CS 410 : Text Information Systems
Goals and Objectives
- Explain the Cranfield evaluation methodology and how it works for evaluating a text retrieval system.
- Explain how to evaluate a set of retrieved documents and how to compute precision, recall, and F1.
- Explain how to evaluate a ranked list of documents.
- Explain how to compute and plot a precision-recall curve.
- Explain how to compute average precision and mean average precision (MAP).
- Explain how to evaluate a ranked list with multi-level relevance judgments.
- Explain how to compute normalized discounted cumulative gain.
- Explain why it is important to perform statistical significance tests.
Guiding Questions
- Why is evaluation so critical for research and application development in text retrieval?
- How does the Cranfield evaluation methodology work?
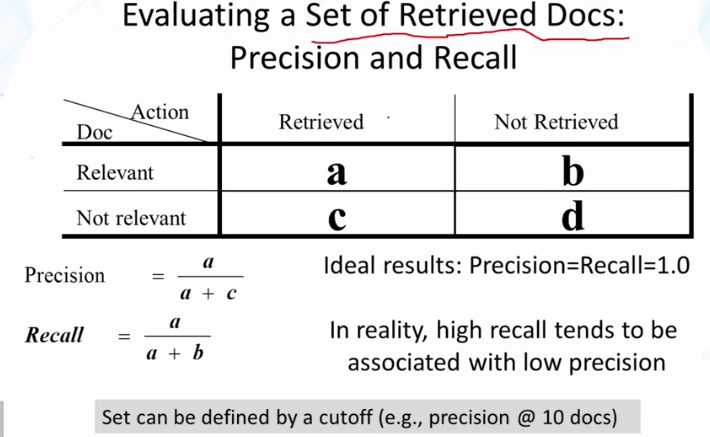
- How do we evaluate a set of retrieved documents?
- How do you compute precision, recall, and F1?
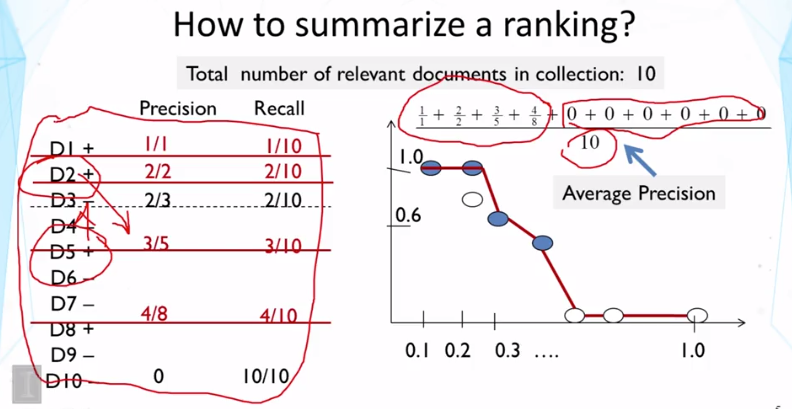
- How do we evaluate a ranked list of search results?
- How do you compute average precision? How do you compute mean average precision (MAP) and geometric mean average precision (gMAP)?
- What is mean reciprocal rank?
- Why is MAP more appropriate than precision at k documents when comparing two retrieval methods?
- Why is precision at k documents more meaningful than average precision from a user’s perspective?
- How can we evaluate a ranked list of search results using multi-level relevance judgments?
- How do you compute normalized discounted cumulative gain (nDCG)?
- Why is normalization necessary in nDCG? Does MAP need a similar normalization? Why is it important to perform statistical significance tests when we compare the retrieval accuracies of two search engine systems?
Additional Readings and Resources
- Mark Sanderson. Test collection based evaluation of information retrieval systems. Foundations and Trends in Information Retrieval 4, 4 (2010), 247-375.
- C. Zhai and S. Massung. Text Data Management and Analysis: A Practical Introduction to Information Retrieval and Text Mining, ACM Book Series, Morgan & Claypool Publishers, 2016. Chapter 9
Key Phrases and Concepts
- Cranfield evaluation methodology
- Precision and recall
- Average precision, mean average precision (MAP), and geometric mean average precision (gMAP)
- Reciprocal rank and mean reciprocal rank
- F-measure
- Normalized discounted cumulative Gain (nDCG)
- Statistical significance test
Video Lecture Notes
3.1 Evaluation of TR Systems
- What to measure?
- Effectiveness/Accuracy (*)
- Efficiency
- Usability
- The Cranfield Evaluation Methodology
- Build reusable test collections & define measures
- Collection can be reused many times to compare different systems
3.2 Evaluation of TR Systems - Basic Measures

3.3 Evaluating Ranked Lists - Part 1
3.4 Evaluating Ranked Lists - Part 2

3.5 Multi-Level Judgements
- so far we’ve been using a binary decision system, relevant or not relevant. How about a non-binary, gradient based system?

- need normalized DCG so we can compare across different topics.
- Normalized Discounted Cumulative Gain (nDCG) main ideas:
- Measure the total utility of the top k documents to a user
- Utility of a lowly ranked document is discounted
- normalized to ensure comparability across queries (note above about topics)
3.6 Practical Issues
- Need ways to measure significance and utility of evaluation techniques
- could use statistical tests, beyond just averaging
- need to account for variance
- high variance = low reliability
- Use many queries before jumping into conclusions
- Pooling: avoid judging all documents
- if we can’t afford judging all the documents in teh collection, which subset should we judge?
- Pooling strategy
- choose a diverse set of rankign methods (TR systems)
- Have each to return top-K documents
- Combine all the top-K sets to form a pool for human assessors to judge
- Other (unjudged) documents are usually assumed to be non-relevant (though they don’t have to)
- okay for comparing system that contributed to the pool, but problematic for evaluating new systems.

cs 425 : Distributed Systems
Goals
- Analyze various gossip/epidemic protocols.
- Design and analyze various distributed membership protocols.
- Know what grid computing is.
Key Concepts
- Failure detectors
- Membership protocols
- Gossip/epidemic protocols
- Grid computing
Guiding Questions
- Why are gossip and epidemic protocols fast and reliable?
- What is the most efficient way for cloud computing systems to detect failures of servers?
- How is grid computing related to cloud computing?
Readings
- Gossip-style FD
- Gossip-Style failure detection will have these properties:
- the probability that a member is falsely reported as having failed is inde-
pendent of the number of processes. - the algorithm is resilient against both message loss (or rather, message
delivery timing failures) and process failures, in that a small percentage of
lost (or late) messages or small percentage of failed members does not lead
to false detections. - if local clock drift is negligible, the algorithm detects all failures or un-
reachabilities accurately with known probability of mistake. - the algorithm scales in detection time, in that the detection time increases
O(n log n) with the number of processes. - the algorithm scales in network load, in that the required bandwidth goes
up at most linearly with the number of processes. For large networks, the
bandwidth used in the subnets is approximately constant.
- the probability that a member is falsely reported as having failed is inde-
- Our protocol gossips to figure out whom else is still gossiping.
- Gossip-Style failure detection will have these properties:
- SWIM
- Membership protocols have been difficult to scale in groups with beyond a few dozen processes [11, 16], thus affecting the performance of applications using them. As reported in [16], the main symptoms of bad performance at these group sizes is an increase in either the rate of false failure detections of processes, or the time to detect a failure.[12]
- Our system, called SWIM, provides a membership substrate that:
- imposes a constant message load per group member;
- detects a process failure in an (expected) constant time
at some non-faulty process in the group; - provides a deterministic bound (as a function of group
size) on the local time that a non-faulty process takes to de-
tect failure of another process; - propagates membership updates, including informa-
tion about failures, in infection-style (also gossip-style or
epidemic-style [2, 8]); the dissemination latency in the
group grows slowly (logarithmically) with the number of
members; - provides a mechanism to reduce the rate of false pos-
itives by “suspecting” a process before “declaring” it as
failed within the group.
- Properties of previous distributed failure detector protocols:
- Strong Completeness: crash-failure of any group mem-
ber is detected by all non-faulty members [6]); - Speed of failure detection: the time interval between a
member failure and its detection by some non-faulty group
member; - Accuracy: the rate of false positives of failure detection;
- Network Message Load, in bytes per second generated
by the protocol.
- Strong Completeness: crash-failure of any group mem-
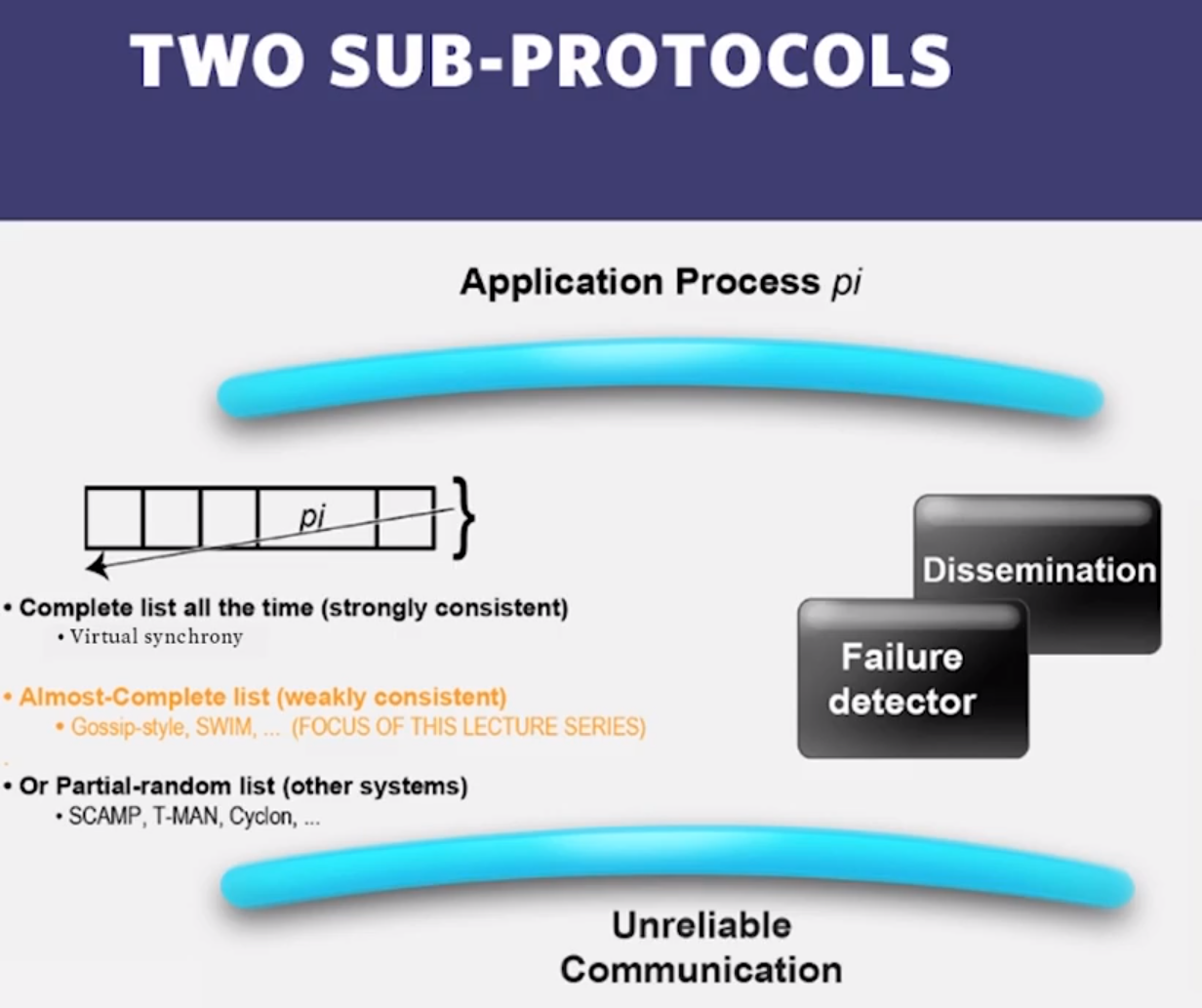
- SWIM has two basic components:
- a Failure Detector Component, that detects failures of
members, and - a Dissemination Component, that disseminates informa-
tion about members that have recently either joined or left
the group, or failed.
- a Failure Detector Component, that detects failures of
- and these advanced components:
- Infection-Style Dissemination Component
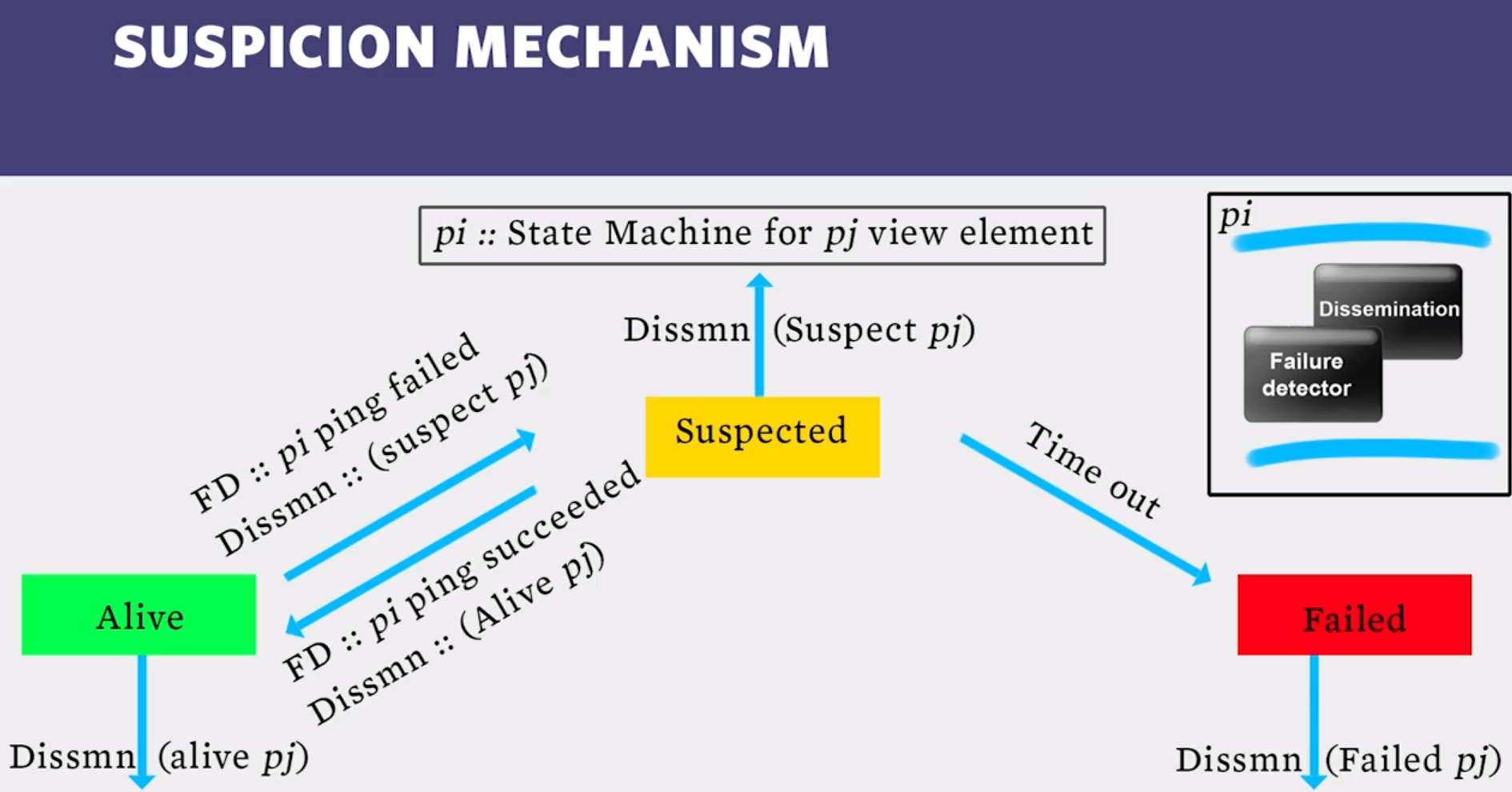
- Suspicion Mechanism: Reducing the Frequency of False Positives
- Round-Robin Probe Target Selection: Providing Time-Bounded Strong Completeness
Video Lecture Notes
Gossip
1.1 : Multicast Problem
- Centralized Multicast, simplest
- UDP/TCP packets
- A single, center protocol handler
- Faulty due to single center protocol handler, if it fails halfway through process then only half of receivers will be updated.
- High overhead which leads to large latency
- Tree-Based
- eg, IPmulticast, SRM, RMTP, TRAM, TMTP
- Pros:
- if tree is balanced, then depth is log(n). As a result, the complexity of a message reaching a node is O(logn).
- If children constant at each node, then message propagation is constant
- Con:
- setup and maintain tree
- if a high node fails, many descendents will be disconnected

- Which of the following is FALSE about a NAK in a tree-based multicast protocol?
- It is used to send negative acknowledgments to a sender or designated receiver.
- It may result in some of the multicast messages being retransmitted.
- NAKs may cause message implosion.
- (FALSE) NAKs cannot be used if IP multicast in the underlying network is used.
1.2 : The Gossip Protocol
- The gossip-based protocol described so far (select all correct answers):
- (TRUE) Is executed periodically at each node
- Receives only one copy of each multicast message at each node
- Can turn an infected node into an uninfected node
- (TRUE) Can turn an uninfected node into an infected node

1.3 : Gossip Analysis (Important)
- Properties of Gossip push protocol:
- lightweight, even in large groups
- Spreads a multicast quickly
- highly fault-tolerant
- We’re presented the epidemiology differential equations, which we’re asked to solve on our own. Below is a video I made to walk through the solution:
- Pull is faster than push.
- Push-Pull paradigm could involve push to quickly start up the cascade, and then use pull to facilitate propagation of cascade.
- second half of pull gossip finishes in time O(loglogn)
1.4 : Gossip Implementations
Membership
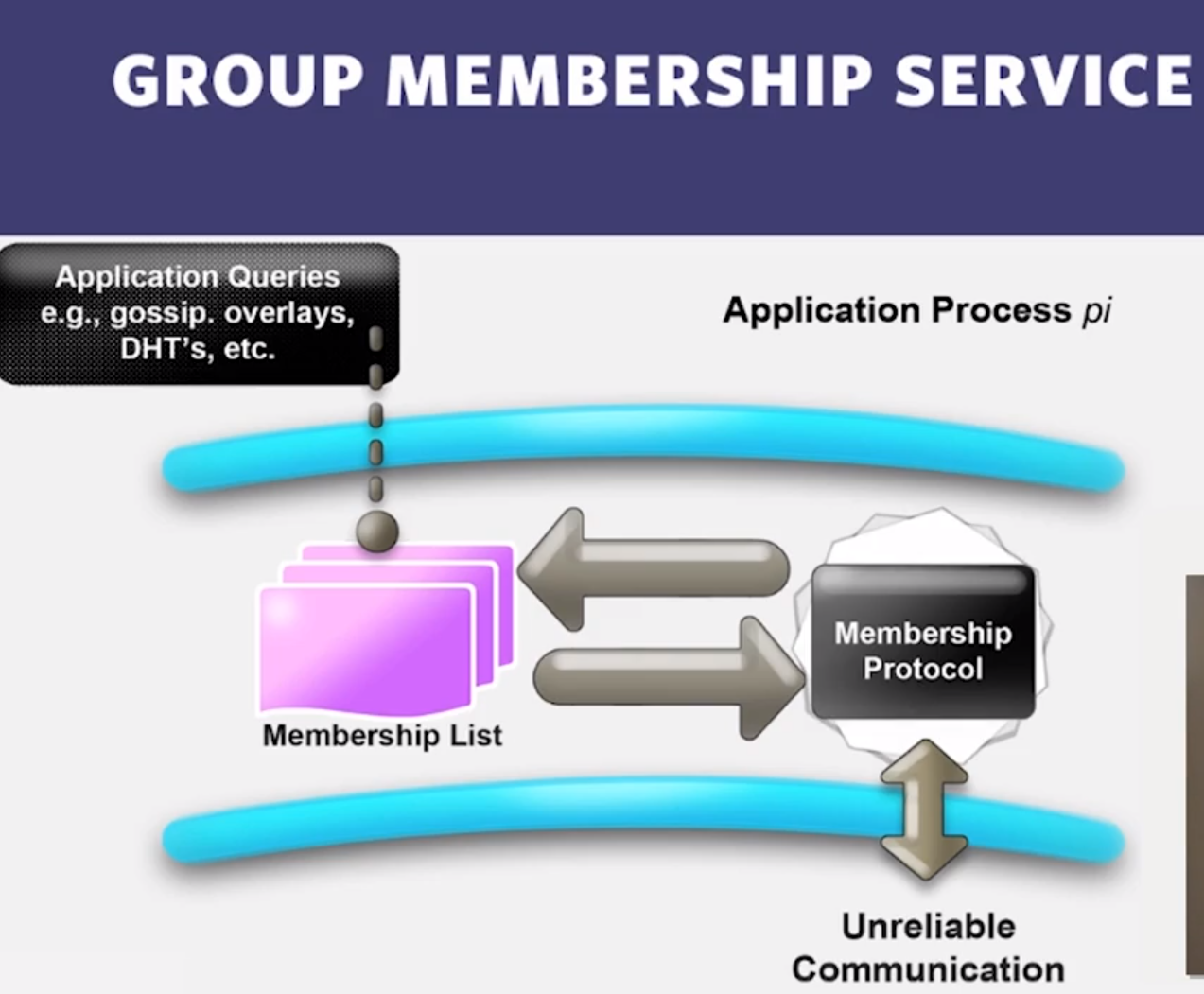
2.1 : What is Group Membership List?
- Failures are the norm in datacenters, need to design failure detectors
- Crash-stop/Fail-stop process failures (processes do not recover!)
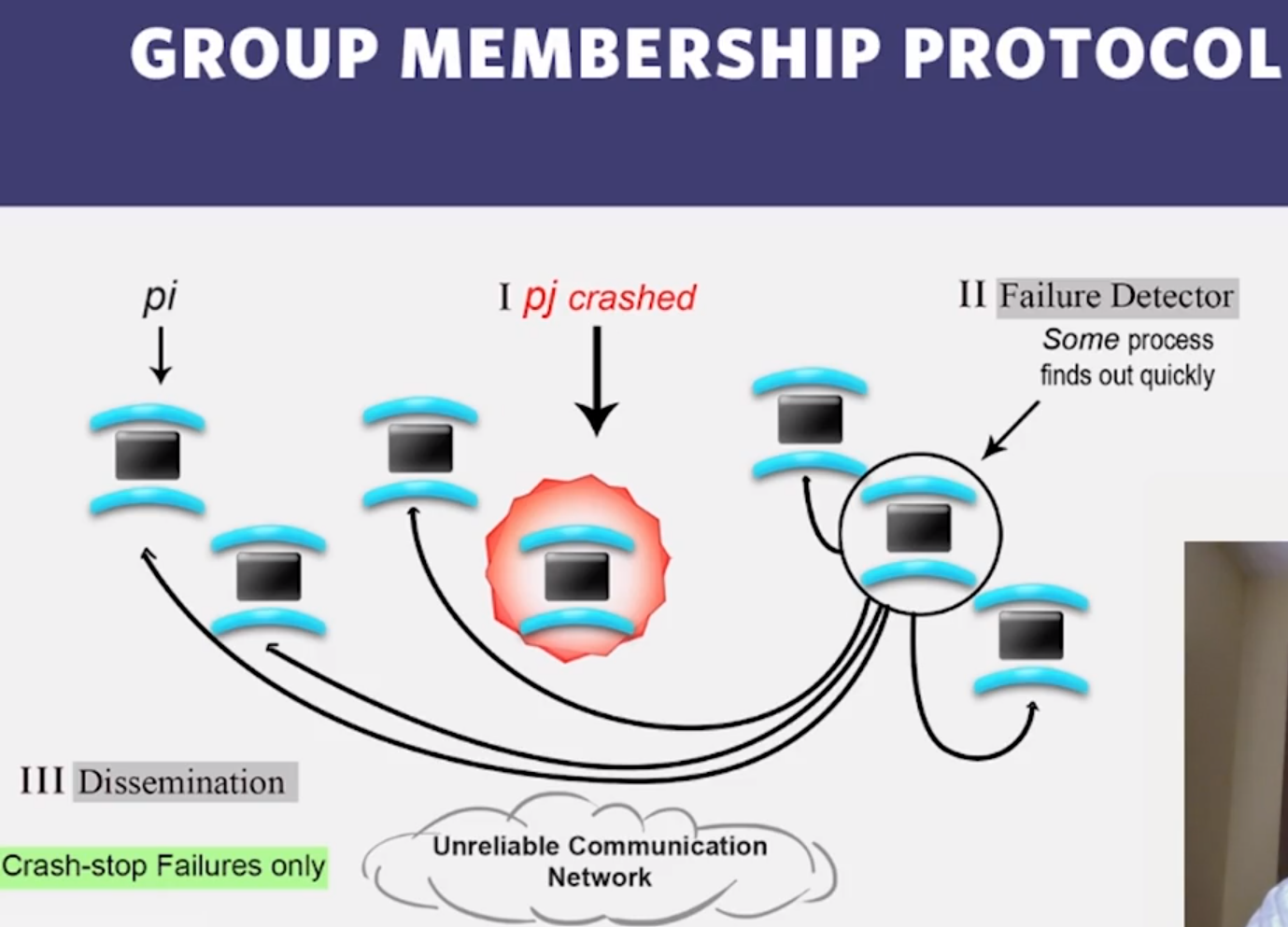
2.2 : Failure Detectors
- detectors cannot be both 100% complete and 100% accurate.
- if you can do both, then you’ve solved the “consensus problem”: group deciding/agreeing on the value of something in a lossy network (impossible, more later)
- in practice, always 100% complete, 90-99% accurate.
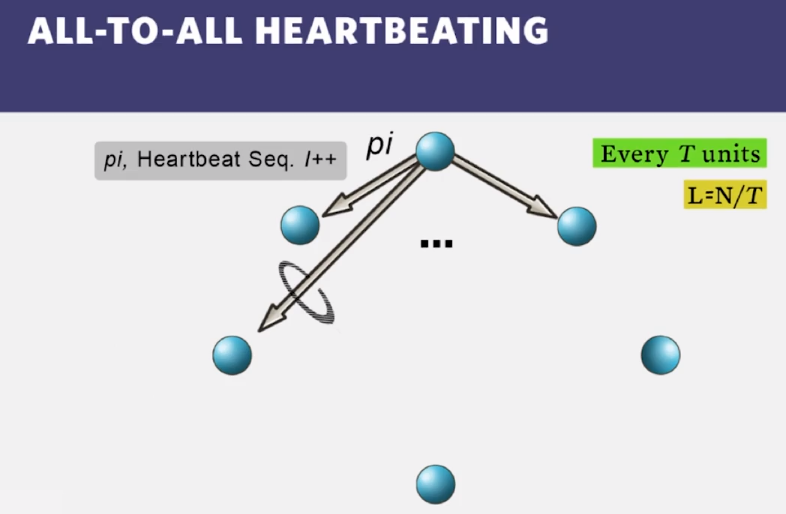
- Centralized Heartbeating
- ring heartbeating
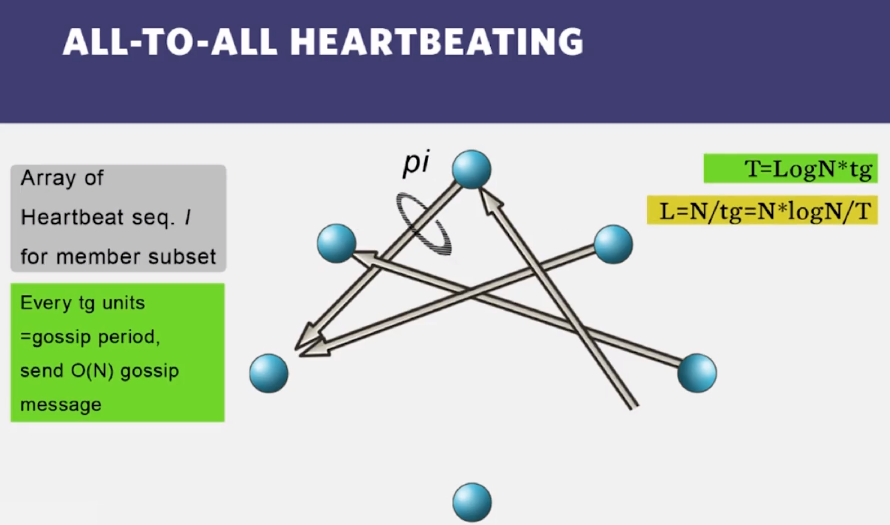
- all-to-all heartbeating (best)
- if one node is slow, it may mark many nodes as faulty, thus causing large false positives…how to fix?
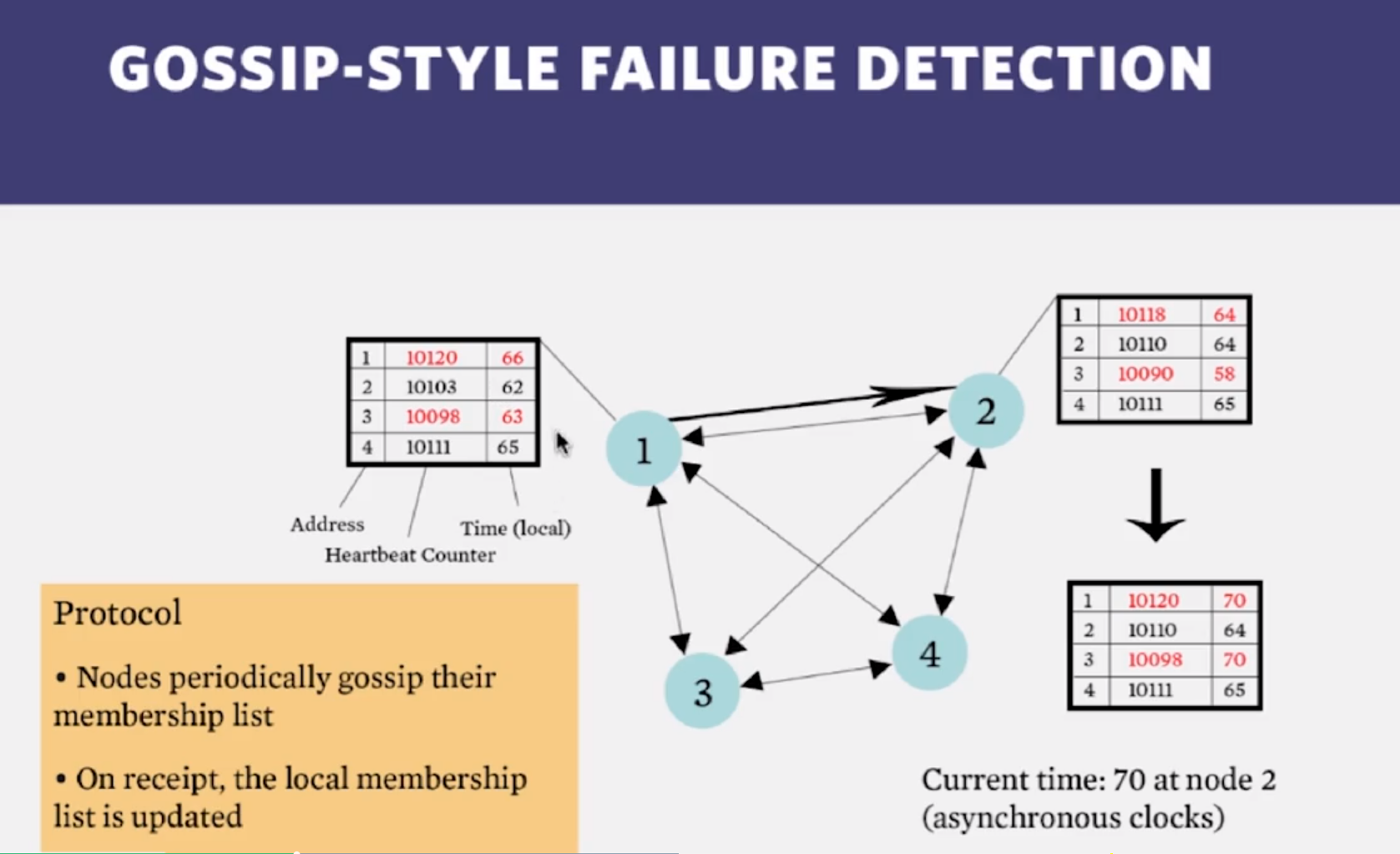
2.3 : Gossip-Style Membership
- In gossip-style failure detection, why should an entry not be deleted right after it’s detected as failed?
- Because other processes may not have deleted that entry and it may be added back (the process may stay in the records despite being dead)

2.4 : Which is the best failure detector?

Next slide should say “All-to-all gossip heartbeating”


2.5 : Another probabilistic Failure Detector
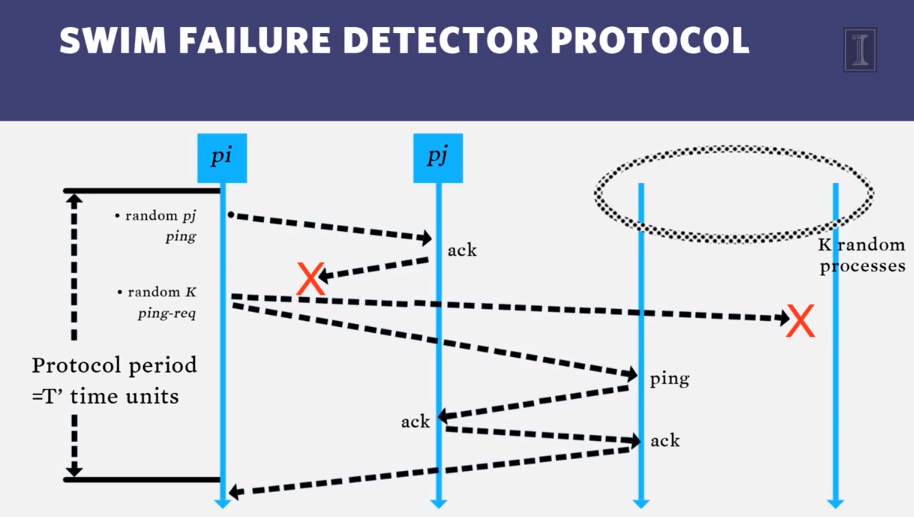
- SWIM allows a process pj extra chances to respond to pi through time and space.
- It allows it more time to respond, and permits direct and indirect (through other random processes) paths to relay a response.




2.6 : Dissemination and suspicion
- In a system with N processes using the SWIM failure detector, given enough network bandwidth, how long does it take for a failure, after it is detected at one process, to disseminate through the group?
- O(logn) (why?)



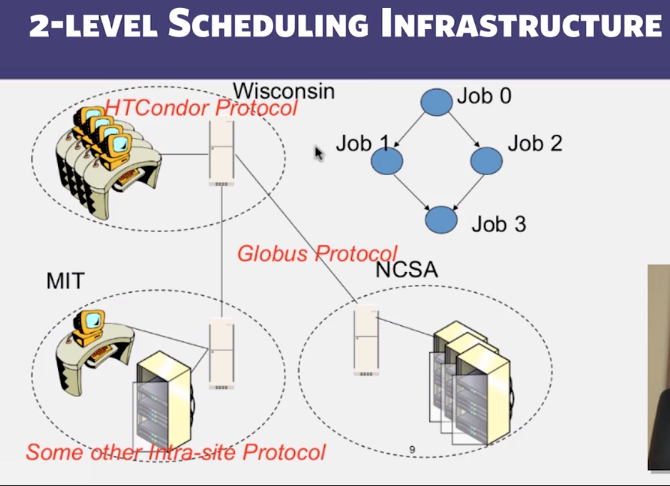
3.1 : Grid Applications
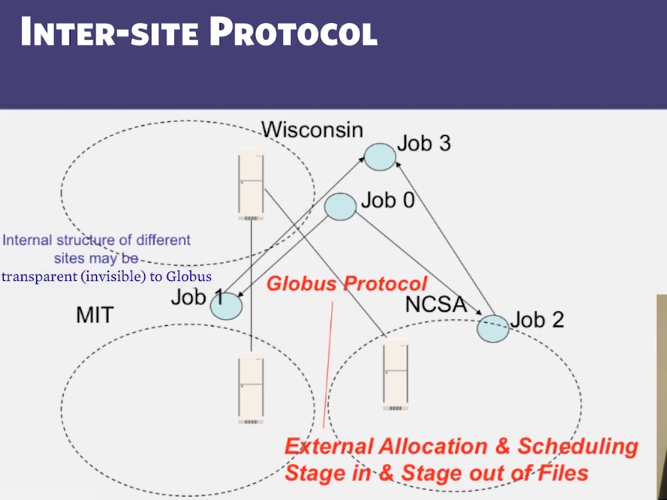
- Question: how do we schedule and distribute a list of jobs across multiple different machines?
3.2 : Scheduling Problem
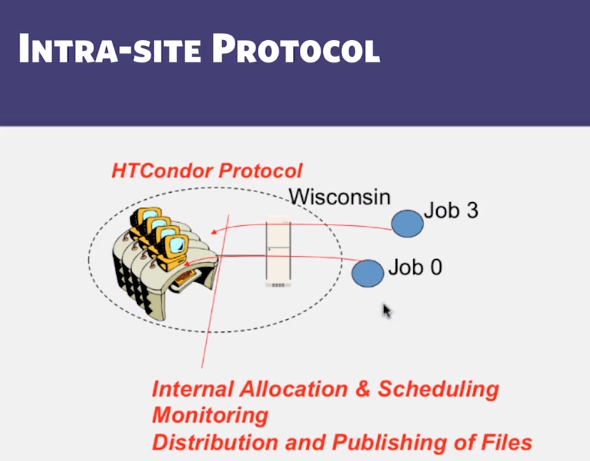
- Which of the following are typically NOT the responsibility of an inter-site protocol like Globus, but instead the responsibility of an intra-site protocol like HTCondor (select multiple answers)?
- Deciding which tasks run on which machines (Correct)
- Monitoring of workstations running tasks (Correct)
- Wide-area file transfer
- Allocating jobs to sites




CS 427 : Software Engineering
Goals and Objectives
- Explain key practices in path-driven methodologies
- Explain key practices in agile methodologies
- Choose appropriate processes in the given application context
Video Lecture Notes
2.1 : Process Overview
- Activity groups in IEEE 1074
- Project Management
- Project initiation
- Project Planning
- Project Monitoring and control
- Pre-development
- Concept exploration
- system allocation
- software importation
- Development
- Software requirements
- Define and develop software requirements
- Define interface requirements
- Prioritize and integrate software requirements
- Design
- Implementation
- Software requirements
- Post-Development
- Installation
- Operation and support
- Maintenance
- Retirement
- Support
- Evaluation
- Software configuration management
- Documentation development
- Training
- Project Management
2.2 : Plan Driven Process
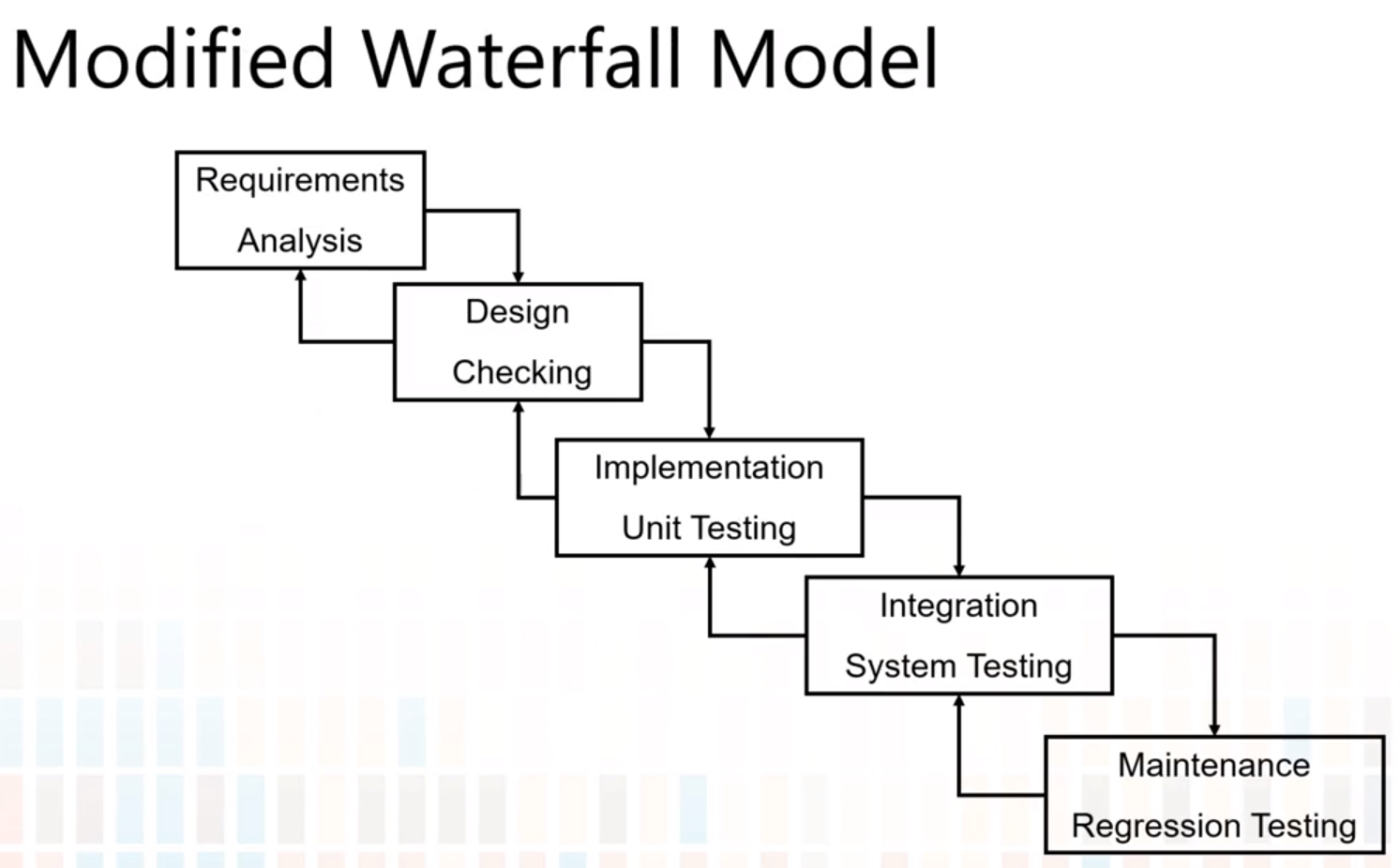
- Waterfall Process
- Requirements
- Design
- Implementation
- Integration
- Testing
- Maintenance

2.3 : Agile Process
- while all of these are important, we prefer:
- Individuals & interactions > processes and tools
- Working Software > comprehensive documentation (use better coding to convey meaning, easier/faster to maintain than code with tons of documentation)
- Customer collaboration > Contract negotiation (let engineers collaborate with customers)
- Responding to change > following a plan (allow audibles)
- XP:
- Planning game for requirements
- Test-driven development for design and testing
- Refactoring for design
- Pair programming for development
- Continuous integration

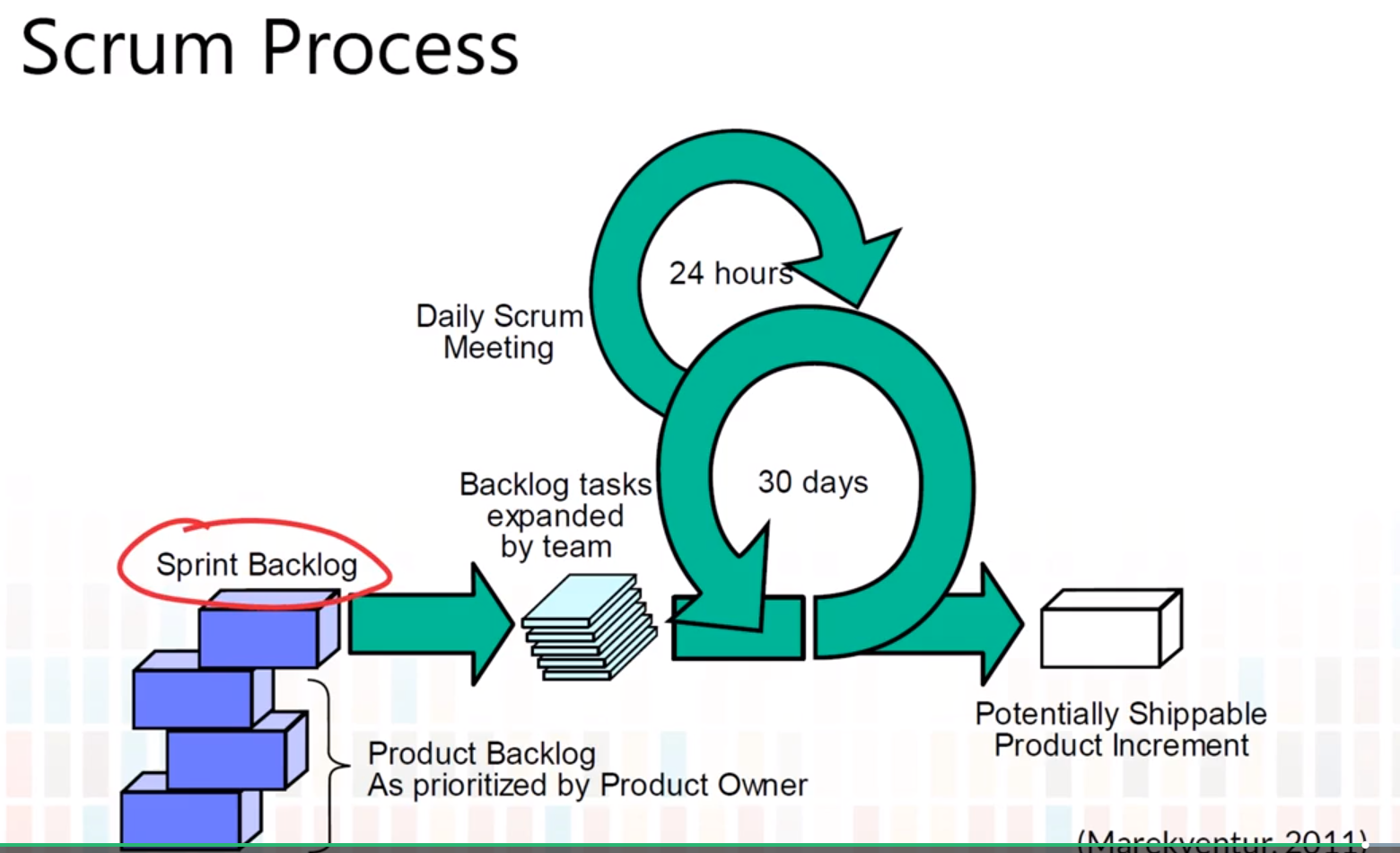
- Scrum is needed when customer expectations are evolving or uncertain.
- Scrum should not be chosen if there is high inter-dependencies that make it difficult to split product into shippable increments.
2.4 Process Choosing
- Five critical factors to help choose a strategy:
- Size (number of people on team)
- Criticality (what are the costs upon failures?)
- Dynamism (how often requirements of tech change)
- Personnel (skill of team members)
- Culture (team members’ preferences and habits)

2.5 Project Planning
- Story Points are relative measures of how much time/effort tasks will take to complete.
2.6 Scheduling
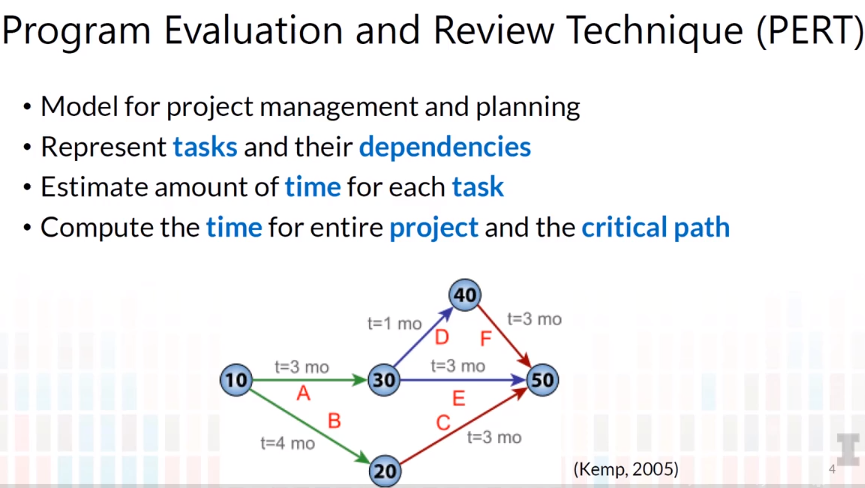
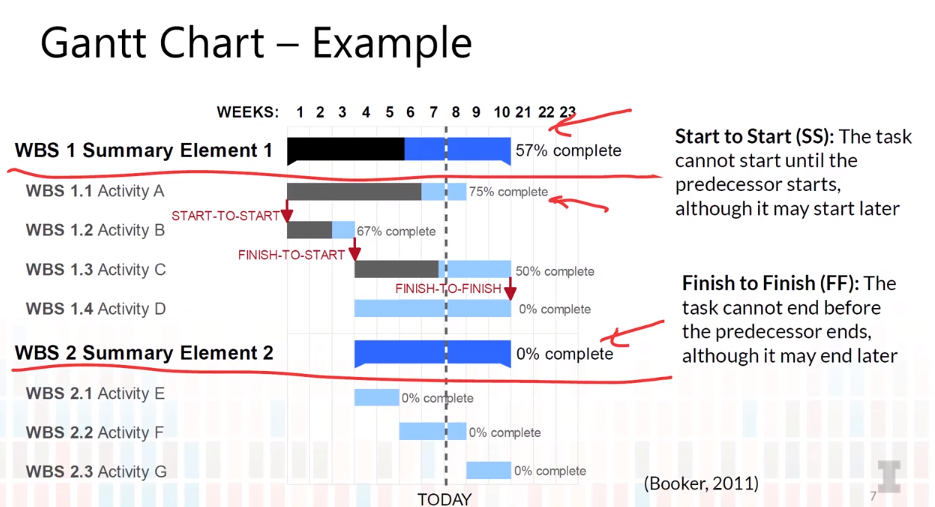
2.7 Risk Management
- Don’t be afraid of bringing up issues/risks, refraining from doing so can do harm to all stakeholders in the project
- Be proactive!