files?
- What is the difference between Gnutella and FastTrack?
- What is BitTorrent’s tit for tat mechanism?
- What is consistent hashing?
- Why are DHTs efficient in searching?
- How does Chord route queries?
- How does Pastry route queries?
- How does Kelips route queries?
- What is churn in P2P systems?
- How does Chord maintain correct neighbors in spite of failures and churn?
Readings and Resources
Video Lecture Notes
4.1 P2P Systems Introduction
- P2P first distributed systems that seriously focused on scalability with respect to number of nodes
- Widely-deployed P2P Systems
- Napster
- Gnutella
- Fasttrack (Kazaa, Kazaalite, Grokster)
- BitTorrent
- P2P Systems with Provable Properties
- Chord
- Pastry
- Kelips
4.2 Napster
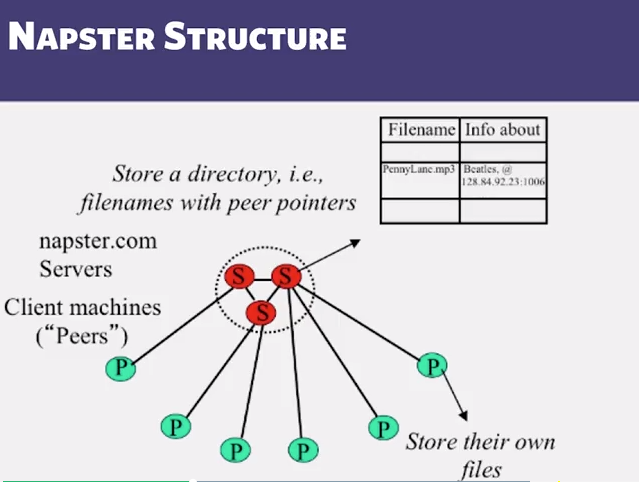
- Napster Operations:
- Client: Connect to a Napster server
- Upload list of music files that you want to share
- Server maintains list of <filename, ip_address, portnum> tuples. Server stores no files.
- Search
- Send server keywords to search with
- (server searchs its list with the keywords)
- Server returns a list of hosts -<ip_address, portnum> tuples - to client
- client pings each host in the list to find transfer rates
- Client fetches file from best host
- All communication uses TCP (Transmission control Protocol)
- Reliable and ordered networking protocol (TCP)
- Client: Connect to a Napster server
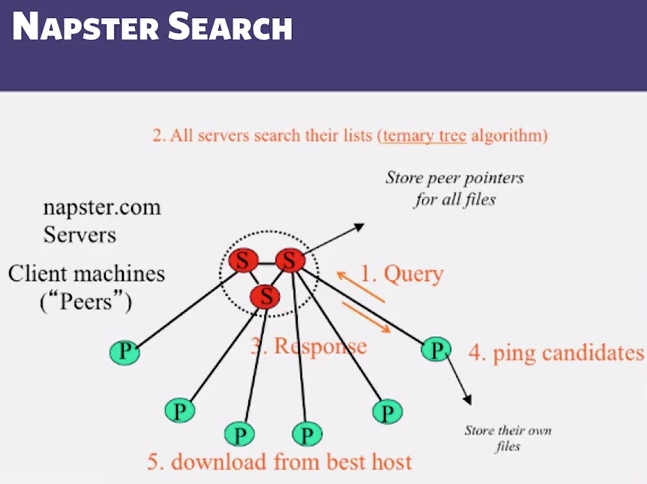
- Ternary trees store the directory information (3 children per parent)
- Joining a P2P System
- Can be used for any p2p system
- Send an http request to well-known url for that p2p service -eg: www.myp2pservice.com
- Message routed (after lookup in DNS=Domain Name System) to introducer, a well known server that keeps track of some recently joined nodes in p2p system
- Introducer initializes new peer’s neighbor table
- Can be used for any p2p system
- Problems
- Centralized server a source of congestion
- Centralized server single point of failure
- No security: plaintext messages on passwds
- napster.com declared to be responsible for users’ copyright violation
- “Indirect infringement”
- events led to Gnutella development
4.3 Gnutella
- Gnutella does:
- eliminate the servers
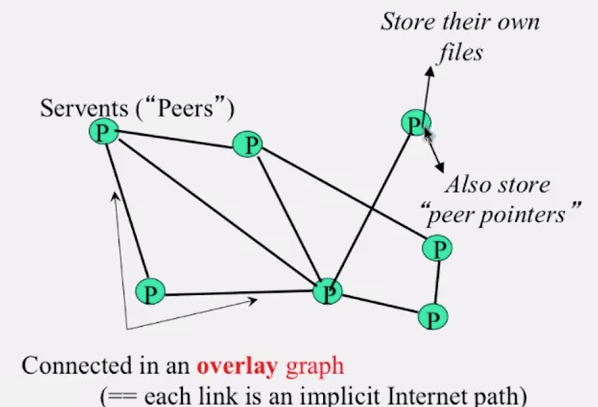
- Client machines search and retrieve amongst themselves (clients act as teh servers)
- Clients act as servers too, called servents
- 3/2000 released by AOL, immediately withdrawn due to copyright issues, 88K users by 3/2003
- Original design underwent several modifications
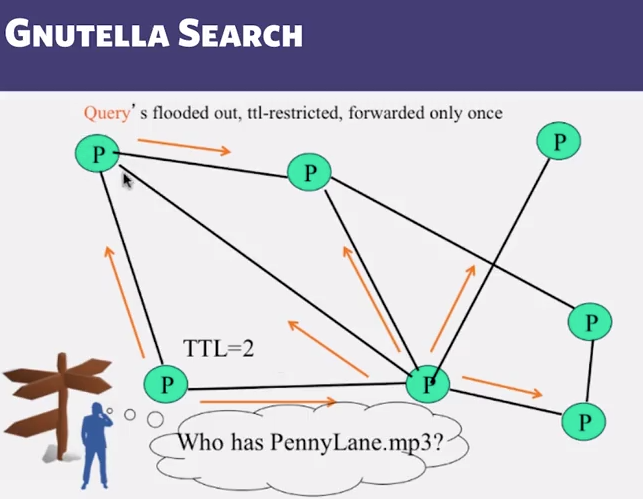
- How do I search for my files?
- Gnutella routes different messages with the overlay graph
- Protocol has 5 main message types
- Query (search)
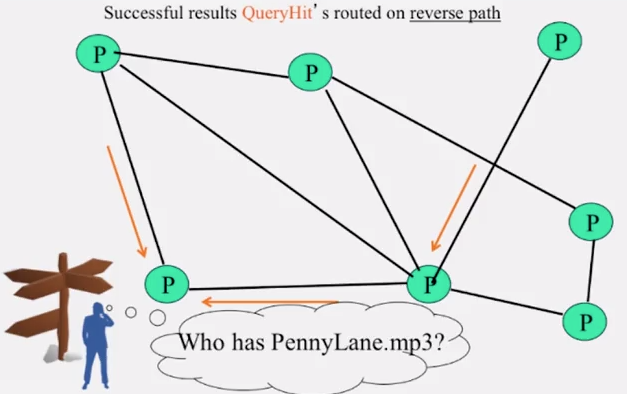
- QueryHit (response to query)
- Ping (to probe network for other peers)
- Pong (reply to ping, contains address of another peer)
- Push (used to initiate file transfer)
- We’ll go into the message structure and protocol now
- All fields except IP address are in little-endian format
- Little endian example: 0x12345678 stored as 0x78 in lowest address byte, then 0x56 in next, and so on.



- Avoiding Excessive Traffic
- To avoid duplicate transmissions, each peer maintains a list of recently received messages
- Query forwarded to all neighbors except peer from which received
- Each Query (identified by DescriptorID) forwarded only once
- QueryHit routed back only to peer from which Query received with same DescriptorID
- For flooded messages, duplicates with same DescriptorID and Payload descriptor are dropped
- QueryHit with DescriptorID for which Query not seen is dropped.

- HTTP is file transfer protocol. why?
- Because it’s standard, well-debugged, and widely used.
- Why the “range” field in teh GET request?
- To support partial file transfers.
- What if responder is behind firewall that disallows incoming connections? (drops it)
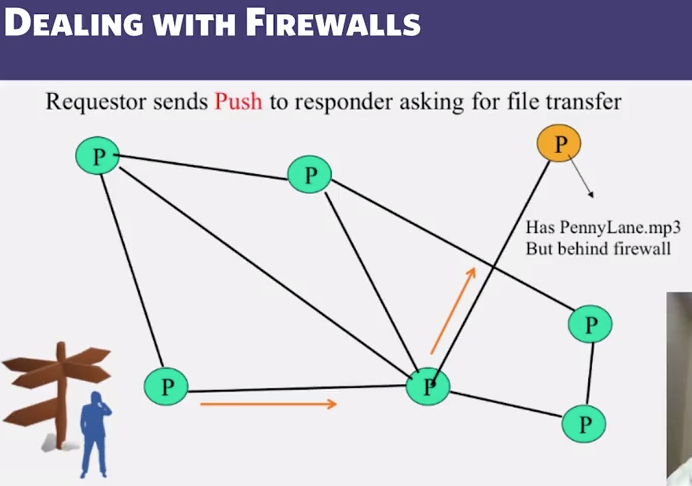
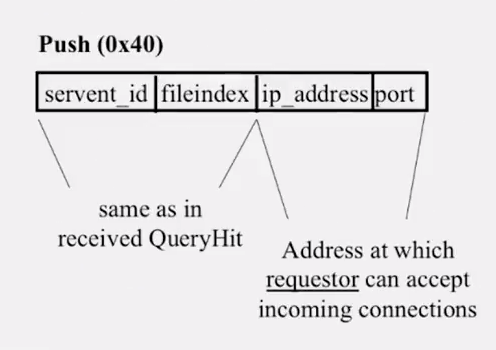
- Responder establishes a TCP connection at ip_address, port specified. Sends: GIV
: / \n\n - Requestor then sends GET to responder (as before) and file is transferred as explained earlier.
- What if requestor is behind firewall too?
- Gnutella gives up
- If the responding peer is behind a firewall, which of the following statements ARE TRUE about Gnutella?
- A Push message can be sent to it since it is already connected to its peers.
- A modified version of Gnutella could use the overlay links themselves to transfer the file (though this may be slow).
- When a Gnutella peer receives a Ping message from one of its neighbors, which of the following actions does it perform? (all are correct)
- It forwards it to appropriate neighbors after checking TTL.
- It creates a Pong message about itself and reverse routes it.
- If it was the original peer that initiated the Ping, it uses received Pong responses to update its membership lists.
- It reverse routes any Pong messages it receives.

- Gnutella Summary
- No servers
- Peers/servents maintain “neighbors”, this forms an overlay graph
- Peers store their own files
- Queries flooded out, ttl restricted
- QueryHit (replies) reverse path routed
- Supports file transfer through firewalls
- Periodic Ping-pong to continuously refresh neighbor lists
- List size specified by user at peer : heterogeneity means some peers may have more neighbors
- Gnutella found to follow power law distribution: P(#Links = L) ~ L-k (k is a constant)
- Problems
- Ping/Pong constituted 50% traffic
- Solution: Multiplex, cache and reduce frequency of pings/pongs
- Repeated searches with same keywords
- Solution: Cache Query, QueryHit messages
- Modem-connected hosts do not have enough bandwidth for passing Gnutella traffic
- Solution: use a central server to act as proxy for such peers
- Another solution:
- FastTrack System (soon)
- Large number of freeloaders
- 70% of users in 2000 were freeloaders
- Only download files, never upload own files
- Flooding causes excessive traffic
- Is there some way of maintaining meta-information about peers that leads to more intelligent routing?
–> Structured Peer-to-peer systems, eg Chord System (coming up soon)
- Is there some way of maintaining meta-information about peers that leads to more intelligent routing?
- Ping/Pong constituted 50% traffic
4.4 FastTrack and BitTorrent
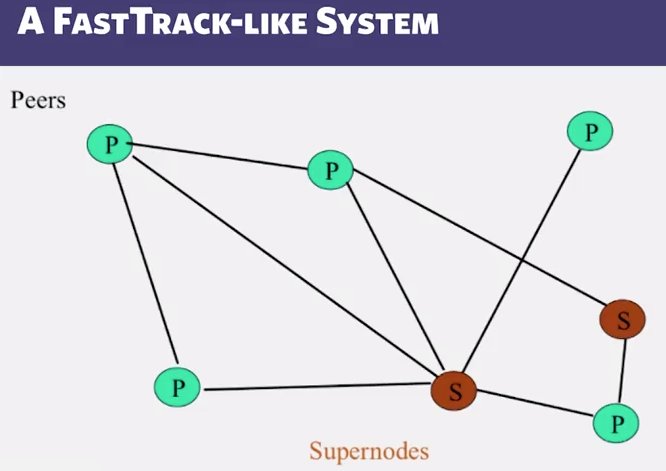
- FastTrack
- Hybrid of gnutella and napster
- Takes advantage of “healthier” participants in the system
- Underlying technology in Kazaa, KazaaLite, Grokster
- Proprietary protocaol, but some details available
- Gnutella, but with some peers designated as supernodes.
- A supernode stores a directory listing a subset of nearby (<filename, peer pointer>), similar to Napster servers
- Supernode membership changes over time (a member cannot declare itself a supernode)
- Any peer can become (and stay) a supernode, provided it has earned enough reputation
- Kazaalite: participation level (=reputation) of a user between 0 and 1000, initially 10, then affected by length of periods of connectivity and total number of uploads
- More sophisticated Reputation schemes invented, especially based on economics (See P2PEcon Workshop)
- A peer searches by contacting nearby supernode.
- Supernodes get advantage of having information readily available in its structure so it’s faster to look up stuff.
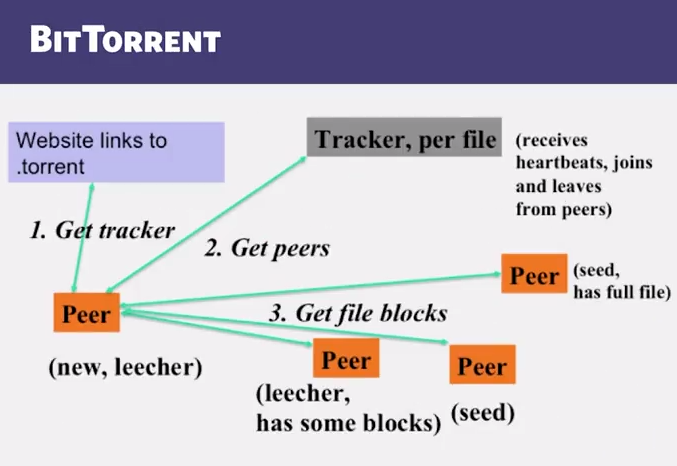
- BitTorrent
- File split into blocks (32 KB - 256 KB)
- Download Local Rarest First block policy: prefer early download of blocks that are least replicated among neighbors
- Exception: New node allowed to pick one random neighbor: helps in bootstrapping
- Tit for tat bandwidth usage: Provide blocks to neighbors that provided it the best download rates
- Incentive for nodes to provide good download rates
- Seeds do the same too
- Choking: Limit number of neighbors to which concurrent uploads <= a number (eg, 5), ie, the “best” neighbors
- Everyone else choked
- Priodically re-evaluate this set (eg, every 10 s)
- Optimistic unchoke: periodically (eg, ~30s), unchoke a random neighbor - helps keep unchoked set fresh
-
Choking helps limit how many peers are uploading, to prevent overwhelming upload bandwidth.
- Why are random choices used in the BitTorrent Choking policy?
- To avoid the system from getting stuck where only a few peers receive service (correct)
- To ensure that all peers receive uniform download speed (incorrect)
- To ensure Tit for Tat bandwidth usage (incorrect)
4.5 Chord
- DHT: Distributed Hash Table
- A hash table allows you to insert, lookup and delete objects with keys.
- A distributed hash table allows you to do the same in a distributed setting (objects=files)
- Performance concerns:
- Load balancing
- Fault-tolerance
- Efficiency of lookups and inserts
- Locality
- Napster, Gnutella, FastTrack are all DHTs (sort of)
- So is Chord, a structured peer to peer ssytem that we study next
- Chord:
- Developers: I Stoica, D Karger, F Kaashoek, H Balakrishnan, R Morris, Berkeley and MIT
- Intelligent choice of neighbors to reduce latency and message cost of routing (lookups/inserts)
- Uses Consistent Hashing on node’s (peer’s) address
- SHA-1(ip_address.port) –> 160 bit string
- Truncated to m bits
- Called peer id (number between 0 and 2m - 1)
- Not unique but ide conflicts very unlikely
- Can then map peers to one of 2m logical points on a circle
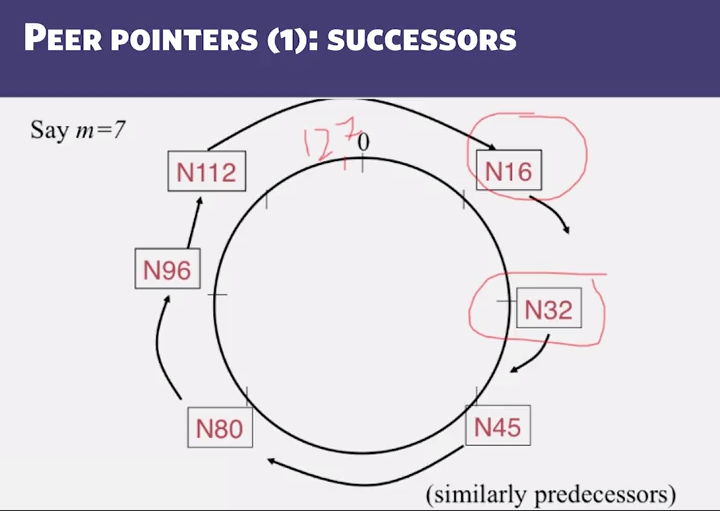
- What are the types of neighbors used in a Chord P2P system (All are correct)?
- Successors
- Finger tables
- Predecessors (if needed)
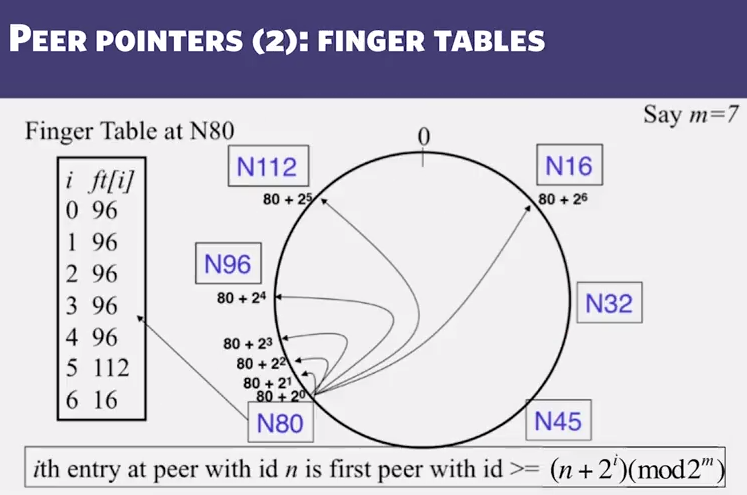
- In a Chord P2P system with m=8, a peer with id 33 is considering the following peers for its i=3 finger table entry: 40, 42, and 44. Which one is the best (correct) choice?
- 33 + 2^3 = 41, first number that is >= to that is 42
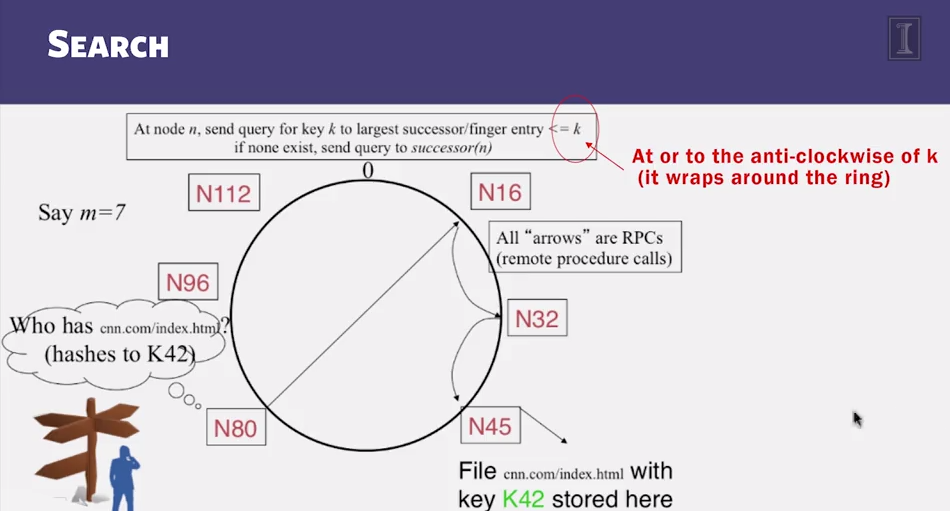
- what about the files?
- Filenames also mapped using same consistent hash function
- SHA-1(filename) –> 160 bit string (key)
- File is stored at first peer with id greater than or equal to its key (mod 2m)
- File cnn.com/index.html that maps to key K42 is stored at first peer with id greater than 42
- Note that we are considering a different file-sahring application here: cooperative web caching
- The same discussion applies to any other file sharing application, including that of mp3 files.
- Consistent Hashing => with K keys and N peers, each peer stores O(K/N) keys (ie, < c.K/N, for some constant c) (ie, good load balancing among the peers)
- In a Chord ring with m=7, three successive peers have ids 12, 19, 33 (there are other peers in the system too, but not in between 12 and 33). If the number of files is large and a uniform hash function is used, which of the following is true?
- Peer 33 stores about double the number of files as peer 19.
- Filenames also mapped using same consistent hash function


4.6 Failures in Chord
- Search under peer failures
- Lookup fails ( N16 does not know N45, when N32 fails)
- Solution: maintain multiple successors, but how many?
- Choosing 2log(N) successors suffices to maintain lookup correctness with high probability (ie, ring connected)
- Say 50% of nodes fail
- Pr(at given node, at least one successor alive) = 1 - (1/2)^(2logN) = 1 - 1/N^2
- Pr(above is ttrue at all alive nodes )= (1 - 1/N^2)^(N/2) = e^(-1/2N) ~ 1
- Lookup fails ( N45 fails)
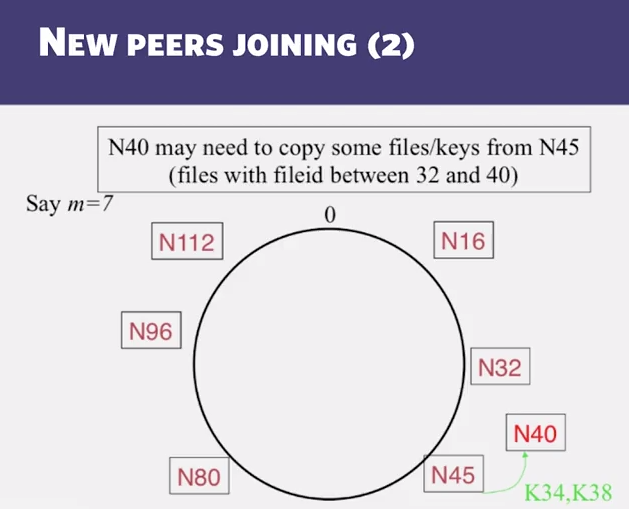
- Solution: replicate file/key at r successors adn predecessors)
- Lookup fails ( N16 does not know N45, when N32 fails)
- Need to deal with dynamic changes
- Peers fail (we’ve discussed this)
- New peers join
- Peers leave
- p2p systems have a high rate of churn (node join, leave and failure)
- 25% per hour in Overnet (eDonkey)
- 100% per hour in gnutella
- Lower in managed clusters
- Common feature in all distributed systems, including wide-area (eg PlanetLab), clusters (eg Emulab), clouds (eg AWS) etc
- p2p systems have a high rate of churn (node join, leave and failure)
- So, all the time, need to: –> Need to update successors and fingers, and copy keys
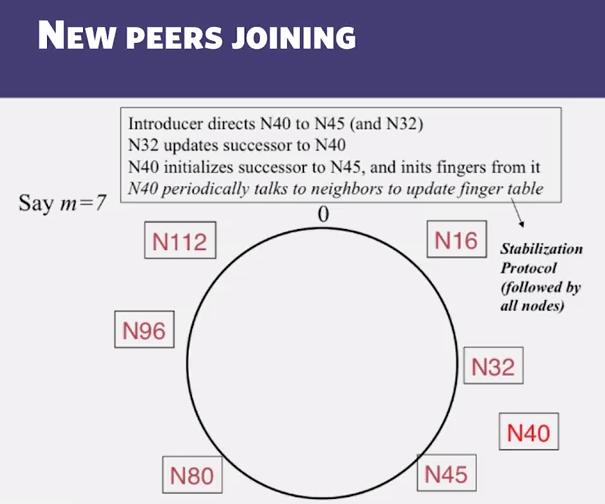
- New peers joining:
- A new peer affects O(log(N)) other finger entries in teh system, on average
- Number of messages per peer join = O(logN*logN)
- Similar set of operations for dealing with peers leaving
- For dealing with failures, also need failure detectors (we’ll see these later in the course!)
- Stabilization Protocol
- Concurrent peer joins, leaves, failures might cause loopiness of pointers, and failure of lookups
- Chord peers periodically run a stabilization algorithm that checks and updates pointers and keys
- Ensures non-loopiness of fingers, eventual success of lookups and O(logN) lookups with high probability
- Each stabilization round at a peer involves a constant number of messages
- Strong stability takes O(N^2) stabilization rounds
- For more see [techReport on Chord webpage]
- Concurrent peer joins, leaves, failures might cause loopiness of pointers, and failure of lookups
- Churn
- When nodes are consttantly joining, leaving, failing
- Significant effect to consider: traces from the Overnet system show hourly peer turnover rates (churn) could be 25-100% of total number of nodes in system
- Leads to excessive (unnecessary) key copying (remember that keys are replicated)
- Stabilization algorithm may need to consume more bandwidth to keep up
- Main issue is that files are replicated, while it might be sufficient to replicate only meta information about files
- Alternatives
- Introduce a level of indirection (any p2p system)
- Replicate metadata more, eg, Kelips (later in this lecture series)
- Churn leads to which of the following behaviors in Chord (all are correct)?
- Successors being continuously updated
- Finger tables being continuously updated
- Files being continuously copied to the correct storing servers
- When nodes are consttantly joining, leaving, failing
- Virtual nodes
- Hash can get non-uniform –> Bad load balancing
- Treat each node as multiple virtual nodes behaving independently
- Each joins the system
- Reduces variance of load imabalance
- Hash can get non-uniform –> Bad load balancing
4.7 Pastry
- Pastry
- Designed by Anthony Rostron (MS Reserach) and Peter Druschel (Rice University)
- Assigns ids to nodes, just like Chord (using a virtual ring)
- Leaf Set Each node knows its successor(s) and predecessor(S)
- Pastry Neighbors
- Routing tables based prefix matching
- Think of hypercube routing
- Routing is thus based on prefix matching, and is thus log(N)
- And hops are short (in the underlying network)
- And hops are short (in the underlying network)
- Routing tables based prefix matching
- Pastry Routing
- Consider a peer with id 01110100101. It maintains a neighbor peer with an id matching each of the following prefixes (* = starting bit differing from this peer’s corresponding bit):
- *
- 0*
- 01*
- 011*
- … 0111010010*
- When it needs to route to a peer, say 01110111001, it starts by forwarding to a neighbor with the largest matching prefix, ie, 011101*
- Consider a peer with id 01110100101. It maintains a neighbor peer with an id matching each of the following prefixes (* = starting bit differing from this peer’s corresponding bit):
- Pastry Locality
- For each prefix, say 011*, among all potential neighbors with a matching prefix, the neighbor with the shortest round-trip-time is selected
- Since shorter prefixes have many more candidates (spread out throughout the Internet), the neighbors for shorter prefixes are likely to be closer than the neighbors for longer prefixes
- Thus, in the prefix routing, early hops are short and later hops are longer
- Yet overall “stretch”, compared to direc Internet path, stays short.
- A Pastry peer has two neighbors for prefixes of 101* and 101110* respectively. Which of these is more likely to respond to a message faster?
- The 101* neighbor
- The 101* neighbor
- Summary of Chord and Pastry
- Chord and Pastry protocols
- More structured than Gnutella
- Black box lookup algorithms
- Churn handling can get complex
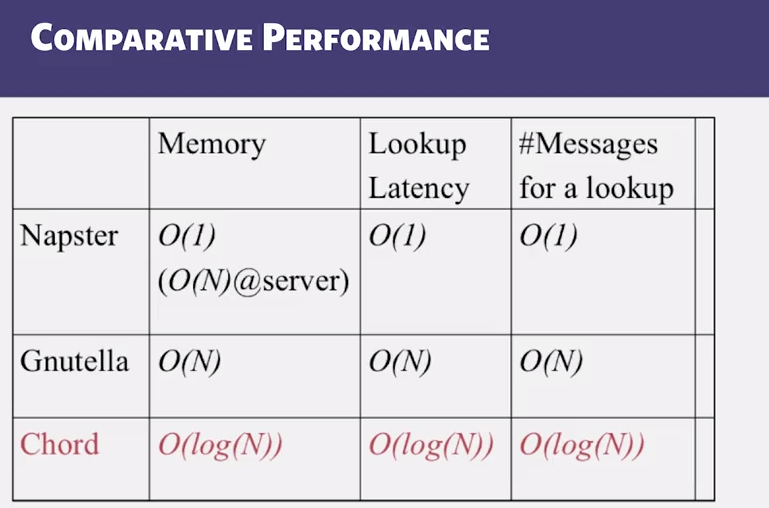
- O(logN) memory and lookup cost
- O(logN) lookup hops may be high
- Can we reduce the number of hops?
- Chord and Pastry protocols
4.8 Kelips
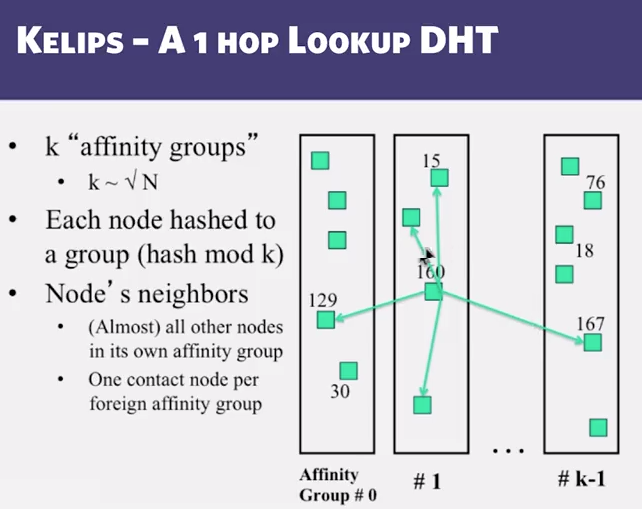

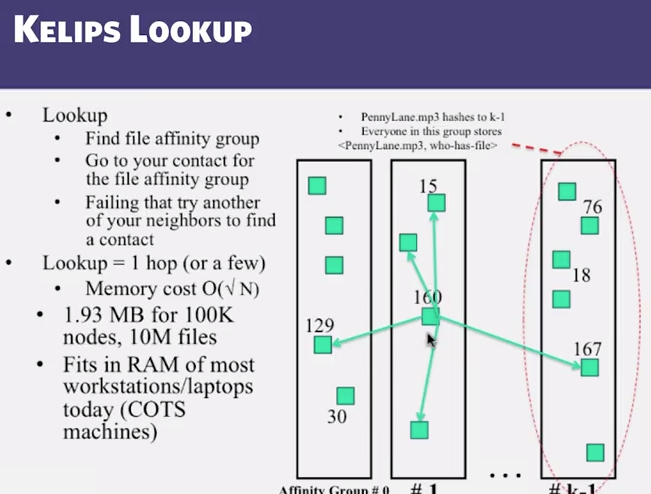
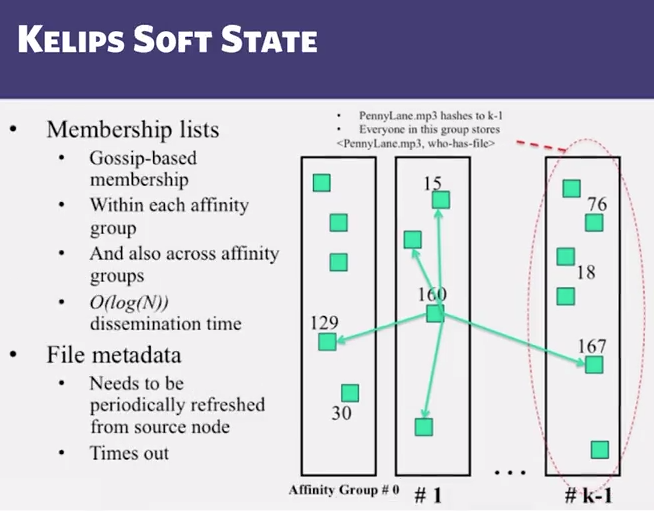
- Chord vs Pastry vs Kelips
- Range of tradeoffs available
- Memory vs lookup cost vs background bandwidth ( to keep neighbors fresh)
- Range of tradeoffs available