- CS 410 Text Information Systems
- Goals and Objectives
- Guiding Questions
- Additional Readings and Resources
- Key Phrases and Concepts
- Video Lecture Notes
- 7-1 Overview Text Mining and Analytics Part 1
- 7-2 Overview Text Mining and Analytics Part 2
- 7-3 Natural Language Content Analysis Part 1
- 7-4 Natural Language Content Analysis Part 2
- 7-5 Text Representation Part 1
- 7-6 Text Representation Part 2
- 7-7 Word Association Mining and Analysis
- 7-8 Paradigmatic Relation Discovery Part 1
- 7-9 Paradigmatic Relation Discvery Part 2
- CS 425 Distributed Systems
- CS 427 Software Engineering
CS 410 Text Information Systems
Goals and Objectives
Explain some basic concepts in natural language processing.
Explain different ways to represent text data.
Explain the two basic types of word associations and how to mine paradigmatic relations from text data.
Guiding Questions
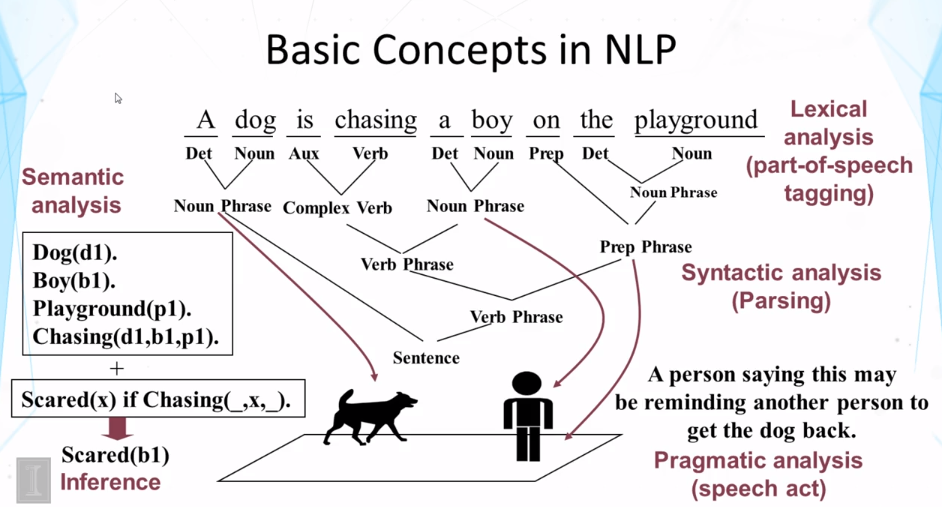
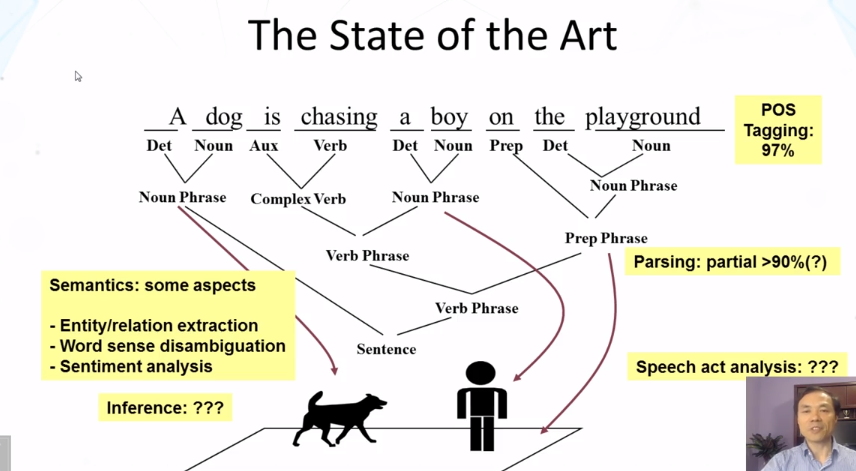
What does a computer have to do in order to understand a natural language sentence?
What is ambiguity?
Why is natural language processing (NLP) difficult for computers?
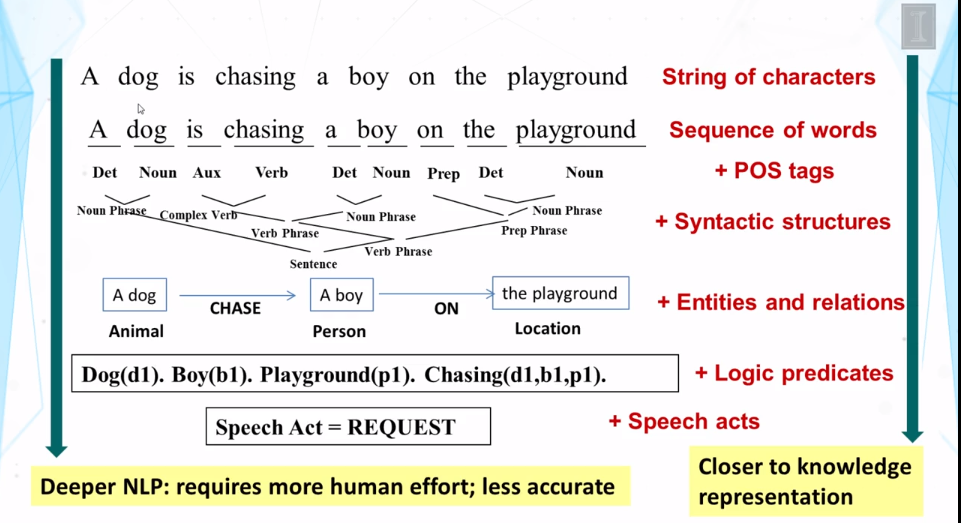
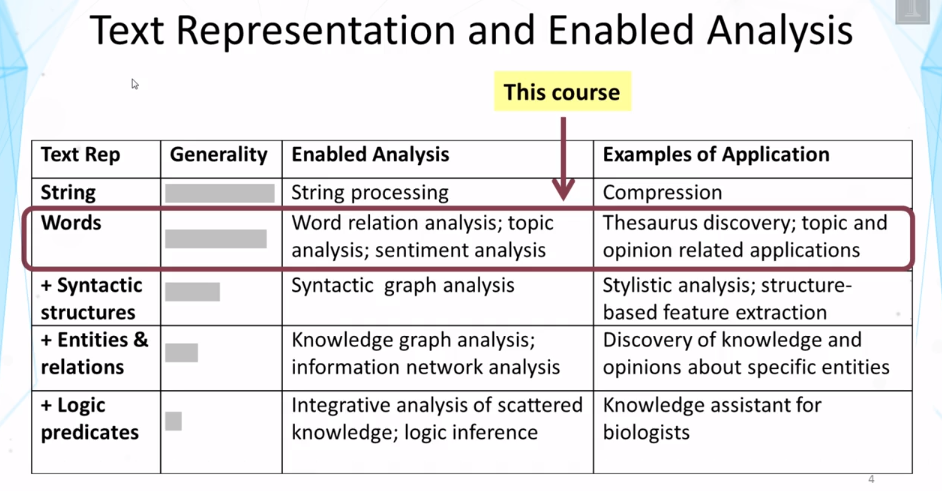
What is bag-of-words representation?
Why is this word-based representation more robust than representations derived from syntactic and semantic analysis of text?
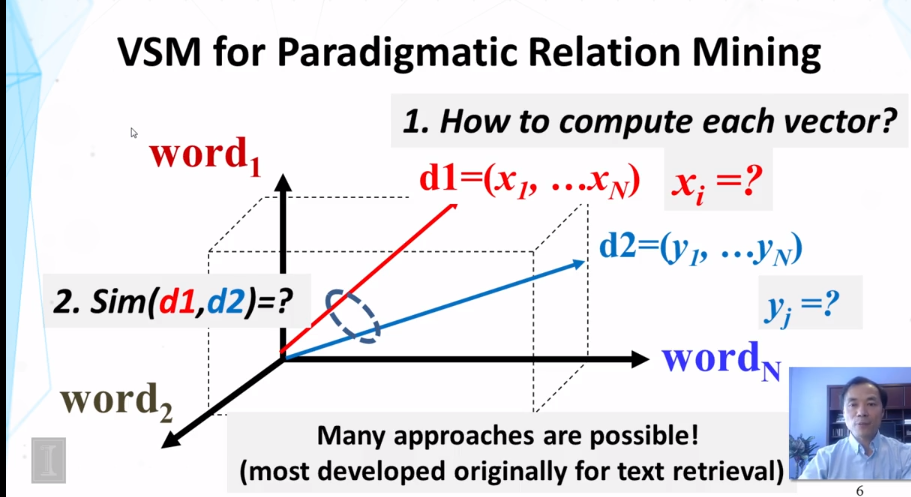
What is a paradigmatic relation?
What is a syntagmatic relation?
What is the general idea for discovering paradigmatic relations from text?
What is the general idea for discovering syntagmatic relations from text?
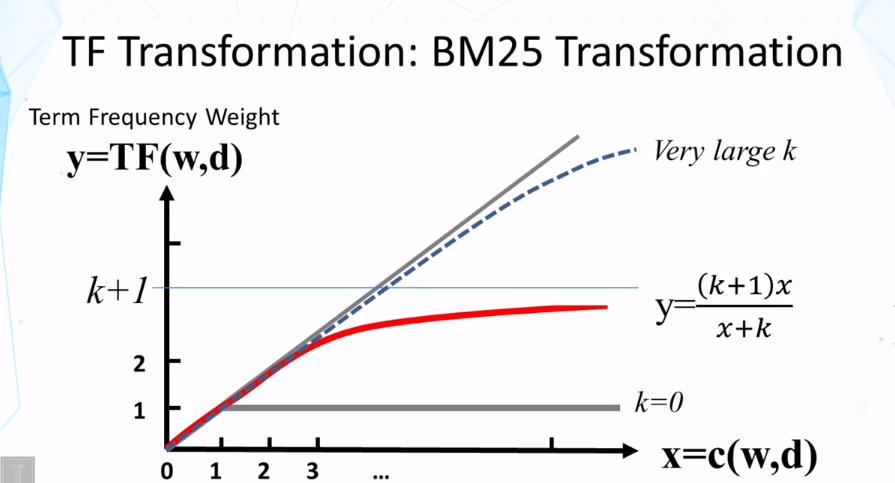
Why do we want to do Term Frequency Transformation when computing similarity of context?
How does BM25 Term Frequency transformation work?
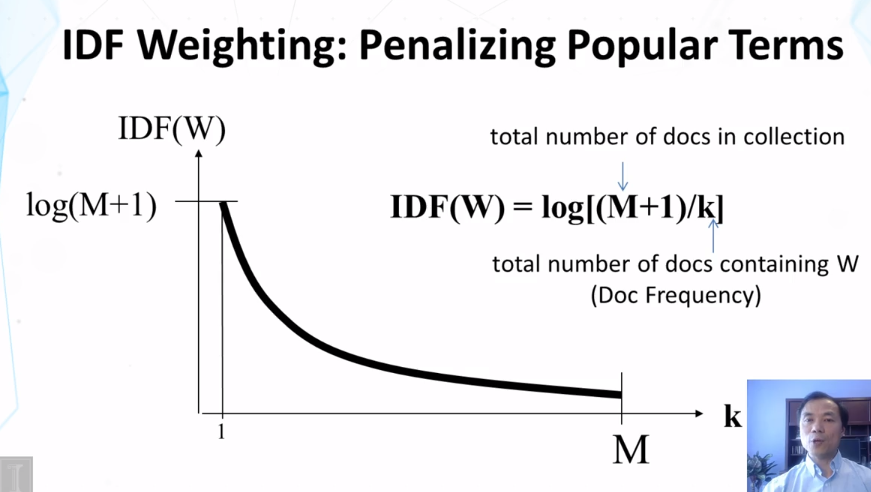
Why do we want to do Inverse Document Frequency (IDF) weighting when computing similarity of context?
Additional Readings and Resources
C. Zhai and S. Massung, Text Data Management and Analysis: A Practical Introduction to Information Retrieval and Text Mining. ACM and Morgan & Claypool Publishers, 2016. Chapters 1-4, Chapter 13.
Chris Manning and Hinrich Schütze, Foundations of Statistical Natural Language Processing. MIT Press. Cambridge, MA: May 1999. Chapter 5 on collocations.
Chengxiang Zhai, Exploiting context to identify lexical atoms: A statistical view of linguistic context. Proceedings of the International and Interdisciplinary Conference on Modelling and Using Context (CONTEXT-97), Rio de Janeiro, Brazil, Feb. 4-6, 1997, pp. 119-129.
Shan Jiang and ChengXiang Zhai, Random walks on adjacency graphs for mining lexical relations from big text data. Proceedings of IEEE BigData Conference 2014, pp. 549-554.
Key Phrases and Concepts
Part of speech tagging
Syntactic analysis
Semantic analysis
Ambiguity
Text representation, especially bag-of-words representation
Context of a word; context similarity
Paradigmatic relation
Syntagmatic relation
Video Lecture Notes
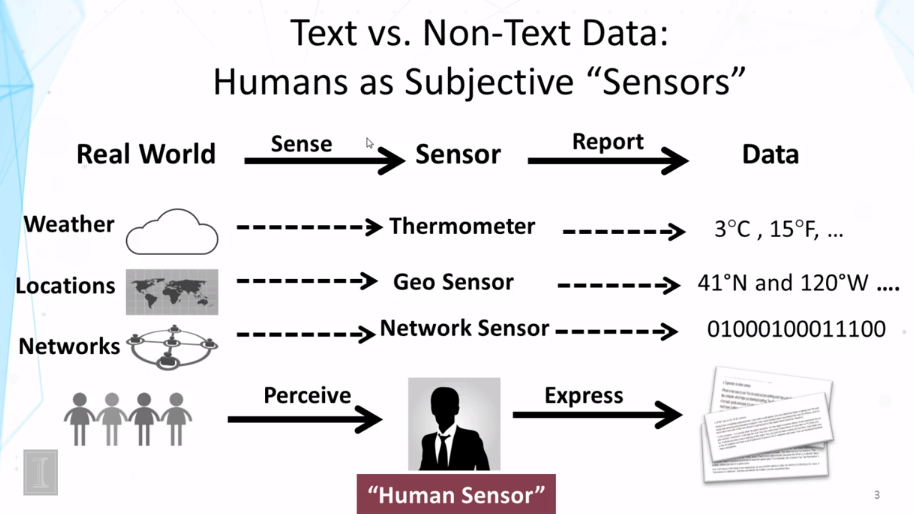
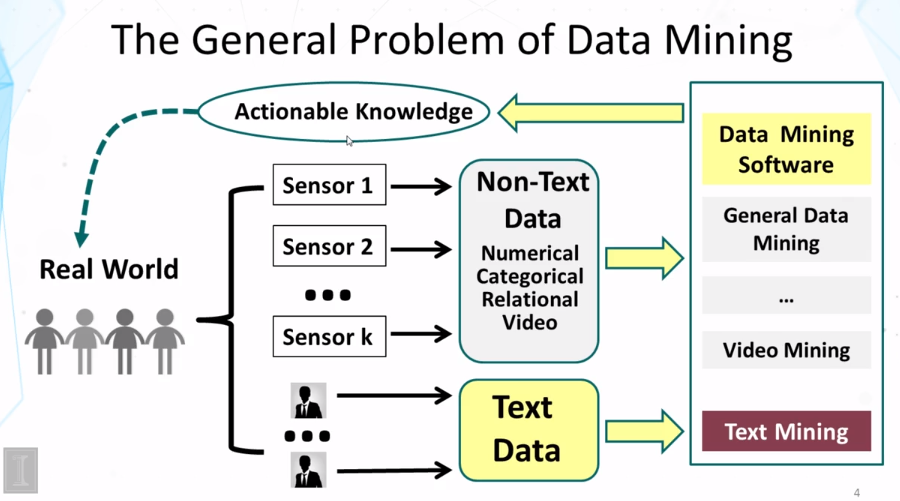
7-1 Overview Text Mining and Analytics Part 1

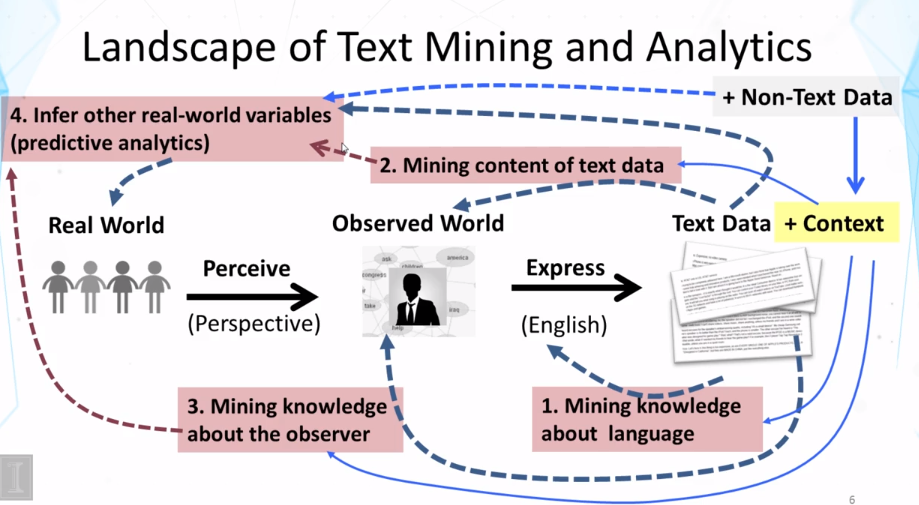
7-2 Overview Text Mining and Analytics Part 2
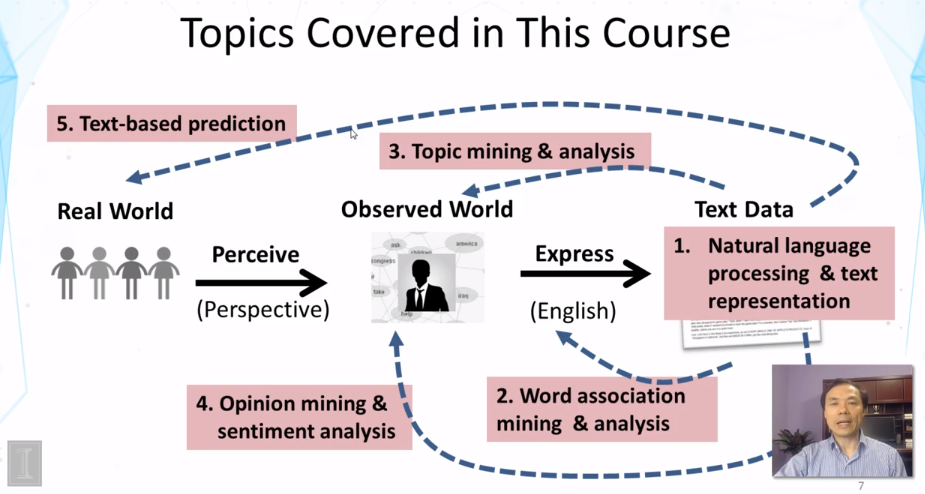
7-3 Natural Language Content Analysis Part 1


7-4 Natural Language Content Analysis Part 2


7-5 Text Representation Part 1
7-6 Text Representation Part 2

7-7 Word Association Mining and Analysis



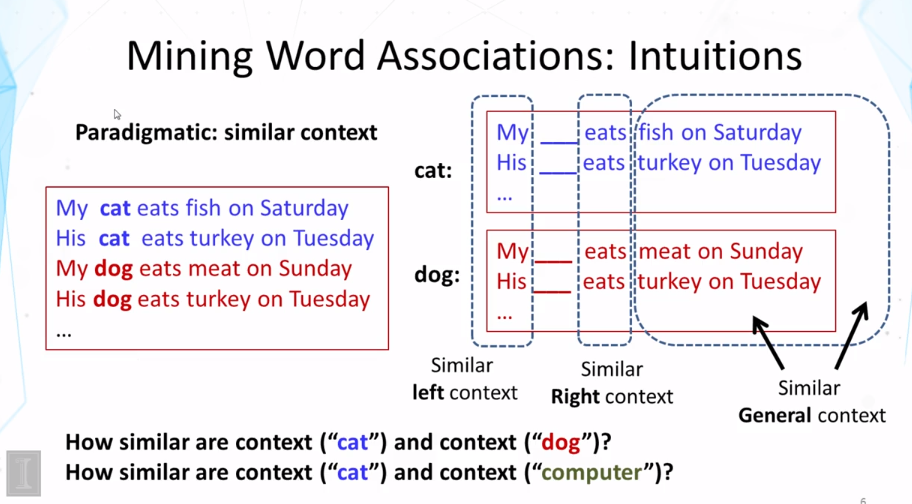
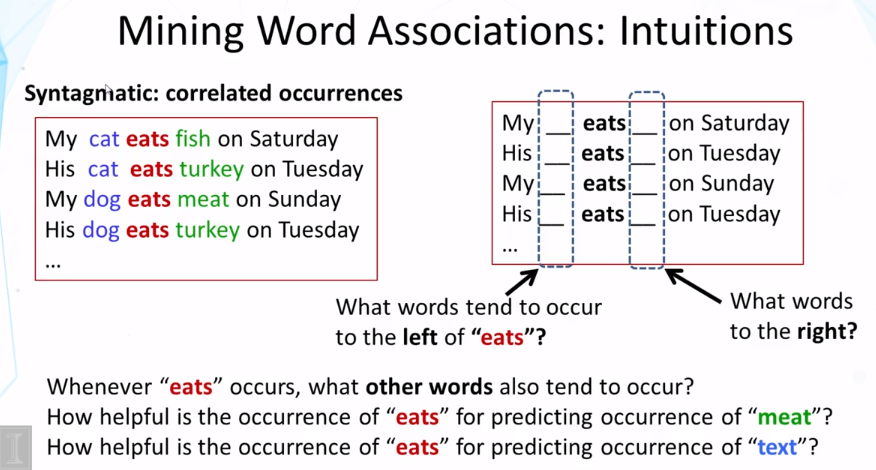




7-8 Paradigmatic Relation Discovery Part 1
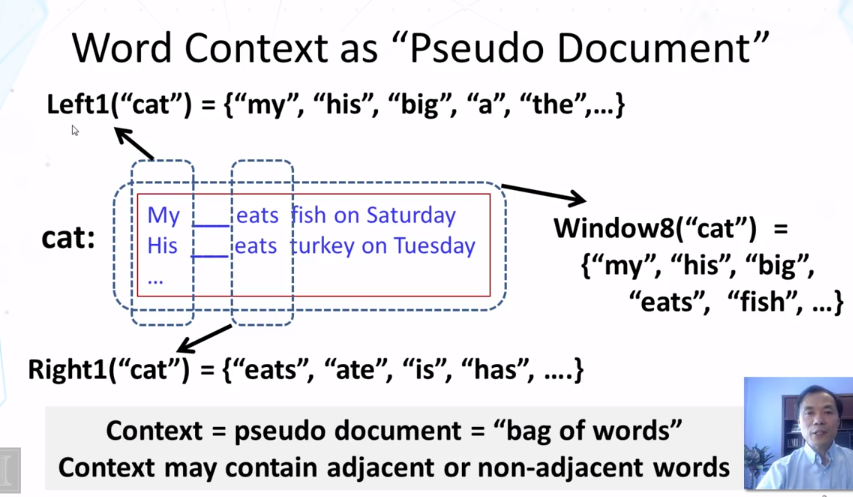

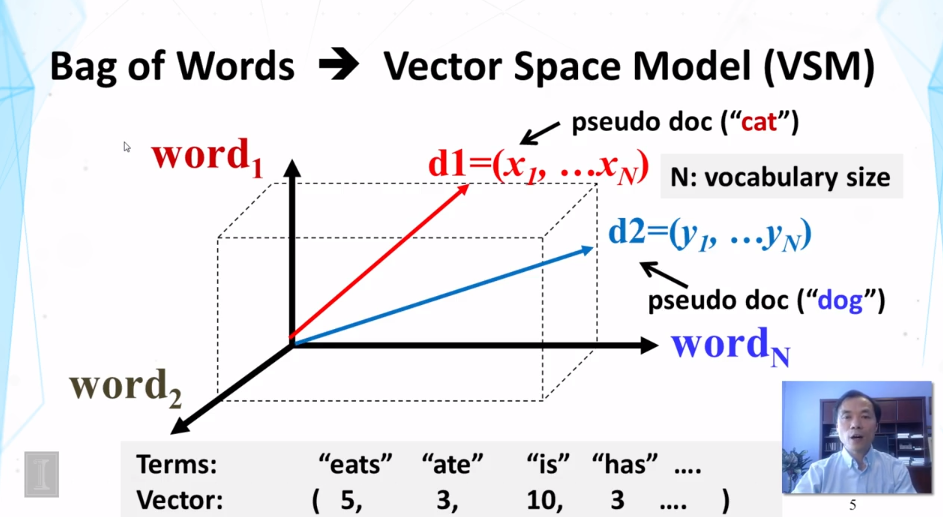


7-9 Paradigmatic Relation Discvery Part 2




CS 425 Distributed Systems
No content this week, midterm.
CS 427 Software Engineering
No content this week, work on mp1.