CS 410 : Text Information Systems
Guiding Questions
- What are some different ways to place a document as a vector in the vector space?
- What is term frequency (TF)?
- What is TF transformation?
- What is document frequency (DF)?
- What is inverse document frequency (IDF)?
- What is TF-IDF weighting?
- Why do we need to penalize long documents in text retrieval?
- What is pivoted document length normalization?
- What are the main ideas behind the retrieval function BM25?
- What is the typical architecture of a text retrieval system?
- What is an inverted index?
- Why is it desirable to compress an inverted index?
- How can we create an inverted index when the collection of documents does not fit into the memory?
- How can we leverage an inverted index to score documents quickly?
Key Phrases and Concepts
- Term frequency (TF)
- Document frequency (DF) and inverse document frequency (IDF)
- TF transformation
- Pivoted length normalization
- sBM25
- Inverted index and postings
- sBinary coding, unary coding, gamma-coding, and d-gap
- Zipf’s law
Video Lecture Notes
2.1 Vector Space Model - Improved Instantiation
Slide 2 : Two problems with Simplest VSM
- Matching a keyword more times deserves more credit towards a document
- Matching some keywords may be more important than other keywords (not all keywords are created equal).
Slide 3 : Improved Vector Placement: Term Frequency (how many times it occurs in document) Vector
- Use counts of each word in query/document instead of 1’s and 0’s
- Will solve term frequency problem, but will not fix hierarchy of keywords
Slide 6 : Keyword Hierarchy
- use Inverse Document Frequency of word to help differentiate between low and high priority words
- IDF(W) = log((M+1)/k), M = Total number of docs in collection, k = total number of docs containing W (words that appear in many documents have lower priority than words that occur in only a relatively small number.
Slide 12 : VSM with TF-IDF effective?
- works well for some cases, but introduces new problems in other situations
- Still have problems with words that have high frequency in a document but missing other important keywords.
2.2 : TF Transformation
Slide 5 : TF Transformation: c(w, d) -> TF(w,d)
- A way to lessen impact of c(w,d) of unimportant word when using TF-IDF weighting.
- Best developed so far is BM25: y = (k+1)x/(x+k) (upper bound of k+1)
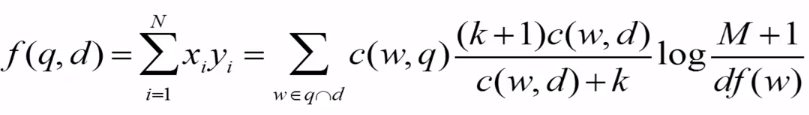
2.3 : Doc Length Normalization
- Length Normalization can be a double edged sword, need to be careful to heavily penalize those with more words and lightly penalize those with more relevant content.
- Have length normalizer depend on document length and average document length
-
normalizer = 1 - b + b( d )/avdl where b is between 0 and 1. - State of the Art VSM Ranking Functions:

Slide 7 : Further improvement of VSM?
-
Improved instantiation of dimension?
-
Improved instantiation of similarity function?
Slide 8 : Further improvements of BM25
- BM25F (combine frequency counts of terms in all fields and then apply BM25 (instead of the other way)
- BM25+ (add small constant to TF)
2.4 : Implementation of TR (Text Retrieval) Systems
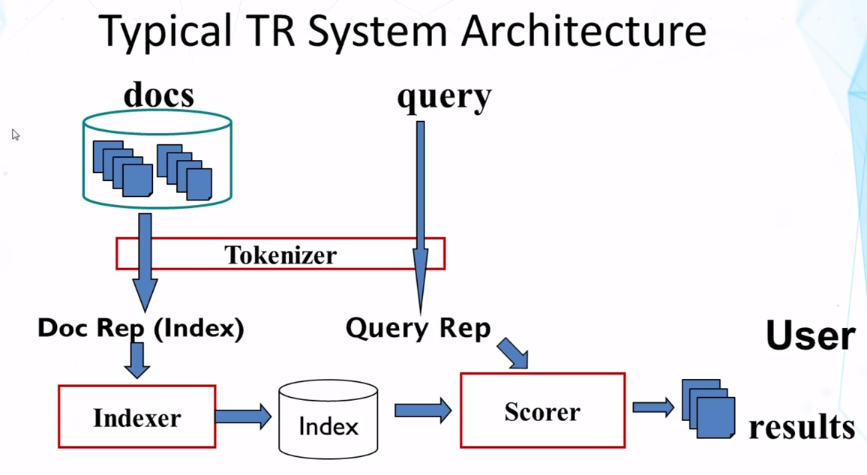
rationale behind why inverted index is so fast compared to just sequential search through a document:
- Two datastructures that can be used: Dictionary or Posting (inverted index)
2.5 : System Implementation - Inverted Index Construction
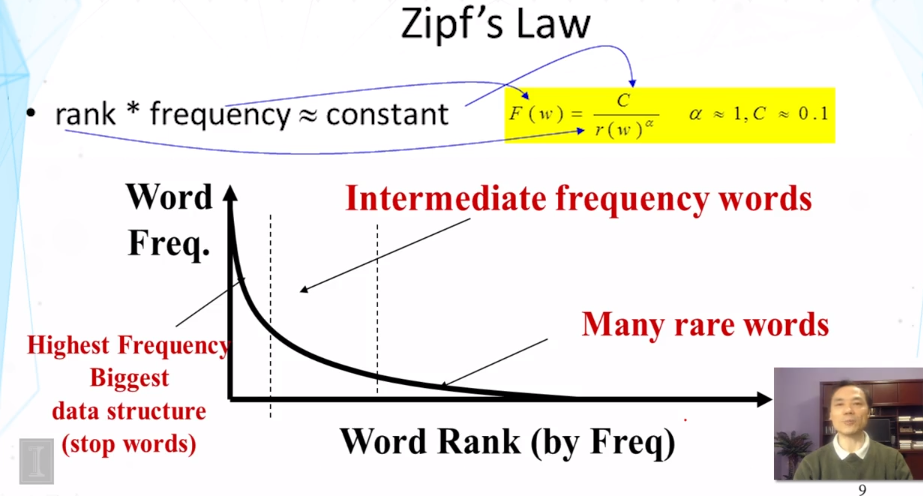
- Most of this lecture spoke about different compression procedures:
- unary
- γ-encoding
- δ-encoding
- The methods in the links above appear different to what Cheng describes in his slides:

2.6 : System Implementation - Fast Search
CS 425 : Distributed Systems
Goals
- Know the key differences between cloud computing and previous generations of distributed systems.
- Design MapReduce programs for a variety of problems.
- Know how Hadoop schedules jobs.
Key Concepts
- Clouds
- MapReduce
- Hadoop YARN
- Sumeet Singh Interview
Guiding Questions
- Why is cloud computing popular today?
- What is different in cloud computing compared to previous generations of distributed systems?
- How does one program in MapReduce?
- How does the MapReduce system schedule jobs?
Video Lecture Notes
1.1 : Why Clouds?
- Many different Cloud services (AWS, Google App Engine, etc)
Slide 5 : Two categories of clouds
- Private Clouds (within company only)
- Public Clouds for customers
- Amazon S3 (Simple Storage Service): store data
- Amazon EC2 (Elastic Compute Cloud): upload and run OS images, pay per hour
- Google App Engine/ Compute Engine
Slide 6 : Customers Save Time and Money
1.2 : What is a Cloud?
Slide 1 : What is it?
- cluster!
- supercomputer!
- datastore!
- superman!
- none or all of the above!
- Course Definition: Cloud = Lots of Storage + compute cycles nearby
Slide 2 : What is it continued
- Single or multiple geographical data centers
Slide 3 : Sample Cloud topology
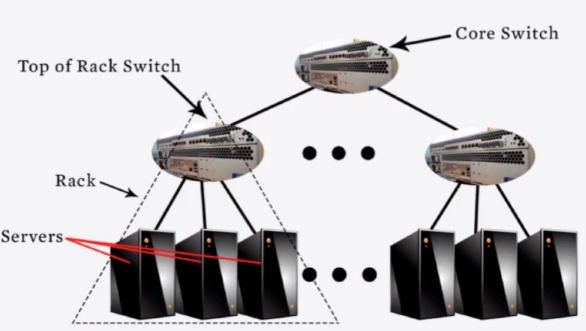
1.3 : Intro to Clouds: History
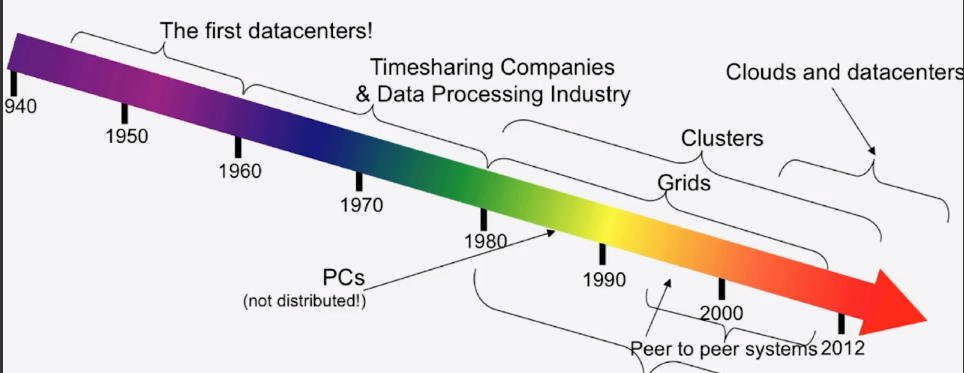
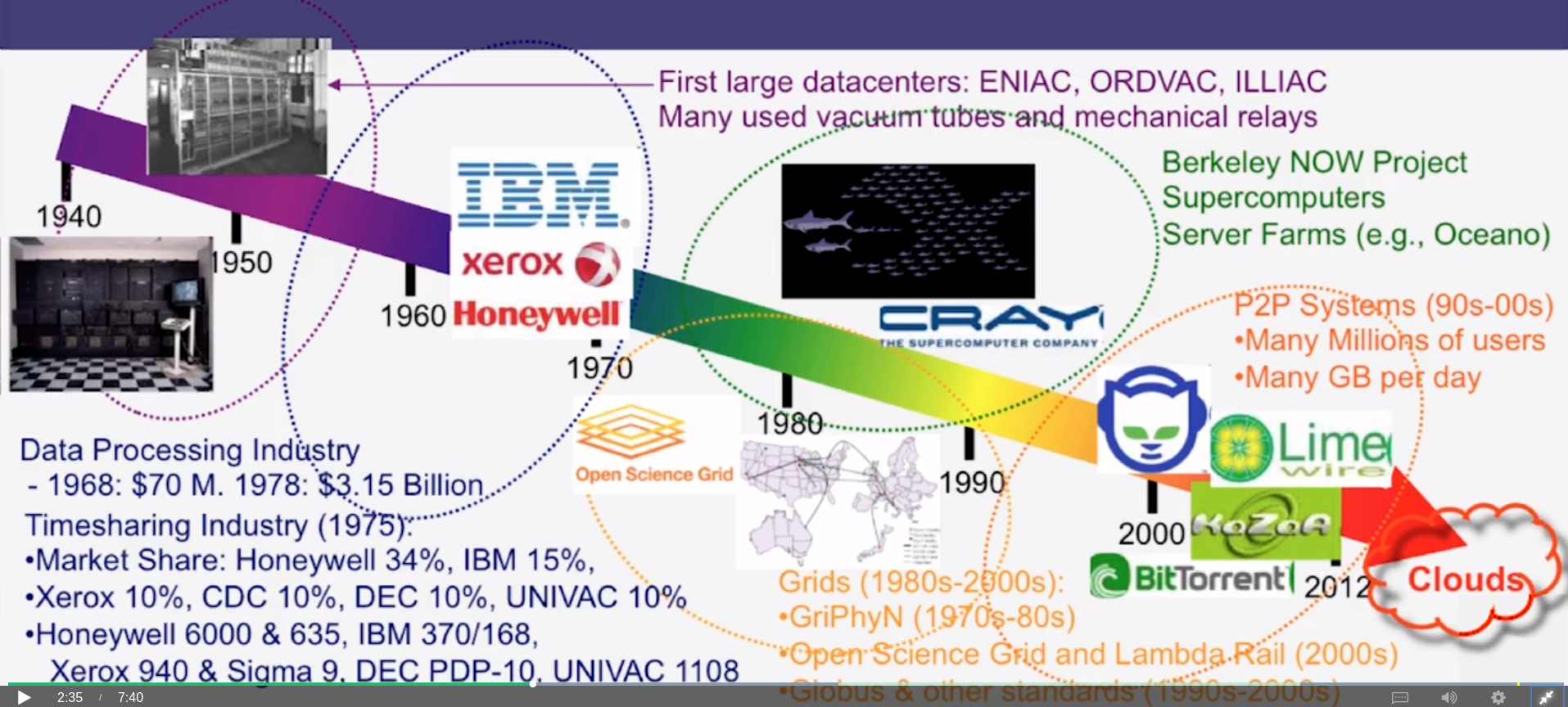
1.4 : Intro to Clouds: What’s New in Today’s Clouds
- Massive Scale
- On-demand access (pay as you go, anybody!)
- Data-intensive Nature
- New Cloud Programming Paradigms (MapReduce/Hadoop, NoSQL/Cassandra/MongoDB, etc)
- WUE = Annual water usage / IT equipment energy (L/kWh)
- PUE = Total Facility Power /IT Equipment Power
- A datacenter consumes 2 MW of power, and out of this only 1.5 MW is used for the computing equipment. What is the PUE of this datacenter?
- 1.33
2.2 : What is a Distributed System?
- Cloud is one form of a distributed system
- Course Definition: A distributed system is a collection of entities(processes), each of which is autonomous, programmable, asynchronous (not working at same time, ie not parallel systems) and failure-prone, and which communicate through an unreliable communication medium.
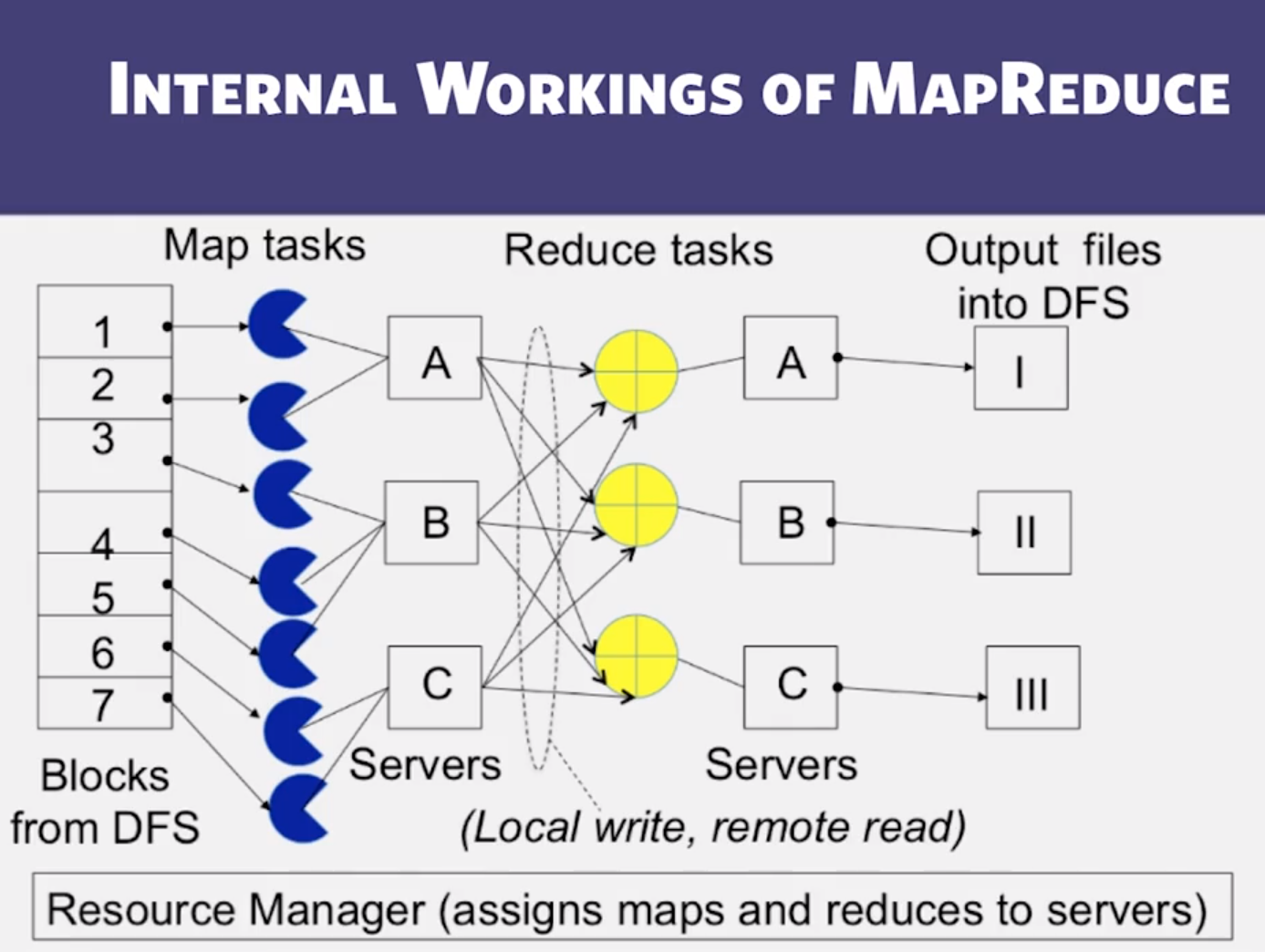
3.1 : MapReduce Paradigm
- comes from functional programming’s map and reduce
- Use hashing to evenly distribute reduce tasks among workers
- The primary difference between Map and Reduce is that Reduces process batches of values associated with the same key while Maps process keys independently.
- A given Mapreduce program has the Map phase generate 100 key-value pairs with 10 unique keys. How many Reduce tasks can this program have when at least one Reduce task will certainly be assigned no keys when a hash partitioner is used (select all answers that are correct)?”
- Between 11 and 101.
3.2 : MapReduce Examples
- There are three advantages of Maps and Reduces sorting their outputs:
- A Map can know which contiguous sets of its key-value pairs (sharing the same key) need to be sent to one Reduce
- A Reduce task can call the Reduce function on a contiguous set of key-value pairs (sharing the same key)
- Sorting as an application becomes very simple to write
3.3 : MapReduce Scheduling
- Ensure no reduce tasks start before the map tasks all finish
- Someone writes a variant of Mapreduce without a barrier, i.e., where Reduces can start before all Maps are done computing. Which of the following are TRUE statements?
- A Mapreduce run may be incorrect since some of the key-value pairs generated by Maps may never be processed by a Reduce if the reduce function is called exactly once per key
- All Mapreduce runs could be correct if Reduces maintain partial results for keys, and update these as new key-value pairs come in


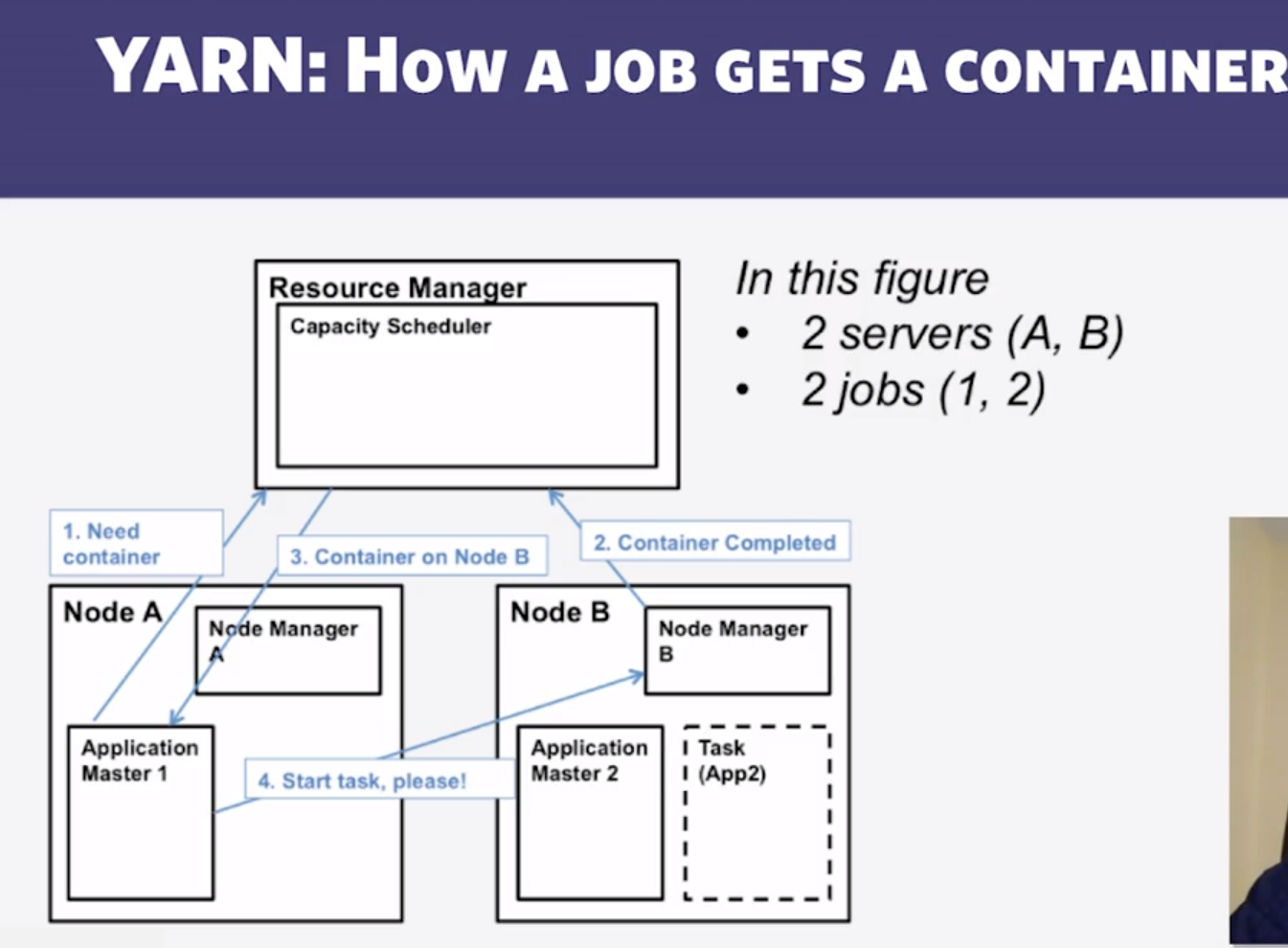
- FIFO task management.
- In YARN, which of the following is dedicated to one job?
- Application Master
3.4 : MapReduce Fault-Tolerance

- Speculative execution refers to (Replicative Execution is a better term, the point is to observe tasks, and if one is going super slow, replicate the task on other threads and whichever replica finishes first completes the task):
- Replicating slow tasks so that the first copy that finishes, completes the task
CS 427 : Software Engineering
Goals and Objectives
- Explain differences between programming and software engineering.
- Explain main goals of software engineering.
- Explain main subareas of software engineering.
Video Lecture Notes
1.1 : Origins of Software Engineering
- programming (single worker) vs software engineering (team of workers)
1.2 : Software
- Malleable
- Complex
- Useful
- Varies
1.3 : Software Project
- Development Process (Productivity)
- Software System (quality)
- Software Users (Experience)
1.4 : Software Engineer
- In real world, customer/user requirements for a software are ambiguous, constantly changing