CS 410 : Text Information Systems
Goals and Objectives
After you actively engage in the learning experiences in this module, you should be able to:
- Explain some basic concepts in natural language processing, text information access.
- Explain why text retrieval is often defined as a ranking problem.
- Explain the basic idea of the vector space retrieval model and how to instantiate it with the simplest bit-vector representation.
Guiding Questions
Develop your answers to the following guiding questions while watching the video lectures throughout the week.
- What does a computer have to do in order to understand a natural language sentence?
- What is ambiguity?
- What is bag-of-words representation? Why do modern search engines use this simple representation of text?
- What are the two modes of text information access? Which mode does a web search engine such as Google support?
- When is browsing more useful than querying to help a user find relevant information?
- Why is a text retrieval task defined as a ranking task?
- What is a retrieval model?
- What are the two assumptions made by the Probability Ranking Principle?
- What is the Vector Space Retrieval Model? How does it work?
- How do we define the dimensions of the Vector Space Model? What does “bag of words” representation mean?
- What does the retrieval function intuitively capture when we instantiate a vector space model with bag of words representation and bit representation for documents and queries?
Key Phrases and Concepts
Keep your eyes open for the following key terms or phrases as you complete the readings and interact with the lectures. These topics will help you better understand the content in this module.
- Part of speech tagging, syntactic analysis, semantic analysis, and ambiguity
- “Bag of words” representation
- Push, pull, querying, browsing
- Probability ranking principle
- Relevance
- Vector space model
- Dot product
- Bag of words representation
- Bit vector representation
Video Lecture Notes
1.1 Natural Language Content Analysis
- NLP: Natural Language Processing
- Semantic Analysis
- In general, what we find as easy to read and understand is hard and complex for computers.
- What we can’t do:
- 100% Part-Of-Speech (POS) tagging
- “He turned off the highway.” vs “He turned off his fan.”
- General complete parsing
- “A man saw a boy with telescope.”
- Precise deep semantic analysis
- Will we ever be able to precisely define the meaning of “own’ in “John owns a restaurant.” ?
- Will we ever be able to precisely define the meaning of “own’ in “John owns a restaurant.” ?
- 100% Part-Of-Speech (POS) tagging
- Robust and general NLP tends to be “shallow” while “deep” understanding doesn’t scale up. (ie, program will only work in conditions they are designed for, will not work in general unrestricted situations).
- This implies NLP for text retrieval must be generally robust and efficient, shallow NLP at best.
- “Bag of words” representation (google search) tends to be sufficient for most search tasks (but not all!)
- words given together often aligns with their intended meanings, obviating the need for more sophisticated algorithms.
- Some text retrieval techniques can naturally address NLP problems
- However, deeper NLP is needed for complex search tasks.
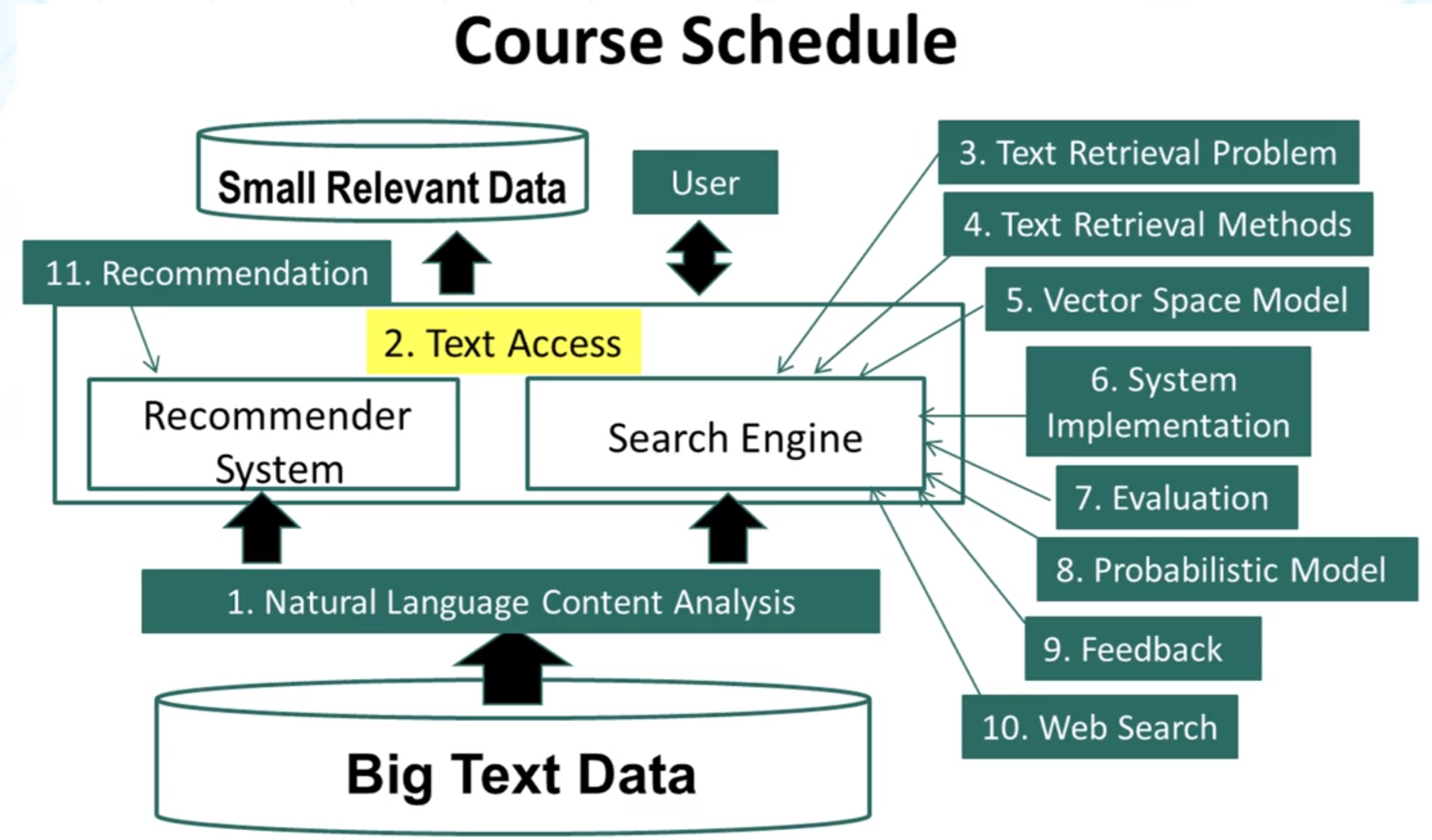
1.2 Text Access (high level)
Slide 1
- How can a text information system help useres get access to the relevant text data?
- push vs pull
- querying vs browing
Slide 2
- Pull mode (search engines)
- users take initiative
- Ad hoc (temporary) information need
- Push Mode (recommender systems, newsfeeds)
- systems take initiative
- stable information need (ie, consistent) or system has good knowledge about a user’s need.
Slide 3: Pull Mode - Querying vs Browsing.
- Querying
- User enters a (keyword) query
- System returns relevant documents
- Works well when the user knows what keywords to use
- Browsing
- User navigates into relevant information by following a path enabled by the structures on the documents
- works well when the user wants to explore information, doesn’t know what keywords to use, or can’t conveniently enter a query.
Slide 4: Information seeking as sightseeing (An analogy)
- Sightseeing: Know address of an attraction?
- Yes: take a taxi and go directly to the site.
- No: walk around or take a taxi to a nearby place then walk.
- Information seeking: Know exactly what you want to find?
- Yes: use the right keywords as a query and find the information directly.
- No: browse the information space or start with a rough query and then browse.
- Need topic map to effectively browse when information seeking, many interesting applications regarding this…
Slide 5:
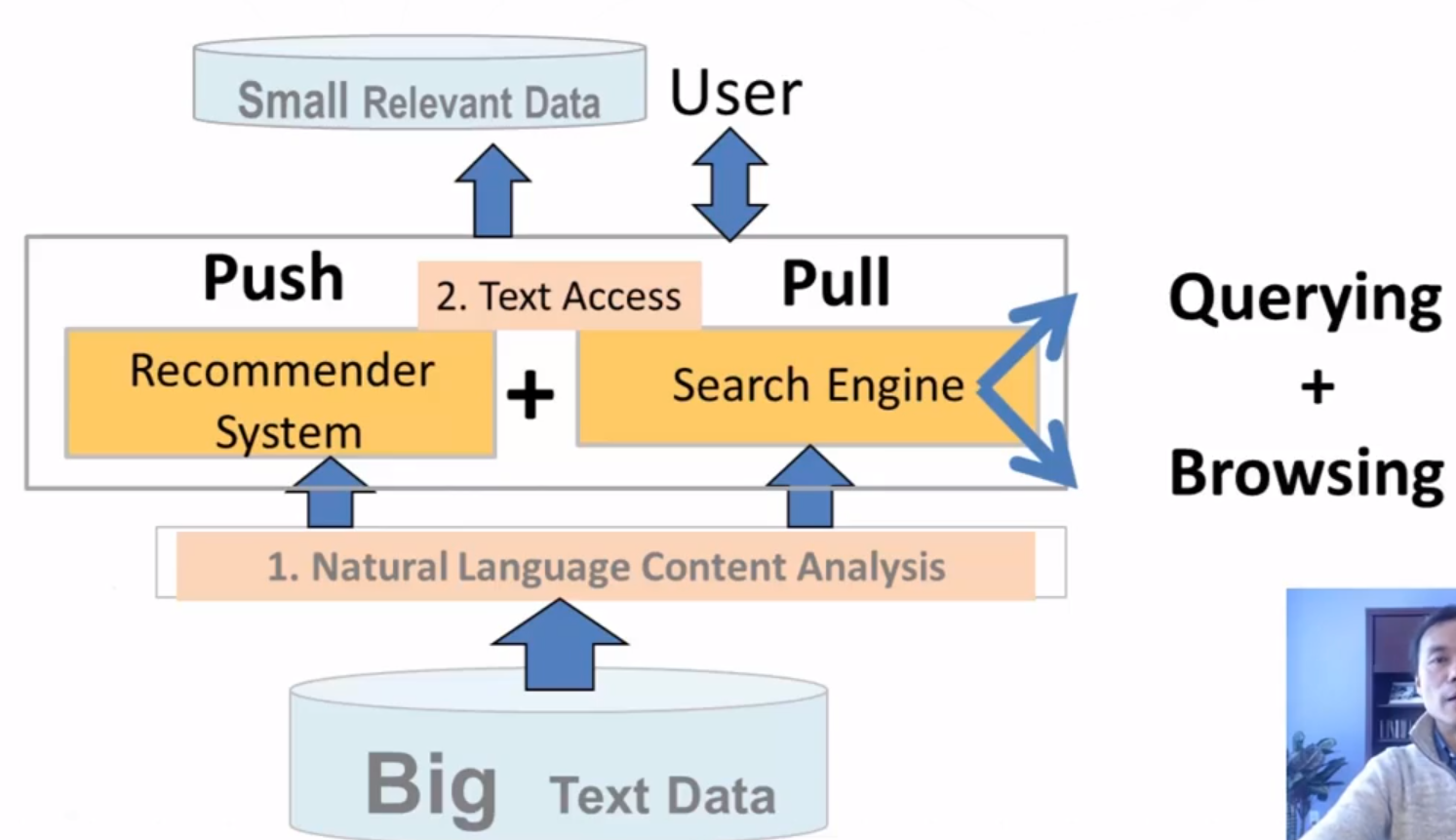
- Generally combine both push (sometimes referred to as “filtering”) and pull as well as Browsing and Querying to better serve users
1.3: Text Retrieval Problem (supporting pull method)
Slide 3: What is Text Retrieval (TR) ?
- Collection of text documents exists
- User gives a query to express the information need
- Search engine system returns relevant documents to users
- Often called “information retrieval” (IR), but IR is actually much broader (there are others aside from “text”, such as images and audio)
- known as “search technology’ in industry.
Slide 4: TR vs Database Retrieval
- Information
- Unstructured/free text vs structured data
- ambiguous vs well-defined semantics
- Query
- Ambiguous vs well-defined semantics
- incomplete vs complete specification
- Answers
- relevant documents vs matched records
- TR is an empirically defined problem
- can’t mathematically prove one method is better than another
- must rely on empirical evaluation involving users!
Slide 5: Formal Formulation of TR
- Vocabulary (set of words in a language): V
- query (sequence of words provided by user): q
- document (sequence of words provided by document) di
- collection (of documents): C
- Set of relevant documents: R(q) is a subset of C
- generally unknown and user-dependent
- query is a “hint” on which doc is in R(q)
- Task = compute R’(q), an approximation of R(q)
Slide 6: How to compute R’(q)
- Strat 1: Document selection
- R’(q) = set of documents in C for which f(d, q) = 1 where f(d, q) is either 0 (fail) or 1 (success).
- System must decide if a doc is relevant or not (absolute relevance)
- Strat 2: Document Ranking
- R’(q) = set of documents in C for which f(d, q) > Θ where f(d, q) is a relevance measure function, Θ is a cutoff determined by the user
- System only needs to decide if one doc is more likely relevant than another (relative relevance)
Slide 8: Problems of Document Selection (ranking is usually preferred)
- The classifier is unlikely accurate
- “Over-constrained” query results in no relevant documents to return
- “under-constrained” query results in over delivery.
- Hard to find the right position between these two extremes.
- Even if it is accurate, all relevant documents are not equally relevant (relevance is a matter of degree!)
- Prioritization is needed.
Slide 9: Theoretical Justification for Ranking
- Probability Ranking Principle [Robertson 77]: Returning a ranked list of documents in descending order of probability that a document is relevant to the query is the optimal strategy under the following two assumptions:
- The utility of a document (to a user) is independent of the utility of any other document.
- A user would browse the results sequentially
- Do these two assumptions hold?
- Neither are necessarily true, but forms a solid foundation for ranking as the primary method.
1.4: Overview of Text Retrieval Methods
Slide 3 : How to design a Ranking Function
- Query: q
- Document: d
- Ranking function: f(d, q) in R
- A good ranking function should rank relevant documents on top of non-relevant ones.
- Key challenge: how to measure the likelihood that document d is relevant to query q
- Retrieval model = formalization of relevance (give a computational definition of relevance).
Slide 4 : Many different Retrieval Models
- Similarity-based models: f(q, d) = similarity(q,d)
- vector space model
-
Probabilistic models: f(d, q) = p(R=1 d,q), where R is 0 or 1. - Classic probabilistic model
- Language model
- Divergence-from-randomness model
- Probabilistic inference model:f(q, d) = p(d implies q)
- Axiomatic Model: f(q, d) must satisfy a set of constraints.
- These different models tend to result in similar ranking functions involving similar variables.
Slide 5 : Common Ideas in State of the Art Retrieval Models

Slide 6 : Which Model Works the Best?
- When optimized, the following models tend to perform equally well [Fang eg al 11]:
- Pivoted length normalization
- BM25
- Query Likelihood
- PL2
- BM25 is most popular
1.5 : Vector Space Model - Basic Idea
Slide 3 : Many different Retrieval Models
- Similarity-based models: f(q,d) = similarity(q,d)
- Vector space model
Slide 5: VSM is a framework
- Represent a doc/query by a term vector
- Term: basic concept, eg word or phrase
- Each term defines one dimension
- N terms define an N-dimensional space
- Query vector: q=(x,…) is query term weight
- Doc vector: d=(y,…) is doc term weight
- relevance(q,d) is proportional to similarity(q,d) = f(q,d)
Slide 6: What VSM doesn’t say
- How to define/select the “basic concept”
- concepts are assumed to be orthogonal
- How to place docs and query in the space (= how to assign term weights)
- Term weight in query indicates importance of term
- Term weight in doc indicates how well the term characterizes the doc
- How to define the similarity measure? (topic of next lecture)
1.6 : Vector Space Retrieval Model - Simplest Instantiation
Slide 7:

This only measures how many query words are in the document words, it provides nothing on semantic relevance nor repeated words.
CS 425 : Distributed Systems
No new content was presented this week.
CS 427 : Software Engineering
No new (relevant) content was presented this week.